در دو سال و نیمی که درباره حملات تزریق دستور صحبت کردهایم، پیشرفت بسیار کمی در جهت یک راه حل قوی دیدهام. مقاله جدید غلبه بر تزریق دستور از طریق طراحی از Google DeepMind بالاخره این روند را تغییر میدهد. این یکی ارزش توجه کردن دارد.
اگر با حملات تزریق دستور آشنایی ندارید، نسخه بسیار کوتاه آن این است: چه اتفاقی میافتد اگر شخصی به دستیار مبتنی بر مدل زبانی بزرگ (LLM) من (یا "ایجنت" اگر ترجیح میدهید) ایمیل بزند و به آن بگوید که همه ایمیلهای من را به یک شخص ثالث ارسال کند؟ در اینجا توضیح مفصلی وجود دارد که چرا جلوگیری از این موضوع به عنوان یک مسئله امنیتی متوقفکننده نمایش که رویای دستیاران دیجیتالی را که همه در تلاش برای ساخت آن هستند تهدید میکند، بسیار دشوار است.
اشتباه اصلی مدلهای زبانی بزرگ (LLM) که آنها را در برابر این آسیبپذیر میکند، زمانی است که دستورات مورد اعتماد از طرف کاربر و متن غیرقابل اعتماد از ایمیلها/صفحات وب/و غیره با هم در یک جریان توکن (Token Stream) ترکیب میشوند. من آن را "تزریق دستور" نامیدم زیرا همان الگوی نامناسب تزریق SQL است.
متاسفانه، هیچ راه قابل اعتمادی شناخته نشده است که یک مدل زبانی بزرگ (LLM) دستورالعملها را در یک دسته از متن دنبال کند و در عین حال آن دستورالعملها را به طور ایمن در دسته دیگری از متن اعمال کند.
اینجاست که CaMeL وارد میشود.
مقاله جدید DeepMind سیستمی به نام CaMeL (مخفف CApabilities for MachinE Learning به معنی قابلیتهایی برای یادگیری ماشین) را معرفی میکند. هدف CaMeL این است که یک دستور مانند "سند درخواستی باب را که در آخرین جلسه ما درخواست کرده بود برای او بفرست" را به طور ایمن بگیرد و آن را اجرا کند، با در نظر گرفتن این خطر که ممکن است دستورالعملهای مخربی در جایی در زمینه وجود داشته باشد که سعی در نادیده گرفتن قصد کاربر داشته باشد.
این سیستم با گرفتن یک دستور از کاربر، تبدیل آن به یک توالی از مراحل در یک زبان برنامهنویسی شبیه پایتون، و سپس بررسی ورودیها و خروجیهای هر مرحله برای اطمینان از اینکه دادههای درگیر فقط به مکانهای مناسب منتقل میشوند، کار میکند.
پرداختن به یک نقص در الگوی Dual-LLM من
اعتراف میکنم بخشی از دلیلی که من اینقدر در مورد این مقاله مثبت هستم این است که بر اساس برخی از کارهای خودم ساخته شده است!
در آوریل ۲۰۲۳، من الگوی Dual LLM را برای ساخت دستیارهای هوش مصنوعی که میتوانند در برابر تزریق دستور مقاومت کنند پیشنهاد کردم. من یک سیستم با دو مدل زبانی بزرگ (LLM) جداگانه را تئوریزه کردم: یک مدل زبانی بزرگ (LLM) ممتاز با دسترسی به ابزارهایی که دستورات کاربر به طور مستقیم از آن استفاده میکنند، و یک مدل زبانی بزرگ (LLM) قرنطینه شده که میتواند با آن تماس بگیرد که هیچ دسترسی به ابزار ندارد اما برای قرار گرفتن در معرض توکنهای بالقوه غیرقابل اعتماد طراحی شده است.
نکته مهم این است که در هیچ نقطهای محتوای مدیریت شده توسط مدل زبانی بزرگ (LLM) قرنطینه شده (Q-LLM) در معرض مدل زبانی بزرگ (LLM) ممتاز (P-LLM) قرار نمیگیرد. در عوض، مدل زبانی بزرگ (LLM) قرنطینه شده (Q-LLM) مراجعی را پر میکند—به عنوان مثال $email-summary-1—و مدل زبانی بزرگ (LLM) ممتاز (P-LLM) سپس میتواند بگوید "نمایش $email-summary-1 به کاربر" بدون اینکه در معرض آن توکنهای بالقوه مخرب قرار گیرد.
