توسعهی مداوم ابزارهای کدنویسی مبتنی بر هوش مصنوعی، نه تنها کارایی توسعهدهندگان را افزایش میدهد، بلکه نشاندهندهی آیندهای است که در آن هوش مصنوعی سهم رو به رشدی از تمام کدهای جدید را تولید خواهد کرد. توماس دومکه (Thomas Dohmke)، مدیرعامل GitHub، در سال ۲۰۲۳ پیشبینی کرد که «دیر یا زود، ۸۰ درصد کدها توسط Copilot نوشته خواهند شد.»
شرکتهای نرمافزاری بزرگ و کوچک در حال حاضر به شدت از هوش مصنوعی برای تولید کد استفاده میکنند. گری تان (Garry Tan) از Y Combinator خاطرنشان کرد که ۹۵ درصد کد برای یک چهارم آخرین دسته از استارتآپهای Y Combinator توسط مدلهای زبانی بزرگ نوشته شده است.
در واقع، اکثر توسعهدهندگان بیشتر وقت خود را صرف اشکالزدایی کد میکنند، نه نوشتن آن. به عنوان نگهدارندگان مخازن محبوب متنباز، این موضوع برای ما ملموس است. اما اگر یک ابزار هوش مصنوعی بتواند اصلاحاتی را برای صدها مسئلهی باز پیشنهاد دهد، و تنها کاری که ما باید انجام دهیم این باشد که قبل از ادغام آنها را تأیید کنیم چه؟ این انگیزه ما را برای به حداکثر رساندن پتانسیل صرفهجویی در زمان از ابزارهای کدنویسی هوش مصنوعی با آموزش آنها برای اشکالزدایی کد ایجاد کرد.
منظور ما از اشکالزدایی، فرآیند تعاملی و تکراری برای رفع کد است. توسعهدهندگان معمولاً فرضیهای را مطرح میکنند که چرا کدشان خراب شده است، سپس با گام برداشتن در برنامه و بررسی مقادیر متغیرها، شواهدی را جمعآوری میکنند. آنها اغلب از ابزارهای اشکالزدایی مانند pdb (اشکالزدای پایتون) برای کمک به جمعآوری اطلاعات استفاده میکنند. این فرآیند تا زمان رفع کد تکرار میشود.
ابزارهای کدنویسی هوش مصنوعی امروزی بهرهوری را افزایش میدهند و در پیشنهاد راهحلهایی برای اشکالات بر اساس کد و پیامهای خطای موجود، عالی عمل میکنند. با این حال، برخلاف توسعهدهندگان انسانی، این ابزارها هنگام شکست راهحلها به دنبال اطلاعات اضافی نیستند و برخی از اشکالات را بدون رسیدگی رها میکنند، همانطور که میتوانید در این دموی ساده از اینکه چگونه یک ستون با برچسب اشتباه، ابزارهای کدنویسی امروزی را گیج میکند، ببینید. این ممکن است به کاربران این احساس را بدهد که ابزارهای کدنویسی هوش مصنوعی زمینه کامل مسائلی را که در تلاش برای حل آنها هستند، درک نمیکنند.
معرفی debug-gym
یک سوال تحقیقاتی طبیعی مطرح میشود: مدلهای زبانی بزرگ (LLM) تا چه حد میتوانند از ابزارهای اشکالزدایی تعاملی مانند pdb استفاده کنند؟ برای بررسی این سوال، ما debug-gym را منتشر کردیم - محیطی که به عوامل تعمیر کد اجازه میدهد به ابزارهایی برای رفتار فعال جستجوی اطلاعات دسترسی داشته باشند. Debug-gym فضای عمل و مشاهده یک عامل را با بازخورد ناشی از استفاده از ابزار گسترش میدهد و امکان تنظیم نقاط شکست، پیمایش کد، چاپ مقادیر متغیرها و ایجاد توابع تست را فراهم میکند. عوامل میتوانند برای بررسی کد یا بازنویسی آن، در صورت اطمینان، با ابزارها تعامل داشته باشند. ما معتقدیم که اشکالزدایی تعاملی با ابزارهای مناسب میتواند عوامل کدنویسی را برای مقابله با وظایف مهندسی نرمافزار دنیای واقعی توانمند سازد و برای تحقیقات مبتنی بر LLM بسیار مهم است. اصلاحات پیشنهادی توسط یک عامل کدنویسی با قابلیتهای اشکالزدایی، و سپس تأیید شده توسط یک برنامهنویس انسانی، در زمینه کدبیس مربوطه، اجرای برنامه و مستندات، ریشه خواهد داشت، نه اینکه صرفاً بر حدسهایی بر اساس دادههای آموزشی قبلی تکیه کند.
