
CocoIndex یک چارچوب ETL است که به شما کمک میکند تا دادههای خود را برای هوش مصنوعی در زمان واقعی آماده کنید.
بخش اساسی برای پشتیبانی از بهروزرسانی قوی و کارآمد، بهروزرسانی افزایشی است. در CocoIndex، کاربران تبدیل را اعلام میکنند و نیازی به نگرانی در مورد کار برای همگام نگه داشتن فهرست و منبع ندارند. در این وبلاگ، میخواهیم نحوه مدیریت بهروزرسانی افزایشی را به اشتراک بگذاریم.
اگر از کار ما خوشتان میآید، اگر بتوانید با یک ستاره در github از ما حمایت کنید، بسیار سپاسگزار خواهیم شد! https://github.com/cocoindex-io/cocoindex
CocoIndex یک فهرست ایجاد و نگهداری میکند و فهرست مشتق شده را بر اساس بهروزرسانی منبع، با حداقل محاسبات و تغییرات، بهروز نگه میدارد. این امر آن را برای ETL/RAG یا هر کار تبدیل دیگری مناسب میکند که تأخیر کمی بین بهروزرسانیهای منبع و فهرست داشته باشد و همچنین هزینه محاسبات را به حداقل میرساند.
بهروزرسانیهای افزایشی چیست؟
تشخیص اینکه دقیقاً چه چیزی نیاز به بهروزرسانی دارد و فقط همان را بهروزرسانی کنید، بدون اینکه مجبور شوید همه چیز را دوباره محاسبه کنید.
چگونه کار میکند؟
شما واقعاً نیازی به انجام کار خاصی ندارید، فقط روی تعریف تبدیل مورد نیاز تمرکز کنید.

CocoIndex به طور خودکار تبار دادههای شما را ردیابی میکند و یک حافظه پنهان از نتایج محاسباتی را نگهداری میکند. هنگامی که دادههای منبع خود را بهروز میکنید، CocoIndex:
-
مشخص میکند کدام بخشهای داده تغییر کردهاند
-
فقط تبدیلها را برای دادههای تغییر یافته دوباره محاسبه میکند
-
از نتایج ذخیره شده برای دادههای تغییر نیافته استفاده مجدد میکند
-
فهرست را با حداقل تغییرات بهروز میکند
و CocoIndex بهروزرسانیهای افزایشی را برای شما انجام میدهد.
CocoIndex دو حالت را با خط لوله با پیکربندی ساده ارائه میدهد:
- حالت دستهای - برای بهروزرسانی یکباره.
- حالت بهروزرسانی زنده - خط لوله طولانی مدت، با بهروزرسانی زنده. هر دو حالت با بهروزرسانیهای افزایشی اجرا میشوند.
چه کسی به بهروزرسانیهای افزایشی نیاز دارد؟
بسیاری از افراد ممکن است فکر کنند که بهروزرسانیهای افزایشی فقط برای دادههای در مقیاس بزرگ مفید است، اما با دقت فکر کردن، واقعاً به هزینه و نیاز به تازگی دادهها بستگی دارد.
گوگل دادههای در مقیاس بزرگ را پردازش میکند و گوگل منابع عظیمی برای آن دارد. مقیاس دادههای شما بسیار کمتر از گوگل است، اما تأمین منابع شما نیز بسیار کمتر از گوگل است.
شرایط واقعی برای نیاز به بهروزرسانی افزایشی عبارتند از:
- نیاز به تازگی بالا، به عنوان مثال، مشتری شما از انطباق GDPR برخوردار است، شما باید فهرست را با آخرین دادهها بهروز کنید.
- هزینه تبدیل به طور قابل توجهی بیشتر از خود بازیابی است
به طور کلی، بگوییم T قابل قبولترین کهنگی شما است، اگر نمیخواهید کل چیز را مکرراً هر T دوباره محاسبه کنید، پس کم و بیش به افزایشی نیاز دارید.
بهروزرسانیهای افزایشی دقیقاً چیست، با مثالها
خب، میتوانیم نگاهی به چند مثال بیندازیم تا بفهمیم چگونه کار میکند.
مثال 1: بهروزرسانی یک سند
این سناریو را در نظر بگیرید:
- من یک سند دارم. در ابتدا، به 5 تکه تقسیم میشود و در نتیجه 5 ردیف با نهفتهسازیهای آنها در فهرست قرار میگیرد.