مقاله DeepMind در اوایل این کار به این موضوع اشاره میکند، و سپس نقص جدیدی را در طراحی من توصیف میکند:
یک گام مهم به جلو در استراتژیهای دفاعی، الگوی Dual LLM است که از نظر تئوری توسط ویلیسون (۲۰۲۳) توصیف شده است. این الگو از دو مدل زبانی بزرگ (LLM) استفاده میکند: یک مدل زبانی بزرگ (LLM) ممتاز و یک مدل زبانی بزرگ (LLM) قرنطینه شده. مدل زبانی بزرگ (LLM) ممتاز وظیفه دارد توالی اقدامات لازم برای برآوردن درخواست کاربر را برنامهریزی کند، مانند جستجوی فضای ذخیرهسازی ابری برای یادداشتهای جلسه و واکشی سند درخواستی از فضای ذخیرهسازی ابری، و ارسال آن به مشتری. نکته مهم این است که این مدل زبانی بزرگ (LLM) ممتاز فقط پرسش اولیه کاربر را میبیند و هرگز محتوای منابع داده بالقوه در معرض خطر (مانند محتوای فایل) را نمیبیند.
پردازش واقعی دادههای بالقوه مخرب، مانند استخراج نام سند برای ارسال و آدرس ایمیل مشتری، به مدل زبانی بزرگ (LLM) قرنطینه شده واگذار میشود. این مدل زبانی بزرگ (LLM) قرنطینه شده، به طور حیاتی، از هرگونه قابلیت فراخوانی ابزار محروم شده است، و آسیبی که یک دستور تزریق شده میتواند ایجاد کند را محدود میکند و تضمین میکند که مهاجم نمیتواند ابزارهای دلخواه را با آرگومانهای دلخواه فراخوانی کند.
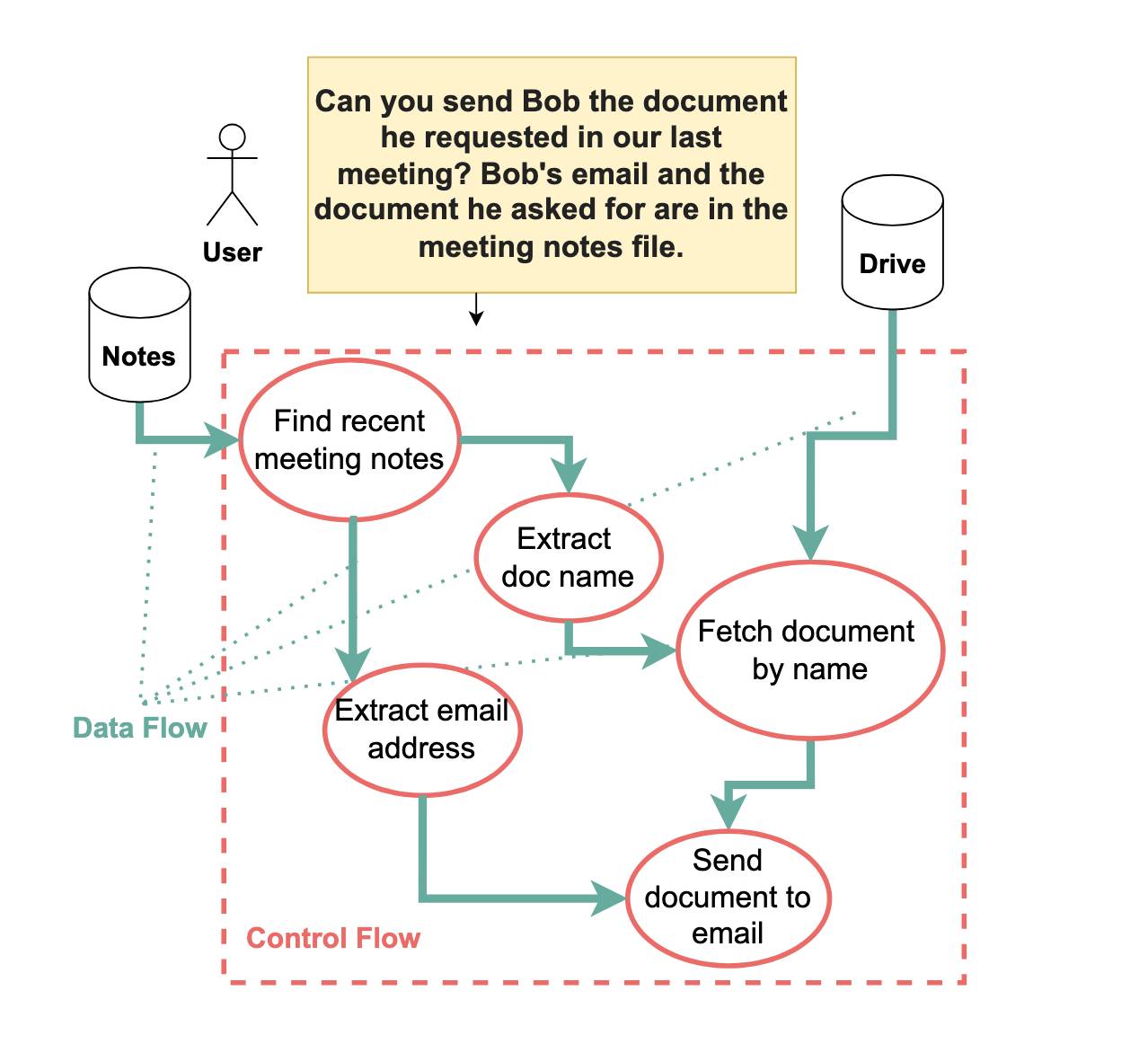
آیا Dual LLM ویلیسون کافی است؟ در حالی که الگوی Dual LLM با جدا کردن برنامهریزی از ربوده شدن توسط محتوای مخرب، امنیت را به طور قابل توجهی افزایش میدهد، اما به طور کامل تمام خطرات تزریق دستور را از بین نمیبرد. اجازه دهید مثالی را که در شکل ۱ نشان داده شده است در نظر بگیریم. در اینجا، حتی با وجود Dual LLM، نشان میدهیم که هنوز آسیبپذیریهایی وجود دارد.
