
پروژه تلهمتری معنایی هدف دارد تا با استفاده از یک رویکرد جدید علم داده، درک بهتری از تعاملات پیچیده و نوبتی انسان و هوش مصنوعی (AI) در Microsoft Copilot به دست آورد.
این درک برای تشخیص چگونگی استفاده افراد از سیستمهای هوش مصنوعی برای رسیدگی به وظایف دنیای واقعی بسیار حیاتی است. این امر بینشهای عملی ارائه میدهد، موارد استفاده کلیدی را افزایش میدهد و فرصتهایی را برای بهبود سیستم شناسایی میکند.
در یک پست وبلاگ اخیر، ما رویکرد خود را برای طبقهبندی دادههای گزارش گفتگو با استفاده از مدلهای زبان بزرگ (LLM) به اشتراک گذاشتیم که به ما امکان میدهد این تعاملات را در مقیاس بزرگ و تقریباً در زمان واقعی تجزیه و تحلیل کنیم. ما همچنین دو طبقهبندیکننده تولید شده توسط LLM خود را معرفی کردیم: موضوعات و پیچیدگی وظیفه.
این پست وبلاگ بررسی خواهد کرد که چگونه مجموعه طبقهبندیکنندههای تولید شده توسط LLM ما میتوانند به عنوان نشانگرهای اولیه برای تعامل کاربر عمل کنند و نشان میدهند که چگونه استفاده و رضایت بر اساس تخصص هوش مصنوعی و کاربر متفاوت است.
یافتههای کلیدی از تحقیق ما عبارتند از:
- هنگامی که کاربران در وظایف حرفهای، فنی و پیچیدهتر شرکت میکنند، احتمال بیشتری دارد که به استفاده از ابزار ادامه دهند و سطح تعامل خود را با آن افزایش دهند.
- کاربران مبتدی در حال حاضر در وظایف سادهتری شرکت میکنند، اما کار آنها به تدریج در طول زمان پیچیدهتر میشود.
- کاربران متخصصتر تنها زمانی از پاسخهای هوش مصنوعی راضی هستند که تخصص هوش مصنوعی با تخصص خودشان در مورد موضوع برابر باشد، در حالی که کاربران مبتدی صرف نظر از تخصص هوش مصنوعی، نرخ رضایت پایینی داشتند.
برای اطلاعات بیشتر در مورد این یافتهها، ادامه مطلب را بخوانید. توجه داشته باشید که تمام تجزیه و تحلیلها بر روی تعاملات ناشناس Copilot در Bing انجام شده است که حاوی هیچ اطلاعات شخصی نیست.
طبقهبندیکنندههای ذکر شده در مقاله:
طبقهبندیکننده کار دانش: وظایفی که شامل ایجاد مصنوعات مرتبط با کار اطلاعاتی است که معمولاً نیاز به تفکر خلاقانه و تحلیلی دارد. مثالها عبارتند از برنامهریزی استراتژیک کسبوکار، طراحی نرمافزار و تحقیقات علمی.
طبقهبندیکننده پیچیدگی وظیفه: پیچیدگی شناختی یک وظیفه را ارزیابی میکند اگر کاربر آن را بدون استفاده از هوش مصنوعی انجام دهد. ما به دو دسته تقسیم میکنیم: پیچیدگی کم و پیچیدگی بالا.
طبقهبندیکننده موضوعات: یک برچسب واحد برای موضوع اصلی مکالمه.
تخصص کاربر: تخصص کاربر را در مورد موضوع اصلی در مکالمه به عنوان یکی از دستههای زیر برچسبگذاری میکند: مبتدی (بدون آشنایی با موضوع)، تازهکار (دانش یا تجربه قبلی کم)، متوسط (برخی دانش یا آشنایی اولیه با موضوع)، ماهر (میتواند مفاهیم مرتبط را از مکالمه اعمال کند) و متخصص (درک عمیق و جامع از موضوع).
تخصص هوش مصنوعی: تخصص عامل هوش مصنوعی را بر اساس همان معیارهای تخصص کاربر در بالا برچسبگذاری میکند.