- پس از بهروزرسانی، 3 مورد از آنها دقیقاً مانند قبلی هستند. بقیه تغییر کردهاند
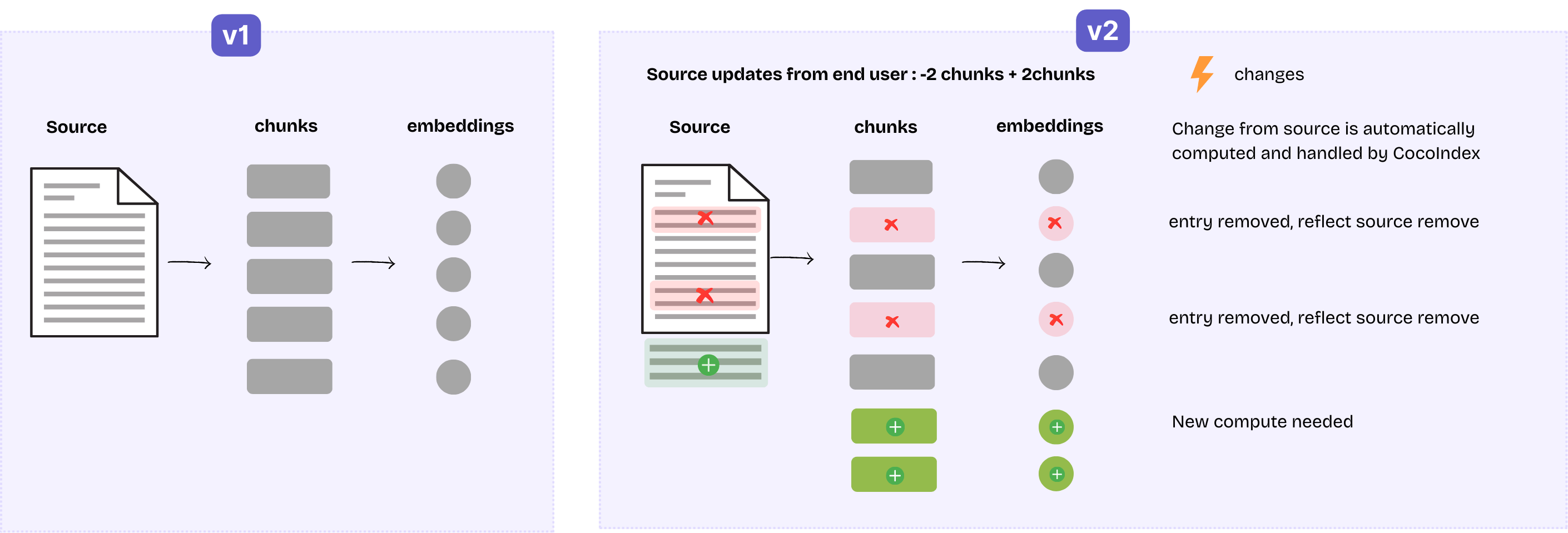
بنابراین ما نیاز داریم 3 ردیف را نگه داریم، 2 ردیف موجود قبلی را حذف کنیم و 2 ردیف جدید اضافه کنیم. اینها باید در پشت صحنه اتفاق بیفتد:
- به طور ایدهآل، ما فقط نهفتهسازیها را برای 4 ردیف جدید دوباره محاسبه میکنیم و از آن برای 3 تکه تغییر نیافته استفاده مجدد میکنیم. این میتواند در هزینه محاسبات صرفهجویی کند، به خصوص زمانی که API نهفتهسازی بر اساس میزان استفاده شارژ میشود. CocoIndex این امر را با نگهداری یک حافظه پنهان برای مراحل سنگین مانند نهفتهسازی به دست میآورد و اگر ورودی برای یک مرحله تبدیل تغییر نکند، خروجی دوباره استفاده میشود.
- علاوه بر این، ما همچنین یک ردیابی تبار در فضای ذخیرهسازی داخلی نگهداری میکنیم. این ردیابی میکند که کدام ردیفها در فهرست از نسخه قبلی این سند مشتق شدهاند تا اطمینان حاصل شود که نسخههای قدیمی به درستی حذف میشوند.
CocoIndex این را بر عهده میگیرد.
مثال 2: حذف یک سند
با همان مثال ادامه میدهیم. اگر سند را بعداً حذف کنیم، باید تمام 7 ردیف مشتق شده از سند را حذف کنیم. باز هم، این باید بر اساس ردیابی تبار نگهداری شده توسط CocoIndex باشد.
مثال 3: تغییر جریان تبدیل
جریان تبدیل نیز ممکن است تغییر کند، به عنوان مثال، منطق تکهتکه کردن ارتقا یافته است یا پارامتری که به تکهتکه کننده منتقل میشود تنظیم شده است. این ممکن است منجر به سناریوی زیر شود:
- قبل از تغییر، سند به 5 تکه تقسیم میشود و در نتیجه 5 ردیف با نهفتهسازیهای آنها در فهرست قرار میگیرد.
- پس از تغییر، آنها به 6 تکه تبدیل میشوند: 4 تکه قبلی بدون تغییر باقی میمانند، 1 باقیمانده به 2 تکه کوچکتر تقسیم میشود.