اینجا شکل ۱ است:
دستور کاربر در اینجا این است:
آیا میتوانید سند درخواستی باب را که در آخرین جلسه ما درخواست کرده بود برای او بفرستید؟ ایمیل باب و سندی که او درخواست کرده است در فایل یادداشتهای جلسه موجود است.
و اینجاست که نقص وجود دارد. با الگوی Dual LLM، مدل زبانی بزرگ (LLM) ممتاز وظیفه یافتن آدرس ایمیل باب را به مدل زبانی بزرگ (LLM) قرنطینه شده واگذار میکند—اما مدل زبانی بزرگ (LLM) قرنطینه شده هنوز در معرض دستورالعملهای بالقوه مخرب قرار دارد. یک مهاجم میتواند از آن دستورالعملها برای نادیده گرفتن آدرس ایمیل بازیابی شده استفاده کند و باعث شود سند به آدرسی که توسط مهاجم انتخاب شده است منتقل شود.
رفع آن با قابلیتها و یک مفسر سفارشی
CaMeL به طور مستقیم با استفاده از مهندسی امنیتی بسیار هوشمندانه به این مشکل رسیدگی میکند.
در CaMeL، دستور کاربر توسط مدل زبانی بزرگ (LLM) ممتاز به یک توالی از مراحل تبدیل میشود که با استفاده از کد توصیف میشوند. آنها تصمیم گرفتند از یک زیرمجموعه قفل شده از پایتون برای این کار استفاده کنند، زیرا هر مدل زبانی بزرگ (LLM) موجود در حال حاضر در نوشتن پایتون خوب است:
ما یک مفسر پایتون سفارشی میسازیم که روی یک نسخه محدود از پایتون کار میکند. ما پایتون را انتخاب میکنیم زیرا یک زبان برنامهنویسی بسیار محبوب است، و مدلهای زبانی بزرگ در نوشتن آن بسیار ماهر هستند. ما از کتابخانه داخلی پایتون ast برای تجزیه درخت نحو انتزاعی استفاده میکنیم، و هر گره درخت را به صورت بازگشتی تفسیر میکنیم.