رضایت کاربر: یک روبیری رضایت/نارضایتی 20 سوالی که LLM برای ایجاد یک امتیاز کلی برای رضایت کلی کاربر ارزیابی میکند.
چه چیزی کاربران Bing Chat را درگیر نگه میدارد؟
ما یک مطالعه بر روی یک نمونه تصادفی از 45000 کاربر ناشناس Bing Chat در طول ماه می 2024 انجام دادیم. دادهها بر اساس فعالیت کاربر در طول ماه به سه گروه تقسیم شدند:
- سبک (1 جلسه چت فعال در هفته)
- متوسط (2-3 جلسه چت فعال در هفته)
- سنگین (4+ جلسه چت فعال در هفته)
یافته کلیدی این است که کاربران سنگین کار حرفهای و پیچیده بیشتری انجام میدهند.
ما از طبقهبندیکننده کار دانش خود برای برچسبگذاری دادههای گزارش چت به عنوان مربوط به وظایف کار دانش استفاده کردیم. چیزی که ما دریافتیم این است که وظایف کار دانش در همه گروهها بالاتر بود، با بالاترین درصد در کاربران سنگین.
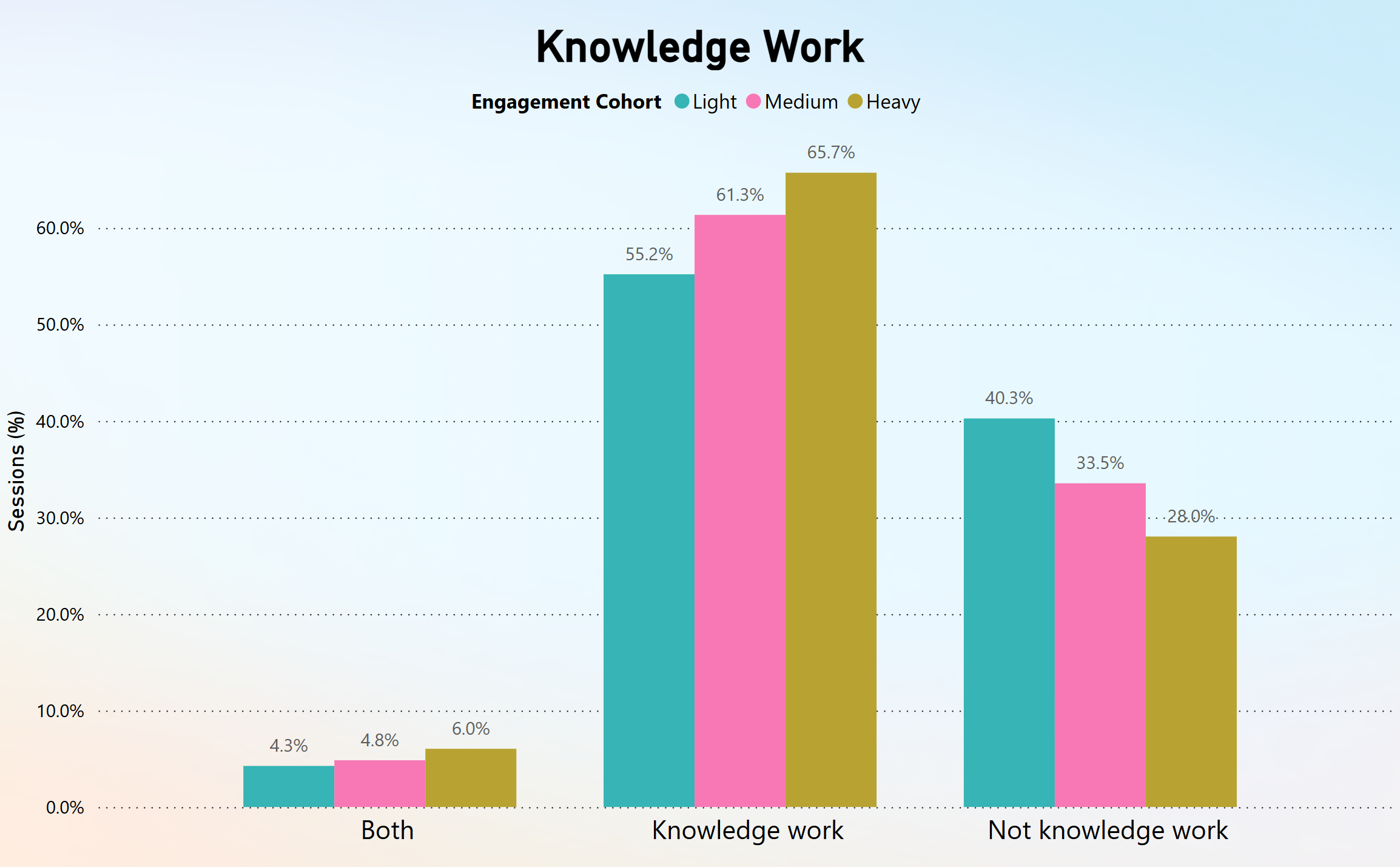
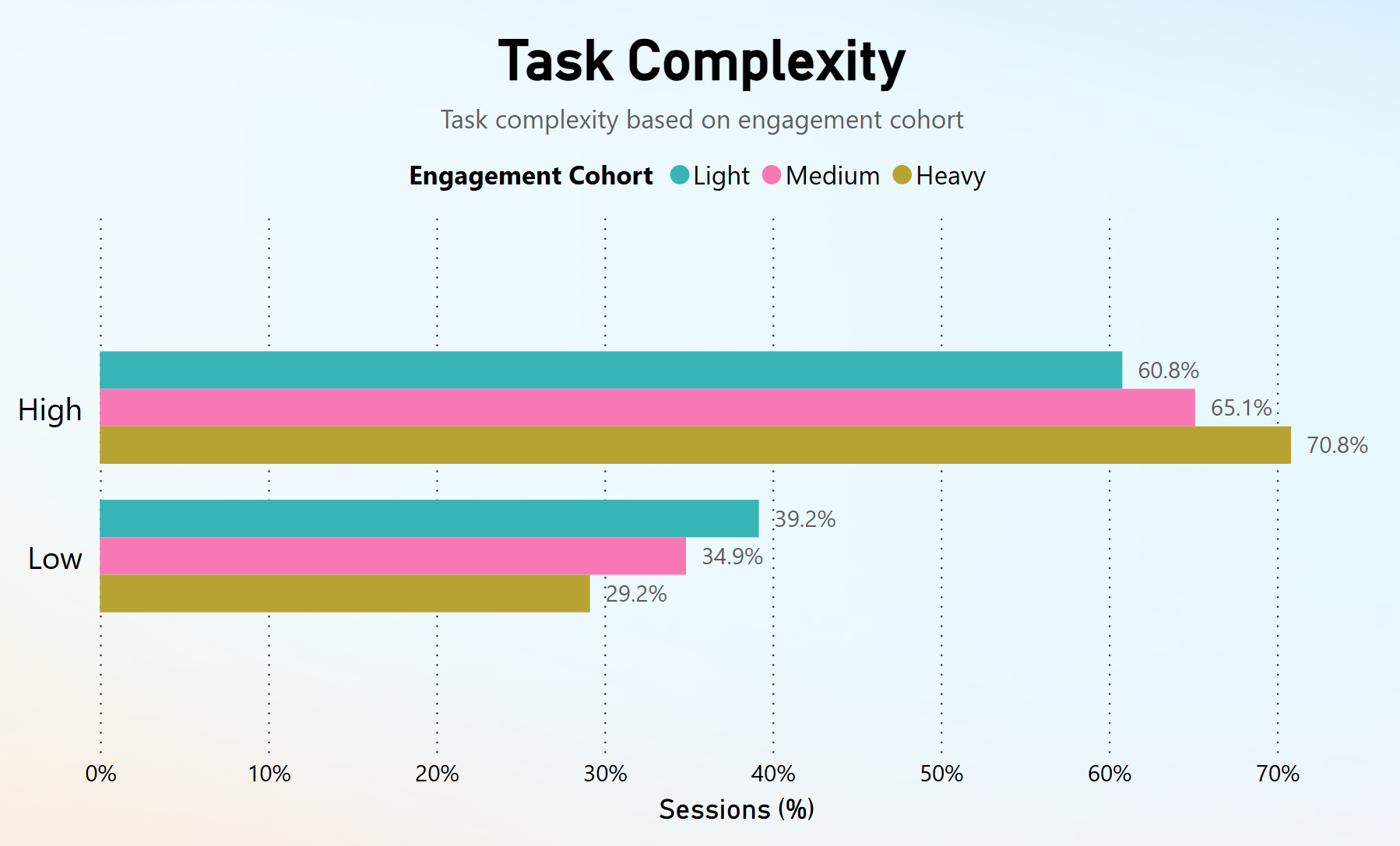
با تجزیه و تحلیل پیچیدگی وظیفه، مشاهده کردیم که کاربرانی با تعامل بالاتر اغلب بیشترین تعداد وظایف را با پیچیدگی بالا انجام میدهند، در حالی که کاربرانی با تعامل پایینتر وظایف بیشتری را با پیچیدگی کم انجام میدهند.
