
تولید افزوده با بازیابی (RAG)رویکردی برای ساخت سیستمهای هوش مصنوعی است که یک مدل زبانی را با یک منبع دانش خارجی ترکیب میکند. به زبان ساده، هوش مصنوعی ابتدا اسناد مرتبط (مانند مقالات یا صفحات وب) مربوط به پرسش کاربر را جستجو میکند و سپس از آن اسناد برای تولید پاسخ دقیقتر استفاده میکند. این روش به دلیل کمک به مدلهای زبانی بزرگ (LLMs)برای حفظ واقعیتگرایی و کاهش توهمات از طریق استناد پاسخهایشان به دادههای واقعی، مورد تحسین قرار گرفته است.
به طور شهودی، ممکن است فرد فکر کند که هرچه هوش مصنوعی اسناد بیشتری را بازیابی کند، پاسخ آن آگاهانهتر خواهد بود. با این حال، تحقیقات اخیر پیچیدگی شگفتانگیزی را نشان میدهد: وقتی صحبت از تغذیه اطلاعات به هوش مصنوعی میشود، گاهی اوقات کمتر، بیشتر است.
اسناد کمتر، پاسخهای بهتر
یک مطالعه جدیدتوسط پژوهشگران دانشگاه عبری اورشلیم بررسی کرد که چگونه تعداداسناد ارائه شده به یک سیستم RAG بر عملکرد آن تأثیر میگذارد. نکته مهم این است که آنها مقدار کل متن را ثابت نگه داشتند - به این معنی که اگر اسناد کمتری ارائه میشد، آن اسناد کمی گسترش مییافتند تا همان طولی را که اسناد بسیار پر میکردند، اشغال کنند. به این ترتیب، هرگونه تفاوت عملکردی را میتوان به کمیت اسناد نسبت داد، نه صرفاً داشتن ورودی کوتاهتر.
پژوهشگران از یک مجموعه داده پرسش و پاسخ (MuSiQue) با سؤالات اطلاعات عمومی استفاده کردند که هر کدام در ابتدا با ۲۰ پاراگراف ویکیپدیا جفت شده بودند (که فقط تعداد کمی از آنها واقعاً حاوی پاسخ هستند و بقیه عوامل حواسپرتی هستند). با کاهش تعداد اسناد از ۲۰ به تنها ۲ تا ۴ سند واقعاً مرتبط - و پر کردن آنها با کمی زمینه اضافی برای حفظ طول ثابت - سناریوهایی ایجاد کردند که در آن هوش مصنوعی مواد کمتری برای بررسی داشت، اما همچنان تقریباً همان تعداد کل کلمات را برای خواندن در اختیار داشت.
نتایج چشمگیر بود. در بیشتر موارد، مدلهای هوش مصنوعی زمانی که اسناد کمتری به جای مجموعه کامل به آنها داده میشد، دقیقتر پاسخ میدادند. عملکرد به طور قابل توجهی بهبود یافت - در برخی موارد تا ۱۰٪ در دقت (امتیاز F1) زمانی که سیستم فقط از تعداد انگشت شماری از اسناد پشتیبان به جای مجموعه بزرگ استفاده میکرد. این افزایش غیرمنتظره در چندین مدل زبانی منبع باز مختلف، از جمله انواع Llama متا و دیگران، مشاهده شد که نشان میدهد این پدیده به یک مدل هوش مصنوعی واحد وابسته نیست.
یک مدل (Qwen-2) استثنای قابل توجهی بود که چندین سند را بدون افت امتیاز مدیریت کرد، اما تقریباً تمام مدلهای آزمایش شده در کل با اسناد کمتر عملکرد بهتری داشتند. به عبارت دیگر، افزودن مواد مرجع بیشتر فراتر از قطعات کلیدی مرتبط، بیشتر به عملکرد آنها آسیب میرساند تا اینکه کمک کند.