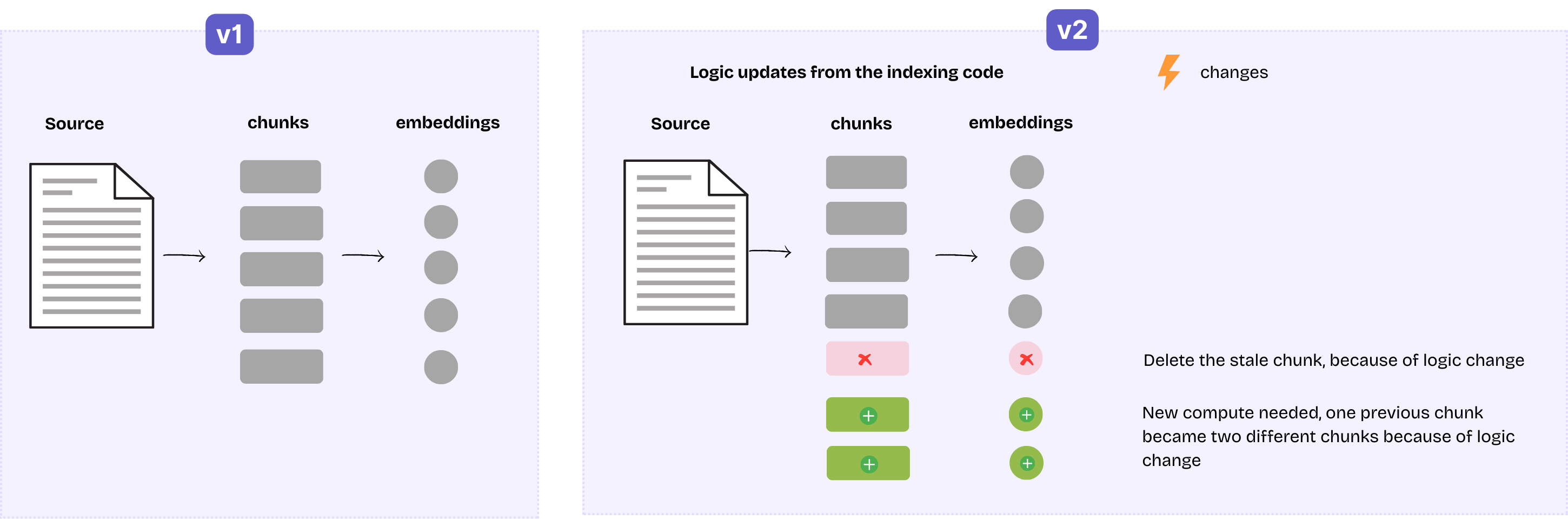
این به یک وضعیت مشابه بهروزرسانی سند (مثال 1) تبدیل میشود و CocoIndex از آن مراقبت خواهد کرد. رویکرد مشابه است، در حالی که این شامل برخی ملاحظات اضافی است:
- ما هنوز میتوانیم با خیال راحت از نهفتهسازیها برای 4 تکه تغییر نیافته توسط مکانیسم ذخیرهسازی مجدد استفاده کنیم: این نیاز به پیشنیاز دارد که منطق و مشخصات برای نهفتهسازی بدون تغییر باقی بماند. اگر قسمت تغییر یافته منطق یا مشخصات نهفتهسازی باشد، ما نهفتهسازیها را برای همه چیز دوباره محاسبه خواهیم کرد. CocoIndex قادر است ببیند که آیا منطق یا مشخصات برای یک مرحله عملیاتی از نسخه ذخیره شده تغییر کرده است یا خیر، با قرار دادن این اطلاعات اضافی در کلید حافظه پنهان.
- برای حذف ردیفهای قدیمی در فهرست هدف، ردیابی تبار دوباره به خوبی کار میکند. توجه داشته باشید که برخی از سیستمهای دیگر حذف خروجیهای قدیمی را در بهروزرسانی/حذف منبع با بازپخش منطق تبدیل در نسخه قبلی ورودی انجام میدهند: این فقط زمانی به خوبی کار میکند که تبدیل کاملاً قطعی باشد و هرگز ارتقا نیابد. رویکرد مبتنی بر ردیابی تبار CocoIndex این محدودیت را ندارد: در برابر غیرقطعی بودن و تغییرات منطق تبدیل مقاوم است.
مثال 4: چندین ورودی درگیر: ادغام / جستجو / خوشهبندی
تمام مثالهای بالا موارد سادهای هستند: هر ردیف ورودی منفرد (به عنوان مثال، یک سند) به طور مستقل در طول هر تبدیل خاص درگیر است.