دستور "ایمیل باب را در آخرین ایمیل من پیدا کن و یک یادآوری در مورد جلسه فردا برای او بفرست" را در نظر بگیرید. CaMeL آن را به کدی تبدیل میکند که شبیه این است:
email = get_last_email()
address = query_quarantined_llm(
"Find Bob's email address in [email]",
output_schema=EmailStr
)
send_email(
subject="Meeting tomorrow",
body="Remember our meeting tomorrow",
recipient=address,
)همانطور که میبینید، این کد چندین فراخوانی به ابزارهایی را ترکیب میکند که به عنوان توابع پایتون در معرض دید قرار میگیرند—یکی برای بازیابی آخرین ایمیل، یکی که از یک مدل زبانی بزرگ (LLM) قرنطینه شده برای استخراج آدرس ایمیل باب از آن استفاده میکند و یکی برای ارسال یک ایمیل جدید.
اینجاست که همه چیز هوشمندانه میشود: با استفاده از یک مفسر سفارشی، CaMeL میتواند قوانین اضافی را برای کدی که اجرا میشود اعمال کند. این سیستم میتواند ردیابی کند که کدام متغیرها از کدام متغیرهای دیگر مشتق شدهاند و سیاستهای امنیتی را اعمال کند که این مسیر را در نظر میگیرند.
در این مثال، email یک منبع بالقوه از توکنهای غیرقابل اعتماد است، که به این معنی است که address نیز به همین ترتیب است (زیرا از email مشتق شده است).
قوانین امنیتی که باید اعمال شوند به شرح زیر است:
- get_last_email: همیشه مجاز است
-
send_email: فقط در صورتی که
recipientمورد اعتماد باشد
اگر address (که به send_email به عنوان پارامتر recipient ارسال میشود) یک آدرس شناخته شده و مورد اعتماد باشد—بر اساس سیاستهای تعیین شده توسط کاربر—سیستم میتواند آن ایمیل را بدون درخواست ابتدا ارسال کند. اگر یک ایمیل ناشناخته باشد، میتوان از کاربر خواست که پیام را تأیید کند.
قابلیتها در واقع تگهایی هستند که میتوانند به هر یک از متغیرها متصل شوند تا مواردی مانند اینکه چه کسی مجاز به خواندن یک قطعه داده است و منبعی که داده از آن آمده است را ردیابی کنند. سپس میتوان سیاستها را پیکربندی کرد تا بر اساس آن قابلیتها، اقدامات را مجاز یا رد کرد.
یک جایزه حریم خصوصی جالب
مزایای بالقوه دیگری نیز برای این طراحی وجود دارد. مدل زبانی بزرگ (LLM) ممتاز باید کاملاً پیچیده باشد، زیرا مسئول ساخت یک طرح و سپس تولید کد در گویش سفارشی پایتون است. مدل زبانی بزرگ (LLM) قرنطینه شده میتواند بسیار کم قدرتتر باشد:
از آنجایی که تجزیه دادهها احتمالاً آسانتر از ایجاد یک طرح و نوشتن کد برای پرسش کاربر است، میتوان از یک مدل زبانی کوچکتر برای Q-LLM استفاده کرد. علاوه بر اینکه سریعتر و ارزانتر است، این مدل زبانی بزرگ (LLM) به طور بالقوه میتواند به صورت محلی روی دستگاه کاربر نیز اجرا شود. این امر حریم خصوصی کاربر را نسبت به ارائهدهنده مدل بهبود میبخشد: از آنجایی که LLM استفاده شده به عنوان P-LLM فقط با پرسش کاربر ارائه میشود، ارائهدهنده P-LLM هرگز خروجیهای ابزار را نمیبیند (که ممکن است حاوی اطلاعات حساسی باشد که نباید با ارائهدهنده P-LLM به اشتراک گذاشته شود).
این بدان معناست که یک سیستم CaMeL میتواند از یک مدل زبانی بزرگ (LLM) میزبانی شده در ابر به عنوان درایور استفاده کند در حالی که دادههای خصوصی خود کاربر را به طور ایمن به دستگاه شخصی خود محدود میکند.