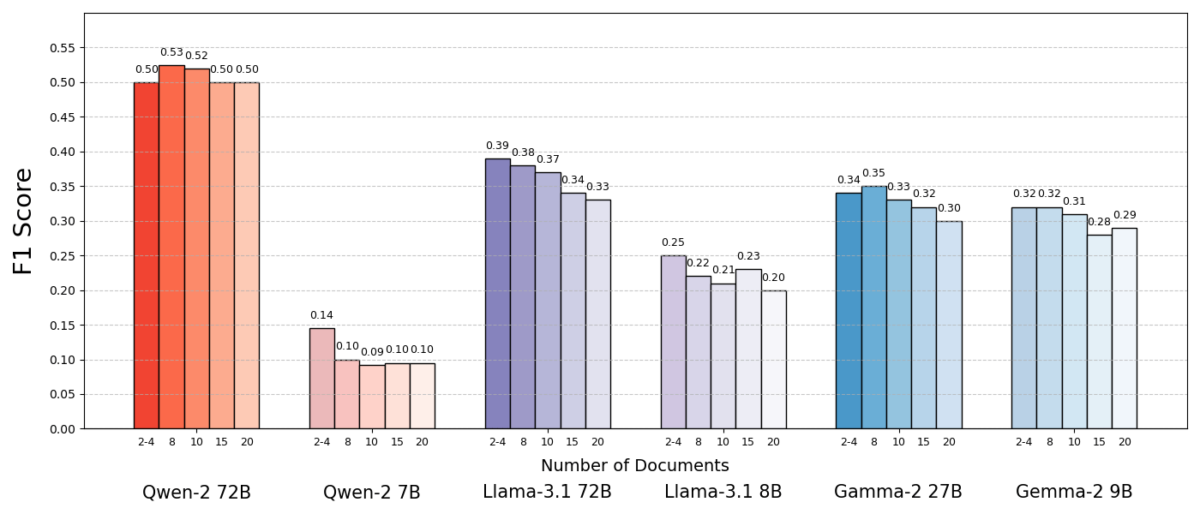
چرا اینقدر تعجب آور است؟ به طور معمول، سیستمهای RAG تحت این فرض طراحی میشوند که بازیابی بخش وسیعتری از اطلاعات فقط میتواند به هوش مصنوعی کمک کند - بالاخره، اگر پاسخ در چند سند اول نباشد، ممکن است در سند دهم یا بیستم باشد.
این مطالعه این تصور را زیر و رو میکند و نشان میدهد که انباشتن بیرویه اسناد اضافی میتواند نتیجه معکوس داشته باشد. حتی زمانی که طول کل متن ثابت نگه داشته شد، صرف وجود اسناد مختلف (هر کدام با زمینه و ویژگیهای خاص خود) کار پرسش و پاسخ را برای هوش مصنوعی چالشبرانگیزتر کرد. به نظر میرسد که فراتر از یک نقطه خاص، هر سند اضافی بیشتر از سیگنال، نویز وارد میکند، مدل را گیج میکند و توانایی آن را در استخراج پاسخ صحیح مختل مینماید.
چرا کمتر میتواند در RAG بیشتر باشد
این نتیجه "کمتر، بیشتر است" زمانی منطقی به نظر میرسد که نحوه پردازش اطلاعات توسط مدلهای زبانی هوش مصنوعی را در نظر بگیریم. هنگامی که به هوش مصنوعی فقط مرتبطترین اسناد داده میشود، زمینهای که میبیند متمرکز و عاری از حواسپرتی است، بسیار شبیه به دانشآموزی که فقط صفحات مناسب برای مطالعه به او داده شده است.
در این مطالعه، مدلها زمانی که فقط اسناد پشتیبان به آنها داده میشد و مطالب نامربوط حذف میشد، عملکرد بهتری داشتند. زمینه باقیمانده نه تنها کوتاهتر بلکه تمیزتر نیز بود - حاوی حقایقی بود که مستقیماً به پاسخ اشاره میکرد و نه هیچ چیز دیگر. با داشتن اسناد کمتری برای مدیریت، مدل میتوانست تمام توجه خود را به اطلاعات مربوطه معطوف کند و احتمال منحرف شدن یا گیج شدن آن کمتر بود.