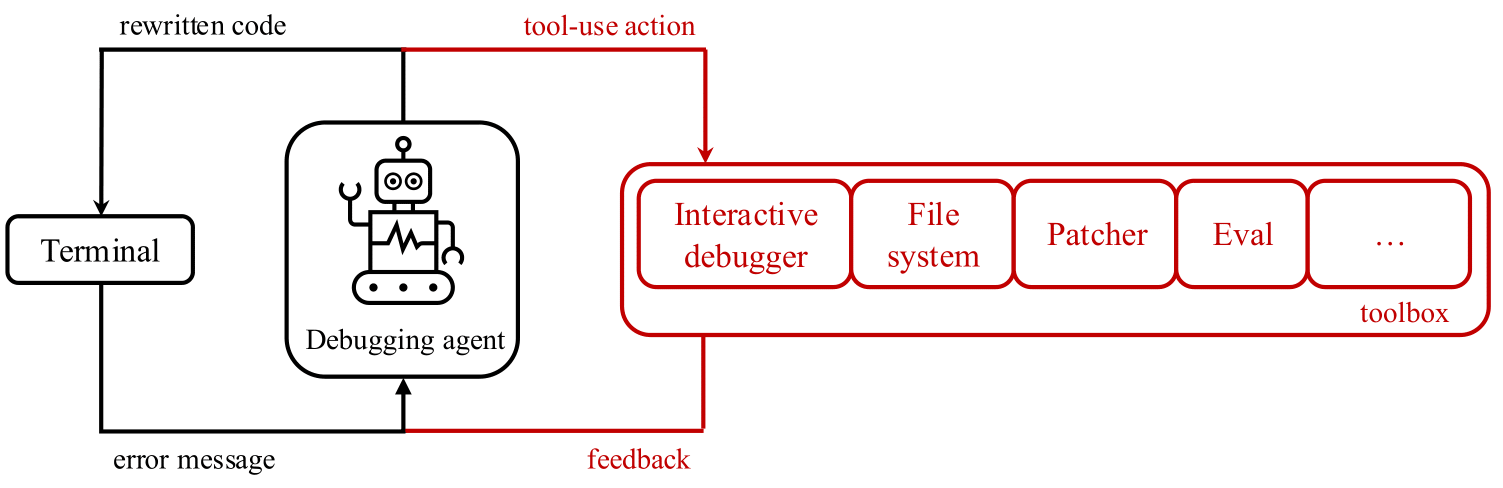
Debug-gym برای موارد زیر طراحی و توسعه داده شده است:
- مدیریت اطلاعات در سطح مخزن: کل مخزن در debug-gym در دسترس عوامل است و به آنها اجازه میدهد فایلها را پیمایش و ویرایش کنند.
- ایمن و قوی باشد: برای محافظت از سیستم و فرآیند توسعه، debug-gym کد را در کانتینرهای سندباکس Docker اجرا میکند. این محیط زمان اجرا را ایزوله میکند و از اقدامات مضر جلوگیری میکند و در عین حال امکان آزمایش و اشکالزدایی کامل را فراهم میکند.
- به راحتی قابل توسعه باشد: debug-gym با در نظر گرفتن قابلیت توسعه طراحی شده است و به متخصصان این امکان را میدهد تا به راحتی ابزارهای جدید اضافه کنند.
- مبتنی بر متن باشد: debug-gym اطلاعات مشاهده را در متن ساختاریافته (به عنوان مثال، فرمت JSON) نمایش میدهد و یک نحو ساده برای اقدامات متنی تعریف میکند، و محیط را کاملاً با عوامل مدرن مبتنی بر LLM سازگار میکند.