بهترین بخش این است که از هوش مصنوعی بیشتری استفاده نمیکند
بیشتر راهحلهای پیشنهادی که من تا به امروز برای تزریق دستور دیدهام، شامل لایهبندی حتی هوش مصنوعی بیشتر است. من در شما نمیتوانید مشکلات امنیتی هوش مصنوعی را با هوش مصنوعی بیشتر حل کنید نوشتم که چرا فکر میکنم این ایده بدی است. تکنیکهای هوش مصنوعی از احتمالات استفاده میکنند: شما میتوانید یک مدل را بر روی مجموعهای از نمونههای تزریق دستور قبلی آموزش دهید و به امتیاز ۹۹٪ در تشخیص موارد جدید برسید... و این بیفایده است، زیرا در امنیت برنامه ۹۹٪ نمره قبولی نیست:

وظیفه یک مهاجم خصمانه این است که ۱٪ حملاتی را که از آن عبور میکنند پیدا کند. اگر ما در برابر تزریق SQL یا XSS با استفاده از روشهایی که ۱٪ از مواقع با شکست مواجه میشوند محافظت میکردیم، سیستمهای ما در عرض چند لحظه هک میشدند.
پیشنهاد CaMeL این را تشخیص میدهد:
CaMeL یک دفاع عملی در برابر تزریق دستور است که امنیت را نه از طریق تکنیکهای آموزش مدل، بلکه از طریق طراحی سیستم اصولی در اطراف مدلهای زبانی به دست میآورد. رویکرد ما به طور موثر معیار AgentDojo را حل میکند در حالی که تضمینهای قوی در برابر اقدامات ناخواسته و انتقال داده ارائه میدهد. […]
این اولین کاهش برای تزریق دستور است که من دیدهام که ادعا میکند تضمینهای قوی ارائه میدهد! از محققان امنیتی که میآیند، این یک معیار بسیار بالاست.
آیا تزریق دستور اکنون حل شده است؟
نقل قول از بخش ۸.۳ از مقاله:
۸.۳. پس، آیا تزریق دستور اکنون حل شده است؟
نه، حملات تزریق دستور به طور کامل حل نشده است. در حالی که CaMeL امنیت عوامل LLM را در برابر حملات تزریق دستور به طور قابل توجهی بهبود میبخشد و امکان اجرای سیاست دقیق را فراهم میکند، اما بدون محدودیت نیست.
مهمتر از همه، CaMeL از نیاز کاربران به تدوین و تعیین سیاستهای امنیتی و نگهداری از آنها رنج میبرد. CaMeL همچنین دارای یک بار کاربر است. در عین حال، به خوبی شناخته شده است که متعادل کردن امنیت با تجربه کاربر، به ویژه با طبقهبندیزدایی و خستگی کاربر، چالش برانگیز است.
منظور آنها از "خستگی کاربر" این است که اگر شما دائماً از یک کاربر بخواهید که اقدامات را تأیید کند ("واقعاً این ایمیل را ارسال کنید؟"، "آیا دسترسی به این API اشکالی ندارد؟"، "اجازه دسترسی به حساب بانکی خود را بدهید؟") آنها در معرض خطر افتادن در حالت گنگی قرار میگیرند که در آن به همه چیز "بله" میگویند.
این میتواند بر محتاطترین افراد ما تأثیر بگذارد. محقق امنیتی تروی هانت فقط ماه گذشته به دلیل خستگی ناشی از جت لگ قربانی یک حمله فیشینگ شد.
هر چیزی که نیاز به این دارد که کاربران نهایی در مورد سیاستهای امنیتی فکر کنند نیز من را عمیقاً عصبی میکند. من به اندازه کافی مشکل دارم که خودم در مورد آنها فکر کنم (من هنوز به طور کامل AWS IAM را درک نکردهام) و من به مدت دو دهه در امنیت برنامه درگیر بودهام!
CaMeL واقعاً نشان دهنده یک مسیر امیدوارکننده به جلو است: اولین کاهش معتبر تزریق دستور که من دیدهام که فقط هوش مصنوعی بیشتری را به مشکل پرتاب نمیکند و در عوض به مفاهیم آزمایش شده و اثبات شده از مهندسی امنیتی، مانند قابلیتها و تجزیه و تحلیل جریان داده تکیه میکند.
امید من این است که نسخهای از این وجود داشته باشد که پیشفرضهای بهطور قوی انتخابشده را با یک طراحی رابط کاربری واضح ترکیب کند که در نهایت بتواند رویاهای دستیاران دیجیتالی عمومی را به یک واقعیت امن تبدیل کند.
شترها دو کوهان دارند
چرا آنها CaMeL را به عنوان نام اختصاری برای سیستم خود انتخاب کردند؟ من دوست دارم فکر کنم به این دلیل است که شترها دو کوهان دارند و CaMeL یک تکامل بهبود یافته از پیشنهاد Dual LLM من است.