
تحقیقات در زمینه استدلال و یادگیری تقویتی (RL) سر و صدای زیادی به پا کرده است، اما یافتن موارد مهم در میان این هیاهو آسان نیست. این پست به بررسی مقالاتی میپردازد که از آنها آموختم و معنای آنها را شرح میدهد.
اگر پیش از خواندن این مطلب، دستورالعمل DeepSeek R1 را نخوانده و درک نکردهاید، اکیداً توصیه میشود. برای یادگیری تقویتی و دیگر مبانی، به کتابی که در مورد RLHF مینویسم (که هنگام نوشتن این پست بسیار بهبود یافته است) یا مقاله DeepSeekMath که بهینهسازی سیاست نسبی گروهی (GRPO) را معرفی کرد، مراجعه کنید.
در زیر تابع زیان (loss function) آمده است که در مقالات مورد اشاره تکرار میشود.

ما در مورد رویه آموزشی Kimi k1.5، آخرین مدل زبان بزرگ (LLM) چندوجهی ما که با یادگیری تقویتی (RL) آموزش دیده است، گزارش میدهیم؛ از جمله تکنیکهای آموزش RL آن، دستورالعملهای داده چندوجهی و بهینهسازی زیرساخت. مقیاسپذیری زمینه طولانی و روشهای بهبود یافته بهینهسازی سیاست، مؤلفههای کلیدی رویکرد ما هستند که یک چارچوب RL ساده و مؤثر را بدون تکیه بر تکنیکهای پیچیدهتر مانند جستجوی درخت مونت کارلو، توابع ارزش و مدلهای پاداش فرآیند، ایجاد میکند.
ارزیابیها همچنان بسیار قوی هستند، با توجه به اینکه مدل قبل از در دسترس قرار گرفتن o3-mini منتشر شد.

OpenReasonerZero: استدلال به عنوان بهینهسازی بدون آموزش داده (Zhang et al.)
OpenReasonerZero، یک چارچوب جدید استدلال زنجیرهای تفکر (CoT) را معرفی میکنیم که استدلال را به عنوان یک فرآیند بهینهسازی فرموله میکند. رویکرد ما برای بهینهسازی توالیهای CoT بدون نیاز به آموزش یا تنظیم دقیق، به طور مستقیم با یک LLM ثابت شروع میشود. به طور خاص، ما یک هدف بهینهسازی طراحی میکنیم که شامل همسویی و انسجام استدلال است و به طور مؤثر دانش از پیش آموخته شده در LLM را به سمت بهبود عملکرد استدلال هدایت میکند.
به طور شهودی، OpenReasonerZero به دنبال یافتن توالی استدلالی است که هم با دانش مدل مطابقت داشته باشد و هم برای تولید پاسخ نهایی مفید باشد. این کار از طریق بهینهسازی یک هدف طراحیشده انجام میشود که همسویی با دانش مدل و انسجام استدلال را در نظر میگیرد.
این رویکرد جالب است زیرا از مدل به عنوان یک پایگاه داده استفاده میکند و فقط از دانش LLM برای استدلال استفاده میکند.

