من یک وبلاگ دوم دارم که در آن افکار نیمهپختهام را منتشر میکنم، گاهی پیشنمایشی از مطالبی که اینجا میآید. اگر علاقهمند هستید، چند تأمل درباره انتشار مدل متنباز آتی OpenAI پست کردم.
بدیهی است که یادگیری تقویتی (Reinforcement Learning یا RL) در حال بازگشت شکوهمندانه به میان جامعه گستردهتر هوش مصنوعی است، اما موفقیتهای واقعی آن عمدتاً چیزهایی نیستند که مردم روی آنها تمرکز کردهاند. مجموعه دادههای بیشتر ریاضی و کد، بسترهای اصلی برای تحقیق و پیشرفت هستند - میدانیم که در راهند. اما همچنان بیش از حد روی آنها تأکید میشود. همان روشهای RL در بسیاری از مدلها و محصولات هوش مصنوعی پیشرو استفاده میشوند.
این عمدتاً پستی است که چند هفته پیش درباره اخبار RL نوشتم و آن را دنبال میکردم. هرگز عملکرد متمرکزی نداشت، بنابراین منتشر نشد، اما آن را به اشتراک میگذارم زیرا بسیاری از افراد این حوزه را بسیار دقیق دنبال میکنند. امروز:
اشکال متعدد RL در OpenAI،
درباره تقطیر زنجیره افکار (Chain of Thoughts) در مقابل RL،
آیا DeepSeek مدل o1 را تقطیر کرد؟ و
چرا استدلال پنهان (Latent Reasoning) بسیار جالب است.
اشکال متعدد RL در OpenAI
برای کسانی که به جریان فرهنگی OpenAI در توییتر متصل هستند، واضح است که آنها به شدت روی یادگیری تقویتی سرمایهگذاری کردهاند.۱ با هیجان پیرامون انتشار سری مدلهای استدلالگر o، آسان بود که فرض کنیم اینها تنها راه هیجانانگیز هستند. انتشارات اخیر OpenAI نشان داده است که اینطور نیست و هر انتشار، از عرضه یک مدل گرفته تا یک محصول جدید، شامل اشاراتی به آموزش RL بوده است. البته بخشی از این موضوع بازاریابی است، اما همه آنها به عنوان کاربردهای متفاوتی از تنظیم دقیق تقویتی (Reinforcement Finetuning یا RFT) / RL با پاداشهای قابل تأیید (RL with Verifiable Rewards یا RLVR) مناسب هستند.۲
اولین کاربرد دیگر، عامل Operator از OpenAI بود. آنها بیان کردند:
با ترکیب قابلیتهای بینایی GPT-4o با استدلال پیشرفته از طریق یادگیری تقویتی، CUA آموزش دیده است تا با رابطهای کاربری گرافیکی (GUI) - دکمهها، منوها و فیلدهای متنی که افراد روی صفحه میبینند - تعامل داشته باشد.
در این پست کمی بیشتر از حد معمول نیاز به گمانهزنی وجود دارد. در نهایت، با شرکایی مانند DoorDash، Instacart و غیره که با آنها همکاری کردند، میتوانستند دامنههای قابل تأییدی را ایجاد کنند که در آن عامل برای انجام یک وظیفه زبان طبیعی پاداش میگیرد. این امر میتواند برای شروع به کمک آن وبسایتها متکی باشد. در نهایت، افراد زیادی میدانند که این *میتواند* کار کند، زیرا عاملها عمیقاً به بطن افسانههای RL گره خوردهاند، اما جزئیات پیادهسازی در پروژههای متنباز واقعاً مشخص نشدهاند.
همین امر در مورد Deep Research نیز صدق میکند. آنها بیان کردند:
Deep research به طور مستقل بینشهایی را از سراسر وب کشف، استدلال و یکپارچه میکند. برای دستیابی به این هدف، با استفاده از همان روشهای یادگیری تقویتی که در پشت OpenAI o1، اولین مدل استدلالگر ما قرار دارد، بر روی وظایف دنیای واقعی که نیازمند استفاده از ابزارهای مرورگر و پایتون هستند آموزش داده شده است.Deep research با استفاده از یادگیری تقویتی سرتاسری بر روی وظایف دشوار مرور وب و استدلال در طیف وسیعی از دامنهها آموزش داده شده است.
