گوگل دسترسی گستردهتری به Gemini 2.5 Pro، جدیدترین مدل پرچمدار هوش مصنوعی خود را باز کرده است که عملکرد چشمگیری در آزمایشهای علمی نشان میدهد و قیمتگذاری رقابتی را معرفی میکند.
به گفته ساندار پیچای، مدیرعامل آلفابت، Gemini 2.5 Pro «هوشمندترین مدل گوگل + اکنون پرتقاضاترین مدل ما» است. تقاضا در این ماه به تنهایی بیش از ۸۰ درصد در هر دو پلتفرم Google AI Studio و Gemini API افزایش یافته است. از این هفته، کاربران میتوانند به یک پیشنمایش عمومی گستردهتر با محدودیتهای استفاده بالاتر، از جمله یک گزینه لایه رایگان، دسترسی داشته باشند.
کاربران Gemini Web Chat میتوانند به استفاده از مدل آزمایشی 2.5 Pro ادامه دهند، که باید عملکردی معادل ارائه دهد. گوگل قصد دارد در کنفرانس Cloud Next '25 خود در تاریخ ۹ آوریل، اطلاعیههای بیشتری منتشر کند.
قیمتگذاری رقابتی
Gemini 2.5 Pro API از یک مدل قیمتگذاری طبقهبندی شده پیروی میکند. برای پرامپتهای (دستورات ورودی) تا ۲۰۰٬۰۰۰ توکن، ورودی ۱.۲۵ دلار به ازای هر میلیون توکن هزینه دارد و خروجی ۱۰ دلار است. پرامپتهای بزرگتر به ترتیب به ۲.۵۰ دلار و ۱۵ دلار به ازای هر میلیون توکن افزایش مییابند. در حالی که کش کردن پرامپت (prompt caching) در حال حاضر در دسترس نیست، حتی در لایه پولی، اجرای آینده آن میتواند هزینهها را بیشتر کاهش دهد.
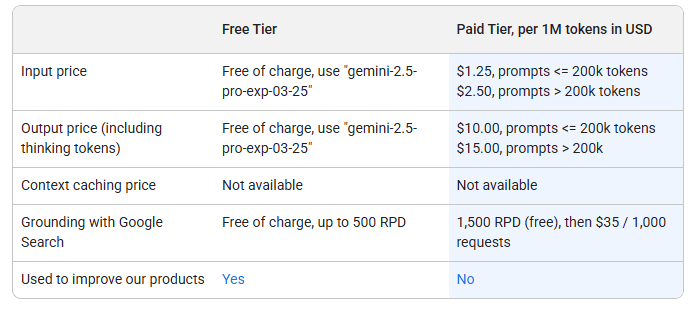
گوگل اتصال رایگان به جستجوی گوگل (free grounding) را تا ۵۰۰ کوئری (پرسوجو) روزانه ارائه میدهد و پس از آن ۱۵۰۰ کوئری رایگان اضافی نیز وجود دارد. فراتر از آن، هر ۱۰۰۰ کوئری ۳۵ دلار هزینه دارد. طبق شرایط استفاده، دادههای لایه رایگان ممکن است برای آموزش هوش مصنوعی استفاده شوند، در حالی که دادههای لایه پولی نمیتوانند استفاده شوند.
در مقایسه با مدلهای رقیب مانند Claude 3.7 Sonnet، Gemini 2.5 Pro با عملکرد یکسان یا بهتر، به طور قابل توجهی ارزانتر است. بنابراین، رقابت بر سر قیمت و عملکرد در بازار مدلها ادامه دارد.
عملکرد قوی در آزمایشهای علمی
گروه تحقیقاتی هوش مصنوعی EpochAI گزارش میدهد که Gemini 2.5 Pro در بنچمارک GPQA Diamond امتیاز ۸۴٪ کسب کرده است - که به طور قابل توجهی بالاتر از امتیاز معمول ۷۰٪ کارشناسان انسانی است. این بنچمارک شامل سوالات چند گزینهای بهخصوص چالشبرانگیز در زمینههای زیستشناسی، شیمی و فیزیک است. آزمایش مستقل EpochAI نتایج بنچمارک گوگل را تأیید میکند.
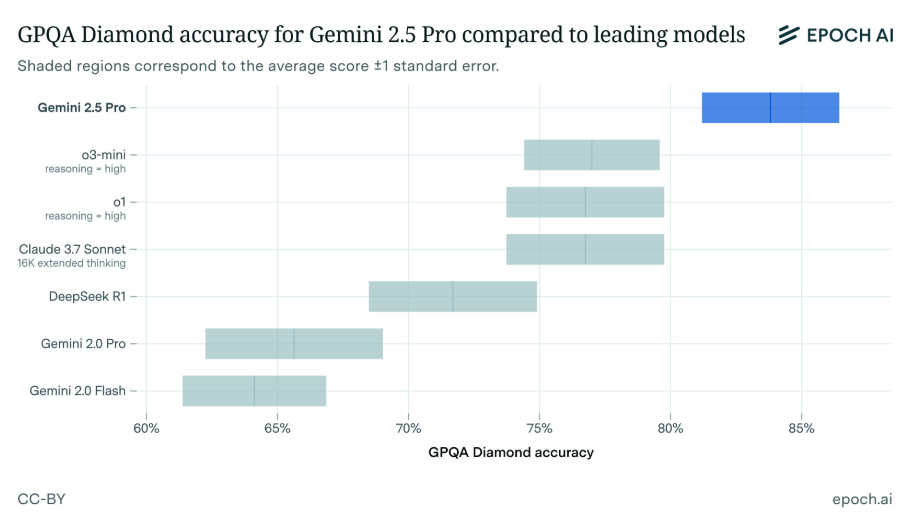
در حالی که گوگل جزئیات فنی در مورد معماری مدل، دادههای آموزشی یا نیازمندیهای محاسباتی را منتشر نکرده است، مشخص است که این یک مدل "استدلالی" شبیه به سری o شرکت OpenAI است. EpochAI اشاره میکند که آزمایش آنها به دلیل محدودیتهای نرخ (rate restrictions) فعلی مدل آزمایشی، محدود بوده است.