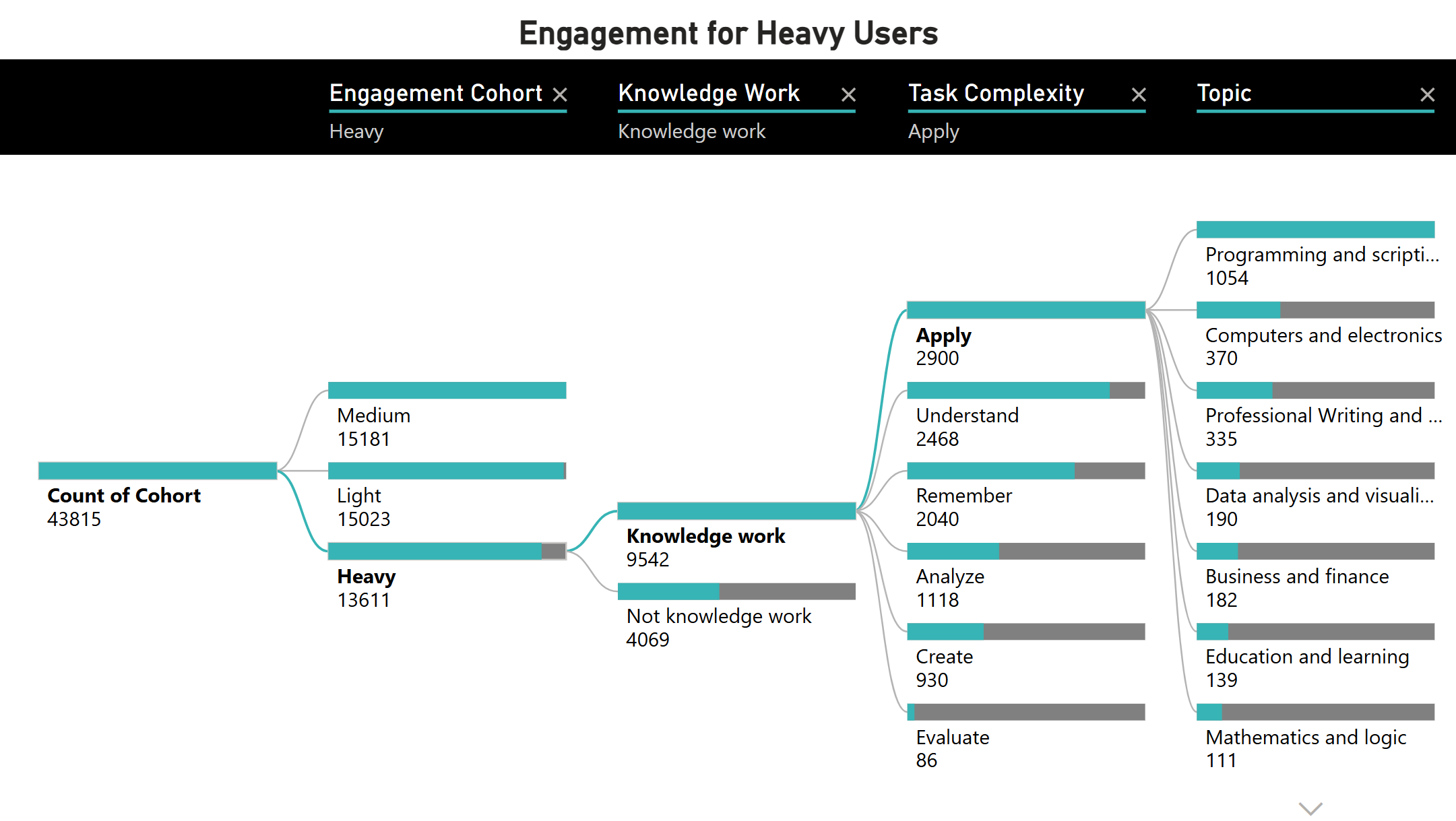
با نگاهی به دادههای کلی، میتوانیم بر روی کاربران سنگین فیلتر کنیم و تعداد بیشتری از چتها را ببینیم که در آن کاربر وظایف کار دانش را انجام میدهد. بر اساس پیچیدگی وظیفه، میبینیم که بیشتر وظایف کار دانش به دنبال اعمال یک راه حل برای یک مشکل موجود هستند، در درجه اول در برنامهنویسی و