جزئیات بیشتری در کارت سیستم Deep Research به اشتراک گذاشته شد.

چیزهای زیادی وجود دارد که میتوان تصور کرد - برای مثال، عامل در صورتی پاداش میگیرد که سند بازیابی شده از جستجو اطلاعات مرتبطی داشته باشد (پاداش قابل تأیید نیست، اما از روش LLM-as-a-judge استفاده میشود). بیشتر این موارد احتمالاً برای دستیابی به قابلیت اطمینان بسیار بالا در استفاده از ابزارها به کار میروند تا امکان انجام تماسهای فراوان در پسزمینه را فراهم کنند، زمانی که یک تماس برای کاربر بیش از ۱۰ دقیقه طول میکشد.
کمترین شگفتی مربوط به اعلام مدل جدید GitHub CoPilot با آموزش RL جدید و بهبود یافته برای کد بود:
مدل جدید تکمیل کد ما امروز در پیشنمایش عمومی عرضه میشود. ما آن را GPT-4o Copilot مینامیم. مبتنی بر GPT-4o mini، با آموزش میانی بر روی مجموعهای متمرکز بر کد با بیش از ۱ تریلیون توکن و یادگیری تقویتی با بازخورد اجرای کد (RLEF).
همه اینها به آنچه در مطلب تنظیم دقیق تقویتی OpenAI و RL برای همگان گفتم بازمیگردد — این آموزش جدید RL روشی کاملاً هماهنگ برای دستیابی به عملکرد تقریباً بینقص در دامنهای است که میتوانید با دقت کنترل کنید. بهترین نتایج با تسلط بر دامنه و با آموزش به دست میآیند.
یک گمانهزنی جالب مبنی بر اینکه OpenAI *واقعاً* روی RL و پسآموزش سرمایهگذاری کرده است، این است که مدل جدید o3-mini آنها همان تاریخ قطع داده، اکتبر ۲۰۲۳، را دارد که سایر مدلهای پرچمدار OpenAI دارند. این که تاریخ قطع داده بسیار قدیمی شده است، نشان میدهد که OpenAI چقدر روی محصولات جستجوی خود (که انصافاً بسیار خوب هستند) سرمایهگذاری کرده است و چگونه چنین بهبودهای عملکردی قویای میتواند از طریق بهبودهای دیگر در پشته آموزش حاصل شود.
OpenAI همچنین مقالهای در مورد کدنویسی رقابتی با آموزش RL منتشر کرد، اما جزئیات مفید زیادی نداشت.
درباره تقطیر زنجیره افکار در مقابل RL
چند نکته از مقاله DeepSeek و گفتمان پیرامون آن وجود دارد که ارزش تکرار دارند. برای تکرار، تقطیر (distillation) در این مورد، آموزش یک مدل (معمولاً با SFT، اما هر تابع زیانی کار میکند) بر روی خروجیهای یک مدل قویتر است. بیایید مستقیماً به سراغ آن برویم.
اول، DeepSeek به وضوح بیان کرد که استفاده بیشتر از RL *پس از* تقطیر (SFT) برای بهترین مدلهای ممکن حیاتی است.
علاوه بر این، ما دریافتیم که اعمال RL بر روی این مدلهای تقطیر شده، دستاوردهای قابل توجه بیشتری را به همراه دارد. ما معتقدیم این امر مستلزم بررسی بیشتر است و بنابراین در اینجا فقط نتایج مدلهای ساده تقطیر شده با SFT را ارائه میدهیم.
درک فعلی من در اینجا این است که تطبیق توزیع دادهها از آموزش مدل پایه با دادههای تقطیر و پرامپتهای RL بسیار مهم است. این به طور خاص برای فعال کردن RL در انتها حیاتی است — SFT تقریباً همیشه امتیازات را افزایش میدهد، اما میتواند دامنه ای را که مدل میتواند بیشتر تنظیم دقیق شود، محدود کند. DeepSeek این موضوع را برای مدلهای خود کشف کرد، اما جزئیات را به اشتراک نگذاشت.
نکته بعدی در مورد چگونگی تأثیر مقیاس بر آموزش RL است:
اول، تقطیر مدلهای قدرتمندتر به مدلهای کوچکتر نتایج بسیار خوبی به همراه دارد، در حالی که مدلهای کوچکتر که به RL در مقیاس بزرگ ذکر شده در این مقاله متکی هستند، به قدرت محاسباتی عظیمی نیاز دارند و ممکن است حتی به عملکرد تقطیر نرسند.