با debug-gym، محققان و توسعهدهندگان میتوانند یک مسیر پوشه را برای کار با هر مخزن سفارشی مشخص کنند تا عملکرد عامل اشکالزدایی خود را ارزیابی کنند. علاوه بر این، debug-gym شامل سه معیار کدنویسی برای اندازهگیری عملکرد عوامل مبتنی بر LLM در اشکالزدایی تعاملی است: Aider برای تولید کد ساده در سطح تابع، Mini-nightmare برای مثالهای کوتاه و دستساز از کد دارای اشکال، و SWE-bench برای مسائل کدنویسی دنیای واقعی که نیاز به درک جامع از یک کدبیس بزرگ و یک راهحل در قالب یک درخواست pull از GitHub دارد.
برای کسب اطلاعات بیشتر در مورد debug-gym و شروع به استفاده از آن برای آموزش عوامل اشکالزدایی خود، لطفاً به گزارش فنی و GitHub مراجعه کنید.
آزمایش اولیه: سیگنال امیدوارکننده
برای اولین تلاش خود برای تأیید اینکه LLMها در تستهای کدنویسی زمانی که به ابزارهای اشکالزدایی دسترسی دارند، عملکرد بهتری دارند، ما یک عامل ساده مبتنی بر prompt ساختیم و به آن دسترسی به ابزارهای اشکالزدایی زیر را دادیم: eval، view، pdb، rewrite و listdir. ما از نه LLM مختلف به عنوان پایه برای عامل خود استفاده کردیم. نتایج دقیق را میتوان در گزارش فنی یافت.
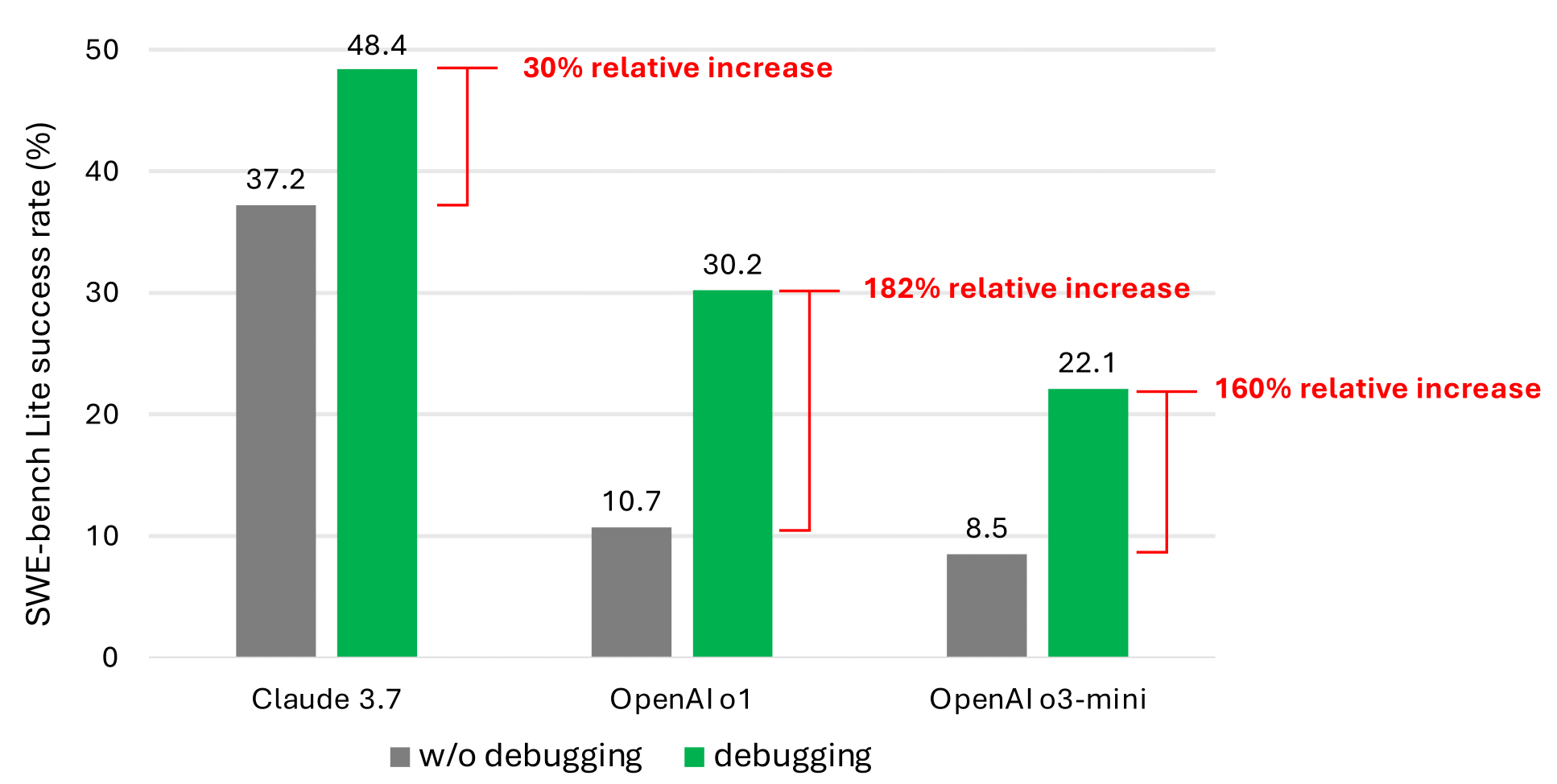
حتی با ابزارهای اشکالزدایی، عامل ساده مبتنی بر prompt ما به ندرت بیش از نیمی از مسائل SWE-bench Lite را حل میکند. ما معتقدیم که این به دلیل کمبود دادههایی است که رفتار تصمیمگیری متوالی (به عنوان مثال، ردیابیهای اشکالزدایی) را در مجموعه داده آموزشی LLM فعلی نشان میدهد. با این حال، بهبود عملکرد قابل توجه (همانطور که در امیدوارکنندهترین نتایج در نمودار زیر نشان داده شده است) تأیید میکند که این یک مسیر تحقیقاتی امیدوارکننده است.
کار آینده