اسکریپتنویسی. این در راستای موضوع کلی برتر ما، فناوری است که در پست قبلی در مورد آن بحث کردیم.
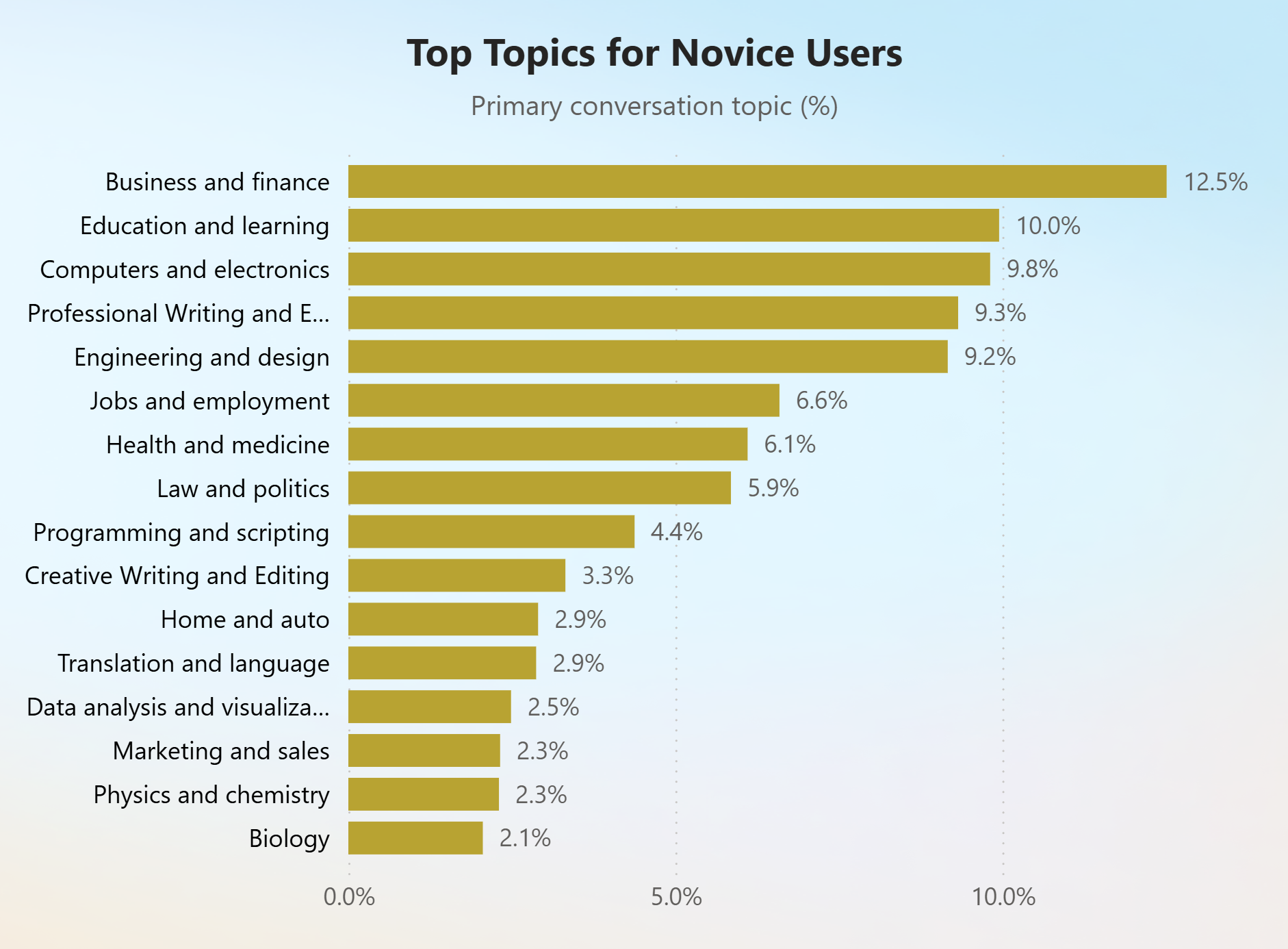
در مقابل، کاربران سبک تمایل داشتند وظایف با پیچیدگی کم بیشتری انجام دهند ("به خاطر سپردن")، با استفاده از Bing Chat مانند یک موتور جستجوی سنتی و مشارکت بیشتر در موضوعاتی مانند کسب و کار و امور مالی و کامپیوتر و الکترونیک.