این بیشتر گیجکننده است تا مفید، و از این واقعیت نشأت میگیرد که «DeepSeek-R1-Distill-Qwen-32B۳، که از DeepSeek-R1 تقطیر شده است، به طور قابل توجهی بهتر از DeepSeek-R1-Zero-Qwen-32B در تمام بنچمارکها عمل میکند». نباید انتظار داشته باشیم که مدلهای سبک Zero که فقط با RL آموزش دیدهاند، در بنچمارکها عملکرد خوبی داشته باشند (مگر اینکه روی دادههای آزمون آموزش دیده باشید). این چیزی نیست که برای آن طراحی شدهاند. مدلهای تقطیر شده روی متنی آموزش دیدهاند که برای گردش کار مدلسازی زبان موجود بسیار دقیق تنظیم شده است. مدلهای RL-Zero (تقطیر نشده) در رفتارهای خود بسیار اکتشافی هستند.
خط پایه مناسب، قرار دادن Qwen-32B در کل دستورالعمل R1 خواهد بود — که احتمالاً بسیار بیشتر از نسخه تقطیر شده عملکرد بهتری خواهد داشت.
با این حال، واقعیت این است که مدلهای کوچک به کار بیشتری از RL نیاز دارند. انجام این نوع RL اکتشافی با مدلهای بزرگ بسیار آسانتر است. ممکن است به این دلیل باشد که آنها رفتارهای نادر بیشتری را در طول پیشآموزش در خود نگه میدارند و RL آنها را بیرون میکشد. مدلهای کوچکتر ممکن است این رفتارهای دمدراز (long-tail) را سرکوب کنند.
در ادامه این بحث، نویسندگان DeepSeek بیان میکنند:
دوم، در حالی که استراتژیهای تقطیر هم اقتصادی و هم مؤثر هستند، پیشروی فراتر از مرزهای هوش ممکن است همچنان به مدلهای پایه قدرتمندتر و یادگیری تقویتی در مقیاس بزرگتر نیاز داشته باشد.
آیا DeepSeek مدل o1 متعلق به OpenAI را تقطیر کرد؟ (راهنمایی: خیر)
این سؤالی است که مدتها پیش قصد داشتم به آن بپردازم، اما حالا اینجا هستیم، عرضه چند مدل مانع شد. انتقادی که توسط OpenAI و بسیاری از رسانهها مطرح شد این است که DeepSeek بر روی ردپاهای استدلال (reasoning traces) از مدل o1 OpenAI آموزش دیده است. OpenAI تقریباً ۱۸ ماه برای به دست آوردن دادههای اولیه برای آموزش مدل o1 خود وقت صرف کرد، بنابراین قابل درک است که آنها نگران باشند که آن را به صورت رایگان به اشتراک بگذارند.
@abacaj: برای شفافسازی، ما هرگز از o1 یا GPT4 در آموزش استفاده نکردهایم. ما یک مدل *بزرگتر* از 1.5 تریلیون توکن خودمان داریم که از آن برای تقطیر مدلهای کوچکتر استفاده میکنیم.
@ylecun: آنها در یادداشتهای انتشار، روش استفاده شده برای تولید دادههای آموزشی را توضیح دادهاند. این روش از آموزش مدلهای تقویتی بر روی مسائل ریاضی/کدنویسی به جای تقطیر از o1 استفاده میکند.
همانطور که لکان اشاره میکند، روش آنها مستند شده است و شامل یک مدل بزرگتر از 1.5 تریلیون توکن برای تقطیر است. این مدل معلم، DeepSeek-R1 نامیده میشود، اما هرگز منتشر نشده است. با توجه به اینکه مدلهای اصلی DeepSeek با دادههای ۲ تریلیون توکن و سپس ۶ تریلیون توکن آموزش دیدهاند، میتوان فرض کرد که مدل معلم آنها نیز در جایی در آن محدوده قرار دارد. با این حال، آنها به وضوح اظهار داشتند که از مدلهای OpenAI استفاده نکردهاند.