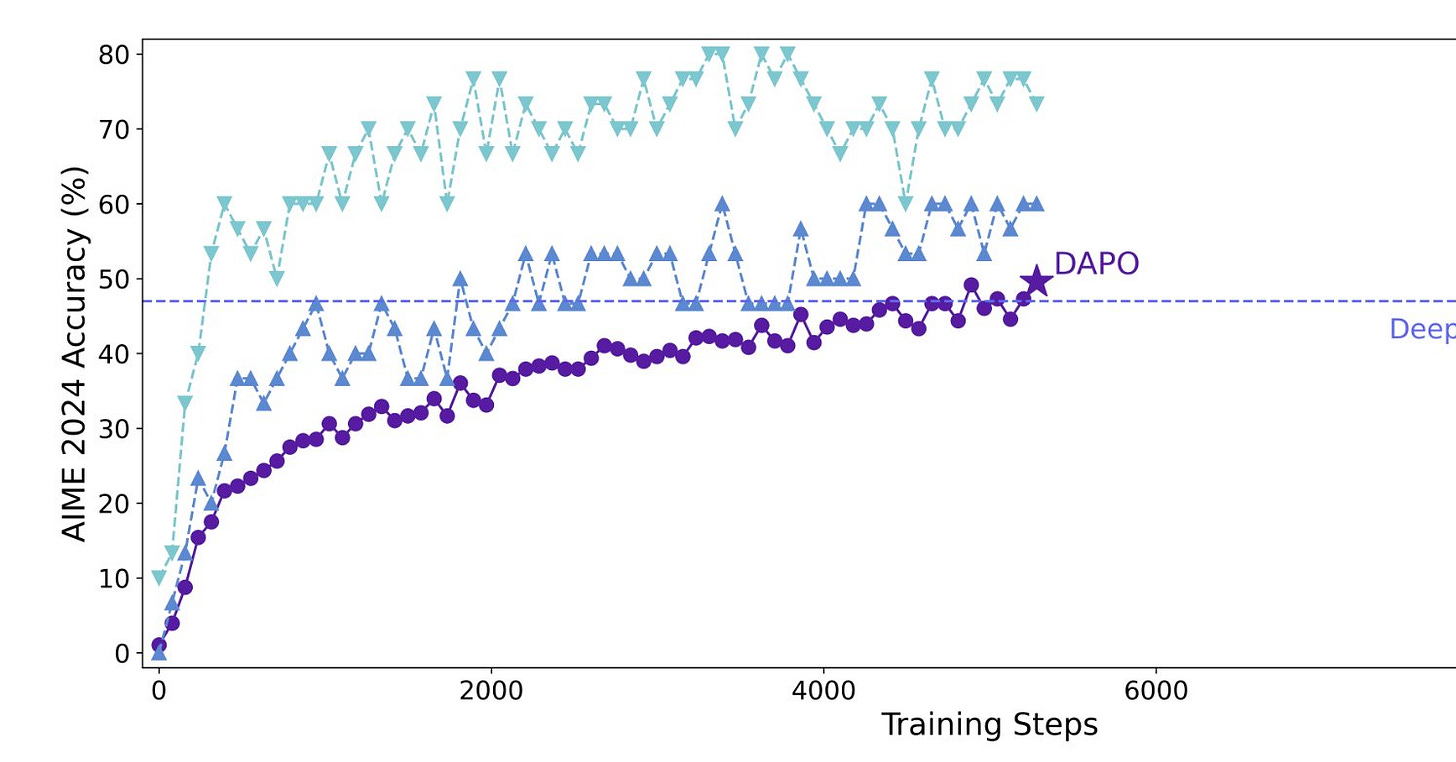
DAPO: بهینهسازی مستقیم سیاست با مجموعههای دادهای انسانی (Lee et al.)
ما روش جدیدی را برای تنظیم دقیق LLMها برای استدلال ارائه میکنیم که مجموعههای دادهای انسانی را به طور مستقیم بهینه میکند. هدف ما حل مشکلات مربوط به روشهای فعلی مانند تقویت پاداش مبتنی بر یادگیری و تقطیر سیاست است. ما انحراف توزیع را با تغییر دادن هدف بهینه سازی برای مطابقت با ساختار توزیع مجموعه دادههای انسانی، کاهش میدهیم. همچنین، ما با به حداکثر رساندن احتمال دادههای انسانی، استفاده از اطلاعات موجود در مجموعههای دادهای انسانی را افزایش میدهیم. آزمایشهای ما نشان میدهد که رویکرد ما از نظر کارایی نمونه و پایداری، عملکرد خوبی دارد و به طور قابل توجهی از روشهای فعلی در وظایف استدلالی پیشی میگیرد.
تکنیک اصلی DAPO این است که به حداکثر رساندن احتمال دادههای انسانی در مدل سیاست یادگیری تقویتی (RL) به جای به حداکثر رساندن پاداش، انحراف توزیع و مشکلات مربوط به روشهای فعلی را کاهش میدهد. این استدلال شبیه به TRL است، که به حداکثر رساندن احتمال دادههای آموزشی را به عنوان روشی برای بهینهسازی سیاست مدلهای زبان آموزشدیده از طریق یادگیری تقویتی نشان داد.

Dr.GRPO: بهبود GRPO با استخراج متون نامربوط و روش تنظیم متغیر یادگیری (Kim et al.)
بهینهسازی سیاست نسبی گروهی (GRPO) به عنوان یک الگوریتم امیدوارکننده برای یادگیری مدل پاداش با استفاده از بازخورد انسانی ظاهر شده است. در این مقاله، دو مشکل اساسی GRPO را مورد بررسی قرار دادهایم: (1) اثرات نامطلوب ناشی از نمونههای دادهای نامربوط استخراج شده از فرآیند برچسبگذاری و (2) انتخاب یک روش تنظیم مناسب برای فرآیند بهینهسازی. ما Dr.GRPO را پیشنهاد میکنیم، یک روش بهبودیافته GRPO که برای رسیدگی به این مسائل طراحی شده است. اولاً، با معرفی یک معیار نامربوط برای فیلتر کردن مجموعههای نامربوط از مجموعههای دادهها، یک فرآیند فیلتر اطلاعات را به آن اضافه میکنیم. ثانیاً، ما یک تابع زیان پیشنهاد میکنیم که بر اساس درجات نامربوط نمونههای مختلف، یک روش تنظیم متغیر یادگیری را ارائه میدهد. ما از طریق آزمایشهای گسترده در زمینههای تولید متن خلاقانه و استدلال ریاضی، کارایی Dr.GRPO را نشان میدهیم.
این واقعیت که Dr.GRPO از رویکرد GRPO مشابه DeepSeekMath و DeepSeek R1 استفاده میکند (که من از آن بسیار هیجانزده هستم) برای من جالب است. این در زمان توسعه DeepSeekMath و R1 بسیار مبهم بود!