از سوی دیگر، هنگامی که اسناد زیادی بازیابی میشد، هوش مصنوعی باید ترکیبی از محتوای مرتبط و نامربوط را غربال میکرد. اغلب این اسناد اضافی "مشابه اما نامربوط" بودند - ممکن است موضوع یا کلمات کلیدی مشترکی با پرسش داشته باشند اما در واقع حاوی پاسخ نباشند. چنین محتوایی میتواند مدل را گمراه کند. هوش مصنوعی ممکن است تلاش خود را برای اتصال نقاط بین اسنادی که در واقع به پاسخ صحیح منجر نمیشوند، هدر دهد، یا بدتر از آن، ممکن است اطلاعات را از منابع متعدد به اشتباه ادغام کند. این امر خطر توهمات را افزایش میدهد - مواردی که هوش مصنوعی پاسخی را تولید میکند که قابل قبول به نظر میرسد اما در هیچ منبع واحدی ریشه ندارد.
در اصل، تغذیه بیش از حد اسناد به مدل میتواند اطلاعات مفید را رقیق کرده و جزئیات متناقضی را معرفی کند و تصمیمگیری در مورد صحت مطالب را برای هوش مصنوعی دشوارتر سازد.
جالب توجه است که پژوهشگران دریافتند اگر اسناد اضافی آشکارا نامربوط باشند (به عنوان مثال، متن تصادفی نامربوط)، مدلها در نادیده گرفتن آنها بهتر عمل میکردند. مشکل واقعی از دادههای منحرفکنندهای ناشی میشود که مرتبط به نظر میرسند: وقتی همه متون بازیابی شده در مورد موضوعات مشابه هستند، هوش مصنوعی فرض میکند که باید از همه آنها استفاده کند و ممکن است در تشخیص اینکه کدام جزئیات واقعاً مهم هستند، دچار مشکل شود. این با مشاهده مطالعه مطابقت دارد کهعوامل حواسپرتی تصادفی نسبت به عوامل حواسپرتی واقعی باعث سردرگمی کمتری شدنددر ورودی. هوش مصنوعی میتواند مزخرفات آشکار را فیلتر کند، اما اطلاعات نامربوط ظریف یک تله ماهرانه است - تحت پوشش ارتباط پنهان میشود و پاسخ را منحرف میکند. با کاهش تعداد اسناد به موارد واقعاً ضروری، از ایجاد این تلهها در وهله اول جلوگیری میکنیم.
همچنین یک مزیت عملی وجود دارد: بازیابی و پردازش اسناد کمتر، سربار محاسباتی را برای یک سیستم RAG کاهش میدهد. هر سندی که وارد میشود باید تجزیه و تحلیل شود (تعبیه، خوانده و توسط مدل مورد توجه قرار گیرد)، که از زمان و منابع محاسباتی استفاده میکند. حذف اسناد اضافی سیستم را کارآمدتر میکند - میتواند پاسخها را سریعتر و با هزینه کمتر پیدا کند. در سناریوهایی که دقت با تمرکز بر منابع کمتر بهبود یافته است، به یک برد-برد دست مییابیم: پاسخهای بهتر و فرآیندی کارآمدتر و بهینهتر.

بازاندیشی در RAG: مسیرهای آینده
این شواهد جدید مبنی بر اینکه کیفیت اغلب بر کمیت در بازیابی غلبه میکند، پیامدهای مهمی برای آینده سیستمهای هوش مصنوعی دارد که به دانش خارجی متکی هستند. این نشان میدهد که طراحان سیستمهای RAG باید فیلتر کردن هوشمند و رتبهبندی اسناد را بر حجم محض اولویت دهند. به جای واکشی ۱۰۰ قطعه ممکن و امید به اینکه پاسخ در جایی در آنجا پنهان شده باشد، ممکن است عاقلانهتر باشد که فقط چند مورد برتر بسیار مرتبط را واکشی کنیم.