چرا استدلال پنهان بسیار جالب است
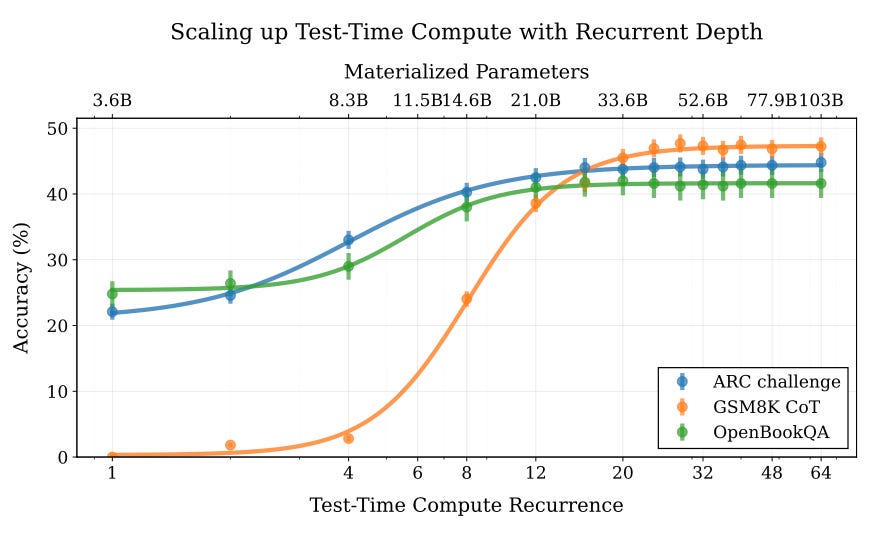
در چند وقت اخیر، کارهای زیادی در زمینه مدلهای زبانی وجود داشته است که به دنبال جدا کردن مراحل محاسبات داخلی، یا استدلال، از مراحل تولید توکن هستند. تصویر سرصفحه مقاله مربوط به استدلال پنهان (Latent Reasoning) است، که در آن از یک معماری استفاده میشود که دارای عمق بازگشتی است، جایی که محاسبات اضافی قبل از نمونهبرداری از توکن بعدی انجام میشود. این کار جالبی است، زیرا نشان میدهد که تخصیص محاسبات زمان آزمون اضافی میتواند منجر به دستاوردهای قابل توجهی در عملکرد شود.

این رویکرد کمی شبیه به کاری است که با مهندسی پرامپت، مانند زنجیره افکار، انجام میدهیم، اما به جای نوشتن گامهای میانی به صورت متن، محاسبات در حالت پنهان مدل انجام میشود. این امر میتواند به طور قابل توجهی سریعتر باشد، زیرا تنها توکنهای نهایی تولید میشوند. این روش شباهت زیادی به رویکرد «مدل استدلالگر» OpenAI دارد، اما به نظر میرسد بدون نیاز به آموزش RL گسترده پیادهسازی شده است.
شایان ذکر است که حداقل یک محقق در OpenAI اشاره کرده است که این کار بسیار شبیه به o1 است، که احتمالاً به این معنی است که o1 از این نوع معماری محاسباتی زمان آزمون انعطافپذیر بهره میبرد، اگرچه هنوز از RL برای بهبود آن استفاده میکند.
جمعبندی
RL پیچیده است، نحوه تعامل آن با سایر روشهای آموزشی نیز پیچیده است، و پیادهسازی واقعی آن حتی پیچیدهتر است. به نظر میرسد که در آینده نزدیک، RL نقش مهمی در توسعه مدلهای پیشرفته ایفا خواهد کرد، اما درک کامل چگونگی و چرایی کارکرد آن همچنان یک حوزه تحقیقاتی فعال است. ترکیب تقطیر، RL، و معماریهای جدید مانند استدلال پنهان، مرزهای توانایی مدلهای زبانی را پیش میبرد.
۱ من مطمئن نیستم که آیا این نشاندهنده این است که آنها بهطور کامل روی این نوع روشهای RL سرمایهگذاری کردهاند، یا اینکه صرفاً آنها را به عنوان یک مسیر موازی که شایسته سرمایهگذاری عمده است، میبینند. هر دو امکانپذیر است.
۲ جالب است که OpenAI نامگذاری را از RFT به RLVR تغییر داد. این موضوع در پست بعدی من در مورد نامگذاری OpenAI پوشش داده خواهد شد.
۳ توجه داشته باشید که نامگذاری مدل کمی گیجکننده است. این مدل بر روی Qwen-32B پایه ساخته شده است.