قابلیتهای این مدل فراتر از GPQA است. در آزمون چالشبرانگیز "آخرین امتحان بشریت (Humanity's Last Exam)"، Gemini 2.5 Pro امتیاز ۱۸.۸٪ را کسب کرد - بالاترین امتیاز در بین مدلهای بدون ابزار اضافی، که به طور قابل توجهی از رقبایی مانند Deepseek-R1 با نه درصد، بهتر عمل کرد.
در آزمایشهای هفتگی در trackingAI.org، نسخه آزمایشی تواناییهای شناختی چشمگیری از خود نشان داد و میانگین IQ (بهره هوشی) ۱۳۰ را کسب کرد - بسیار بالاتر از محدوده معمول ۹۰-۱۱۰ که در سایر مدلهای زبانی دیده میشود.
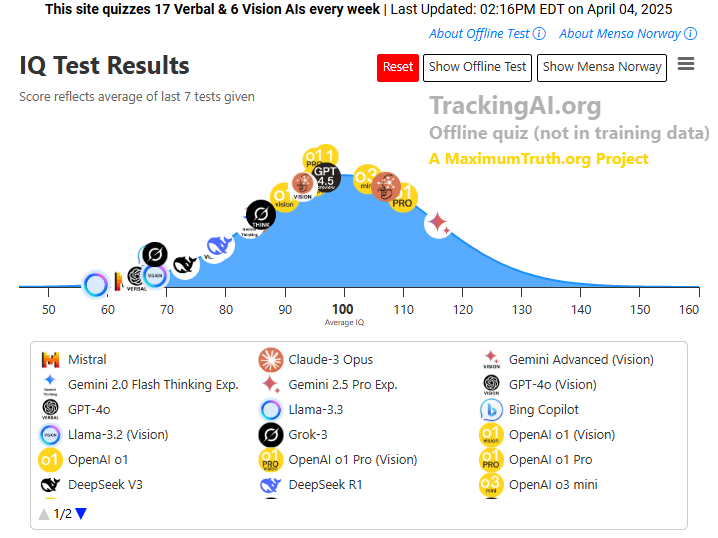
این ارزیابیهای IQ از نسخههای متنی آزمون IQ منسا نروژ استفاده میکنند و سوالات را به صورت کلامی ارائه میدهند نه بصری مانند مدلهای بینایی (vision models) سنتی. سوالات در دادههای آموزشی گنجانده نشدهاند و اگر مدلی در پاسخ دادن تردید کند، تا ده بار تلاش میکند قبل از اینکه آخرین پاسخ معتبر آن ثبت شود.
مدل جدید گوگل همچنین بازخوردهای مثبت مداومی در شبکه اجتماعی X دریافت کرده است. دانشمند کامپیوتر فرانسوا شوله، Gemini 2.5 Pro را به عنوان مدل کاری روزانه خود توصیف میکند. برای او، این بهترین مدل برای تقریباً تمام وظایف است - به استثنای تولید تصویر، که در آن نیز عملکرد خوبی دارد.
به گفته سرمایهگذار مارتین کاسادو، او تقریباً به طور انحصاری از آن برای وظایف کدنویسی استفاده میکند. در جدول مقایسهای خود، پیتر یانگ، Gemini 2.5 را به عنوان بهترین مدل فعلی برای وظایف برنامهنویسی رتبهبندی کرد. محقق هوش مصنوعی ژاپنی شین گو به ویژه نسبت هزینه به فایده مدل را تحسین میکند: Gemini در تمام دستههای قیمتی در مرز پارتو (Pareto frontier) قرار دارد.
خلاصه
- گوگل دسترسی به مدل هوش مصنوعی Gemini 2.5 Pro خود را گسترش میدهد و دسترسی عمومی گستردهتری را فراهم میکند.
- این مدل در بنچمارکهای علمی مانند GPQA Diamond و آزمونهای IQ عملکرد قوی نشان میدهد و از مدلهای رقیب و حتی متخصصان انسانی پیشی میگیرد.
- Gemini 2.5 Pro قیمتگذاری رقابتی ارائه میدهد که آن را به گزینهای مقرونبهصرفه در مقایسه با سایر مدلهای پیشرفته تبدیل میکند.
- این مدل بازخوردهای مثبتی از کارشناسان و کاربران برای وظایف مختلف، از جمله برنامهنویسی و استدلال، دریافت کرده است.