ما معتقدیم که آموزش یا fine-tuning LLMها میتواند تواناییهای اشکالزدایی تعاملی آنها را افزایش دهد. این امر مستلزم دادههای تخصصی است، مانند دادههای trajectory که تعامل عوامل با یک اشکالزدا را برای جمعآوری اطلاعات قبل از پیشنهاد یک اصلاح ثبت میکند. برخلاف مسائل استدلال متعارف، اشکالزدایی تعاملی شامل تولید اقداماتی در هر مرحله است که باعث ایجاد بازخورد از محیط میشود. این بازخورد به عامل کمک میکند تا تصمیمات جدیدی بگیرد و به دادههای متراکم مانند شرح مسئله و توالی اقداماتی که منجر به راهحل میشود، نیاز دارد.
برنامه ما این است که یک مدل جستجوی اطلاعات را که در جمعآوری اطلاعات لازم برای رفع اشکالات تخصص دارد، fine-tune کنیم. هدف این است که از این مدل برای ایجاد فعالانه زمینه مرتبط برای یک مدل تولید کد استفاده کنیم. اگر مدل تولید کد بزرگ باشد، فرصتی برای ساخت یک مدل جستجوی اطلاعات کوچکتر وجود دارد که میتواند اطلاعات مرتبط را برای مدل بزرگتر ارائه دهد، به عنوان مثال، یک تعمیم از تولید تقویت شده بازیابی (RAG)، بنابراین در هزینههای استنتاج هوش مصنوعی صرفهجویی میشود. دادههای جمعآوری شده در طول حلقه یادگیری تقویتی برای آموزش مدل جستجوی اطلاعات نیز میتواند برای fine-tune کردن مدلهای بزرگتر برای اشکالزدایی تعاملی استفاده شود.
ما debug-gym را به صورت متنباز ارائه میدهیم تا این خط تحقیق را تسهیل کنیم. ما جامعه را تشویق میکنیم تا به ما کمک کند این تحقیق را به سمت ساخت عوامل اشکالزدایی تعاملی و به طور کلی، عواملی که میتوانند با تعامل با جهان بر اساس تقاضا به دنبال اطلاعات باشند، پیش ببریم.
تقدیر و تشکر
ما از Ruoyao Wang برای بحث روشنگرانه آنها در مورد ساخت عوامل اشکالزدایی تعاملی، Chris Templeman و Elaina Maffeo برای مربیگری تیم آنها، Jessica Mastronardi و Rich Ciapala برای حمایت مهربانانه آنها در مدیریت پروژه و تخصیص منابع، و Peter Jansen برای ارائه بازخورد ارزشمند برای گزارش فنی تشکر میکنیم.