پرس و جوهای مبتدیان در حال پیچیدهتر شدن هستند
ما به دادههای Bing Chat از ژانویه تا آگوست 2024 نگاه کردیم و چتها را با استفاده از طبقهبندیکننده تخصص کاربر خود طبقهبندی کردیم. هنگامی که به نحوه استفاده گروههای مختلف تخصص کاربر از این ابزار برای وظایف حرفهای نگاه کردیم، کشف کردیم که کاربران ماهر و متخصص تمایل دارند وظایف حرفهای بیشتری را با پیچیدگی بالا در موضوعاتی مانند برنامهنویسی و اسکریپتنویسی، نوشتن و ویرایش حرفهای و فیزیک و شیمی انجام دهند.
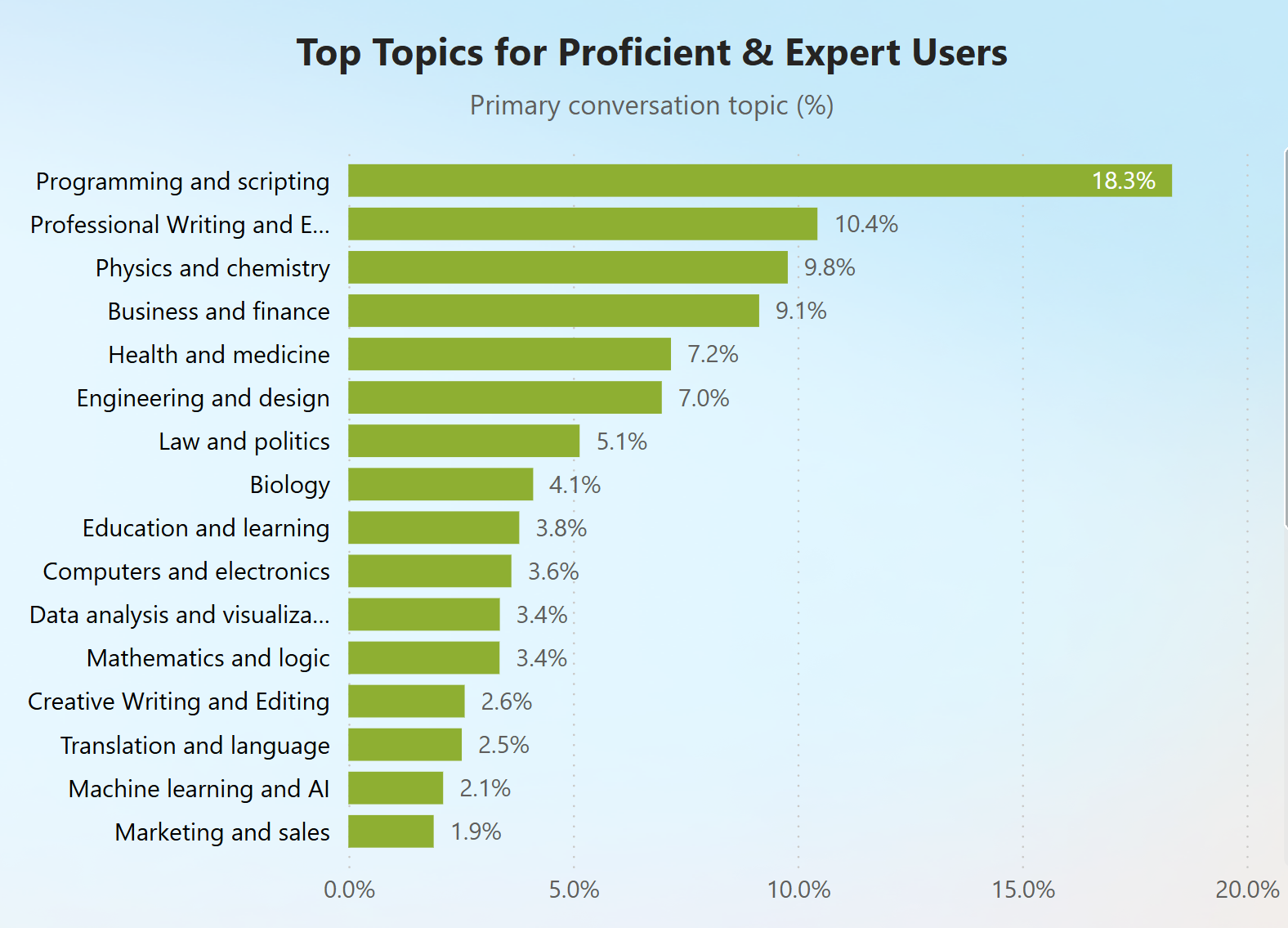
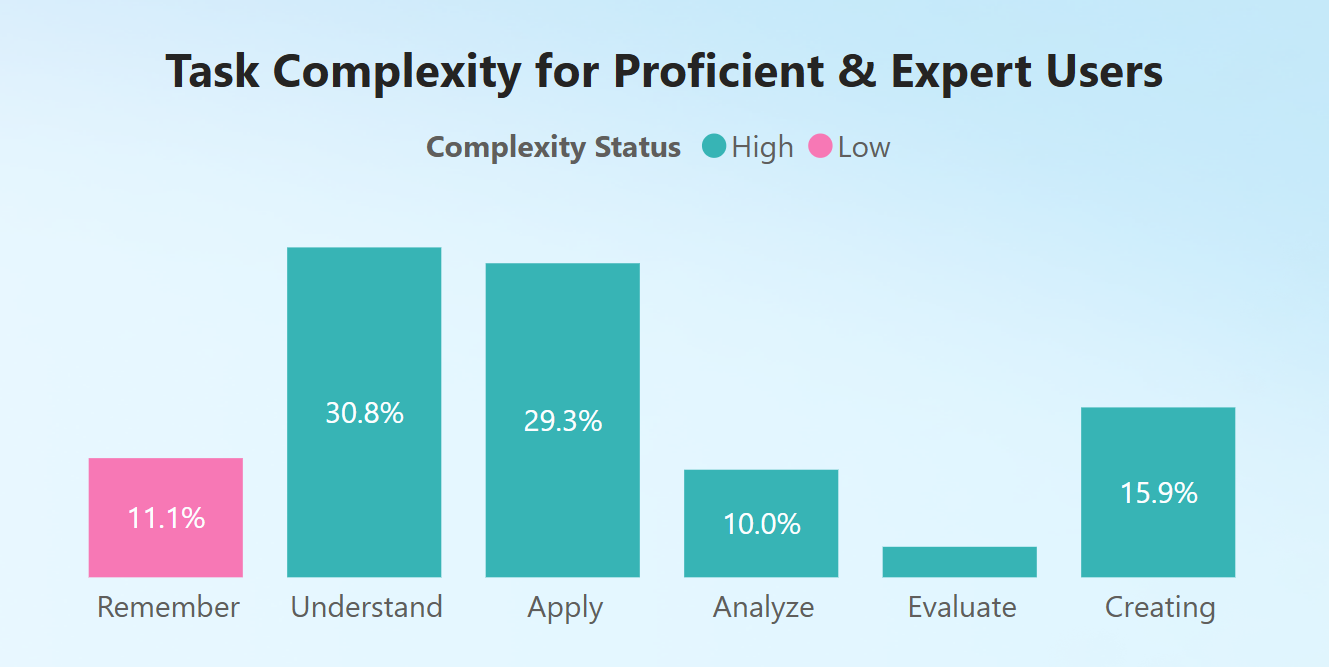
در مقابل، کاربران مبتدی بیشتر در وظایف حرفهای مربوط به کسب و کار و امور مالی و آموزش و یاد
گیری درگیر هستند.