نویسندگان مطالعه بر لزوم روشهای بازیابی برای "ایجاد تعادل بین ارتباط و تنوع" در اطلاعاتی که به یک مدل ارائه میدهند، تأکید میکنند. به عبارت دیگر، ما میخواهیم پوشش کافی از موضوع را برای پاسخ به سؤال فراهم کنیم، اما نه آنقدر که حقایق اصلی در دریایی از متن اضافی غرق شوند.
در آینده، پژوهشگران احتمالاً تکنیکهایی را بررسی خواهند کرد که به مدلهای هوش مصنوعی کمک میکند تا چندین سند را با ظرافت بیشتری مدیریت کنند. یک رویکرد، توسعه سیستمهای بازیابی بهتر یا رتبهبندی مجدد است که میتواند تشخیص دهد کدام اسناد واقعاً ارزش افزوده دارند و کدامها فقط تضاد ایجاد میکنند. زاویه دیگر، بهبود خود مدلهای زبانی است: اگر یک مدل (مانند Qwen-2) توانست با اسناد زیادی بدون از دست دادن دقت کنار بیاید، بررسی نحوه آموزش یا ساختار آن میتواند سرنخهایی برای مقاومتر کردن سایر مدلها ارائه دهد. شاید مدلهای زبانی بزرگ آینده مکانیسمهایی را برای تشخیص اینکه دو منبع یک چیز را میگویند (یا با یکدیگر تناقض دارند) و بر اساس آن تمرکز کنند، در خود جای دهند. هدف این خواهد بود که مدلها بتوانند از طیف گستردهای از منابع بدون افتادن در دام سردرگمی استفاده کنند - و به طور مؤثر بهترینهای هر دو جهان (وسعت اطلاعات و وضوح تمرکز) را به دست آورند.
همچنین شایان ذکر است که با افزایش پنجرههای زمینه بزرگتر سیستمهای هوش مصنوعی(توانایی خواندن متن بیشتر به یکباره)، صرفاً ریختن دادههای بیشتر در اعلان، یک راهحل جادویی نیست. زمینه بزرگتر به طور خودکار به معنای درک بهتر نیست. این مطالعه نشان میدهد که حتی اگر یک هوش مصنوعی بتواند به لحاظ فنی ۵۰ صفحه را در یک زمان بخواند، دادن ۵۰ صفحه اطلاعات با کیفیت مختلط ممکن است نتیجه خوبی به همراه نداشته باشد. مدل همچنان از داشتن محتوای منتخب و مرتبط برای کار کردن بهره میبرد، نه یک تخلیه بیرویه. در واقع، بازیابی هوشمند ممکن است در عصر پنجرههای زمینه غولپیکر حتی حیاتیتر شود - تا اطمینان حاصل شود که ظرفیت اضافی برای دانش ارزشمند به جای نویز استفاده میشود.
یافتههای مقاله«اسناد بیشتر، طول یکسان»(عنوان مناسب مقاله) بازنگری در مفروضات ما در تحقیقات هوش مصنوعی را تشویق میکند. گاهی اوقات، تغذیه تمام دادههایی که داریم به هوش مصنوعی آنقدر که فکر میکنیم مؤثر نیست. با تمرکز بر مرتبطترین قطعات اطلاعات، نه تنها دقت پاسخهای تولید شده توسط هوش مصنوعی را بهبود میبخشیم، بلکه سیستمها را کارآمدتر و قابل اعتمادتر میکنیم. این یک درس غیرمنتظره است، اما درسی با پیامدهای هیجانانگیز: سیستمهای RAG آینده ممکن است با انتخاب دقیق اسناد کمتر و بهتر، هم هوشمندتر و هم بهینهتر باشند.