CocoIndex یک چارچوب بسیار قابل تنظیم است، نه تنها محدود به تکهتکه کردن و نهفتهسازی ساده. این به کاربران اجازه میدهد تا تبدیلهای پیشرفتهتری مانند:
- ادغام. به عنوان مثال، شما در حال ایجاد یک فهرست برای "همه محصولات هوش مصنوعی" هستید و میخواهید اطلاعات را از چندین منبع ترکیب کنید، برخی از محصولات در یک منبع و برخی در چندین منبع وجود دارند. برای هر محصول، میخواهید اطلاعات را از منابع مختلف ترکیب کنید.
- جستجو. به عنوان مثال، شما همچنین یک منبع داده در مورد اطلاعات شرکت دارید. در طول تبدیل خود برای هر محصول، میخواهید آن را با اطلاعات شرکت سازنده محصول غنی کنید، بنابراین یک جستجو برای اطلاعات شرکت مورد نیاز است.
- خوشهبندی. به عنوان مثال، شما میخواهید محصولات مختلف را به سناریوها خوشهبندی کنید و خلاصه سطح خوشه را بر اساس اطلاعات محصولات در خوشه ایجاد کنید.
موضوع مشترک این است که در طول تبدیل، چندین ردیف ورودی (که از یک یا چند منبع میآیند) باید همزمان درگیر شوند. هنگامی که یک ردیف ورودی منفرد بهروز یا حذف میشود، CocoIndex باید ردیفهای مرتبط دیگر را از همان منبع یا منابع دیگر واکشی کند. در اینجا اینکه کدام ردیفهای دیگر مورد نیاز هستند، بر اساس این است که کدام یک در تبدیلها درگیر هستند. CocoIndex چنین روابطی را ردیابی میکند و ردیفهای مرتبط را واکشی میکند و پردازشهای مجدد لازم را به صورت افزایشی فعال میکند.
گرفتن تغییر داده (CDC)
1. هنگامی که منبع از تغییر فشار پشتیبانی میکند
برخی از اتصالات منبع از تغییر فشار پشتیبانی میکنند. به عنوان مثال، Google Drive از گزارش تغییرات سطح درایو پشتیبانی میکند و اعلانهای تغییر را به URL عمومی شما ارسال میکند، که برای درایو تیمی و درایو شخصی قابل استفاده است (فقط توسط OAuth، حساب سرویس پشتیبانی نمیشود). هنگامی که یک فایل ایجاد، بهروزرسانی یا حذف میشود، CocoIndex میتواند بر اساس تفاوت محاسبه کند.
2. مبتنی بر فراداده، فقط آخرین تغییر
برخی از اتصالات منبع از تغییر فشار پشتیبانی نمیکنند، اما فراداده و عملیات سیستم فایل را ارائه میدهند که جدیدترین فایلهای تغییر یافته را فهرست میکنند. به عنوان مثال، Google Drive با حساب سرویس.
CocoIndex میتواند تغییر را بر اساس آخرین زمان اصلاح شده در مقابل آخرین زمان نظرسنجی، محرک دورهای برای بررسی اصلاح شده نظارت کند. با این حال، این نمیتواند تغییر کامل را ثبت کند، به عنوان مثال یک فایل حذف شده است.
3. مبتنی بر فراداده، Fullscan
برخی از اتصالات منبع قابلیتهای محدودی با فهرست کردن فایلها دارند، اما فرادادهای را ارائه میدهند که همه فایلها را فهرست میکند. به عنوان مثال، با فایلهای محلی، ما باید تمام فایلها را در تمام دایرکتوریها و زیرشاخهها به صورت بازگشتی پیمایش کنیم تا لیست کامل را به دست آوریم.
هنگامی که تعداد فایلها زیاد است، پیمایش همه فایلها پرهزینه است.
حافظه پنهان
در CocoIndex، هر قطعه از بلوک لگو در خط لوله میتواند در حافظه پنهان ذخیره شود. توابع سفارشی میتوانند یک پارامتر cache را بگیرند. هنگامی که True است، اجرا کننده نتیجه تابع را برای استفاده مجدد در طول پردازش مجدد ذخیره میکند. توصیه میکنیم این را برای هر تابعی که از نظر محاسباتی فشرده است، روی True تنظیم کنید.
اگر همه اینها بدون تغییر باشند، خروجی مجدداً استفاده میشود: مشخصات (در صورت وجود)، دادههای ورودی، رفتار تابع. به همین منظور، یک behavior_version باید ارائه شود و باید در تغییرات رفتاری افزایش یابد.
به عنوان مثال، این امکان حافظه پنهان را برای یک تابع مستقل فراهم میکند، برای مثال کد کامل اینجا را ببینید:
@cocoindex.op.executor_class(gpu=True, cache=True, behavior_version=1)
class PdfToMarkdownExecutor:
"""Executor for PdfToMarkdown."""
...