با این حال، جالب است که کاربران مبتدی در طول زمان در وظایف پیچیدهتری شرکت میکنند. ما این را با بررسی نسبت وظایف پیچیده (برنامهریزی، ایجاد، ارزیابی) به وظایف ساده (به خاطر سپردن) در طول زمان تعیین کردیم.

این نشان میدهد که افراد با گذشت زمان دانش بیشتری در مورد ابزار پیدا میکنند و در سناریوهای حرفهای بیشتری از آن استفاده میکنند.
رضایت در رابطه با برابری تخصص
در نهایت، ما با در نظر گرفتن طبقهبندیکننده رضایت خود، نگاهی به چگونگی تأثیر تخصص هوش مصنوعی بر رضایت کاربر داشتیم. با در نظر گرفتن 20 روبیری مختلف، ما روبیری را ایجاد کردیم که به دنبال ارزیابی رضایت کاربر بود.
با بررسی میانگین رضایت بر اساس تطبیق تخصص کاربر و هوش مصنوعی، دریافتیم که رضایت بیشتر زمانی است که تخصص کاربر و هوش مصنوعی با هم برابر باشند. در واقع، کاربران متخصص در زمینهای که سیستم هوش مصنوعی دانش متوسطی در آن دارد، نسبت به یک کاربر مبتدیتر ناراضیتر هستند.

به طور کلی، کاربران مبتدی صرف نظر از امتیاز تخصص هوش مصنوعی، نرخ رضایت پایینی داشتند. این ممکن است نشان دهد که آنها نتایج خوبی دریافت نمیکنند، یا فقط به یک ابزار آموزش نیاز دارند که Bing Chat نمیتواند در حال حاضر ارائه دهد.
مراحل بعدی
طبقهبندیکنندههای LLM که در اینجا مورد بحث قرار گرفتند، تأثیرات بسیار زیادی بر درک تعاملات کاربر در Bing Chat دارند. ما امیدواریم که این اطلاعات را به عنوان یک نمای کلی به اشتراک بگذاریم، زیرا این کار میتواند پایهای برای انجام کارهای ارزشمند با این اطلاعات باشد.
به عنوان یک قدم بعدی، ما مشتاقانه منتظر کاوش در چگونگی استفاده از دادهها در سطح دانه هستیم:
- ارزیابی کنید که آیا میتوانیم بازخوردهای در نظر گرفته شده را برای چتها ترکیب کنیم و اینکه چگونه یک خط لوله کاملتری برای نظارت و ارزیابی رضایت ایجاد کنیم
- راههایی را بررسی کنید که در آن میتوانیم به افراد با تخصص مختلف بهترین تجربه را بدهیم، به عنوان مثال با هدفگیری متفاوت پاسخهای هوش مصنوعی بر اساس تطبیق تخصص
به طور کلی، ما مشتاقانه منتظر انتشار بیشتر بینشهایی هستیم که LLM میتوانند به ما ارائه دهند، و اینکه این بینشها چگونه میتوانند به ارائه بهترین محصول هوش مصنوعی در کلاس کمک کنند.