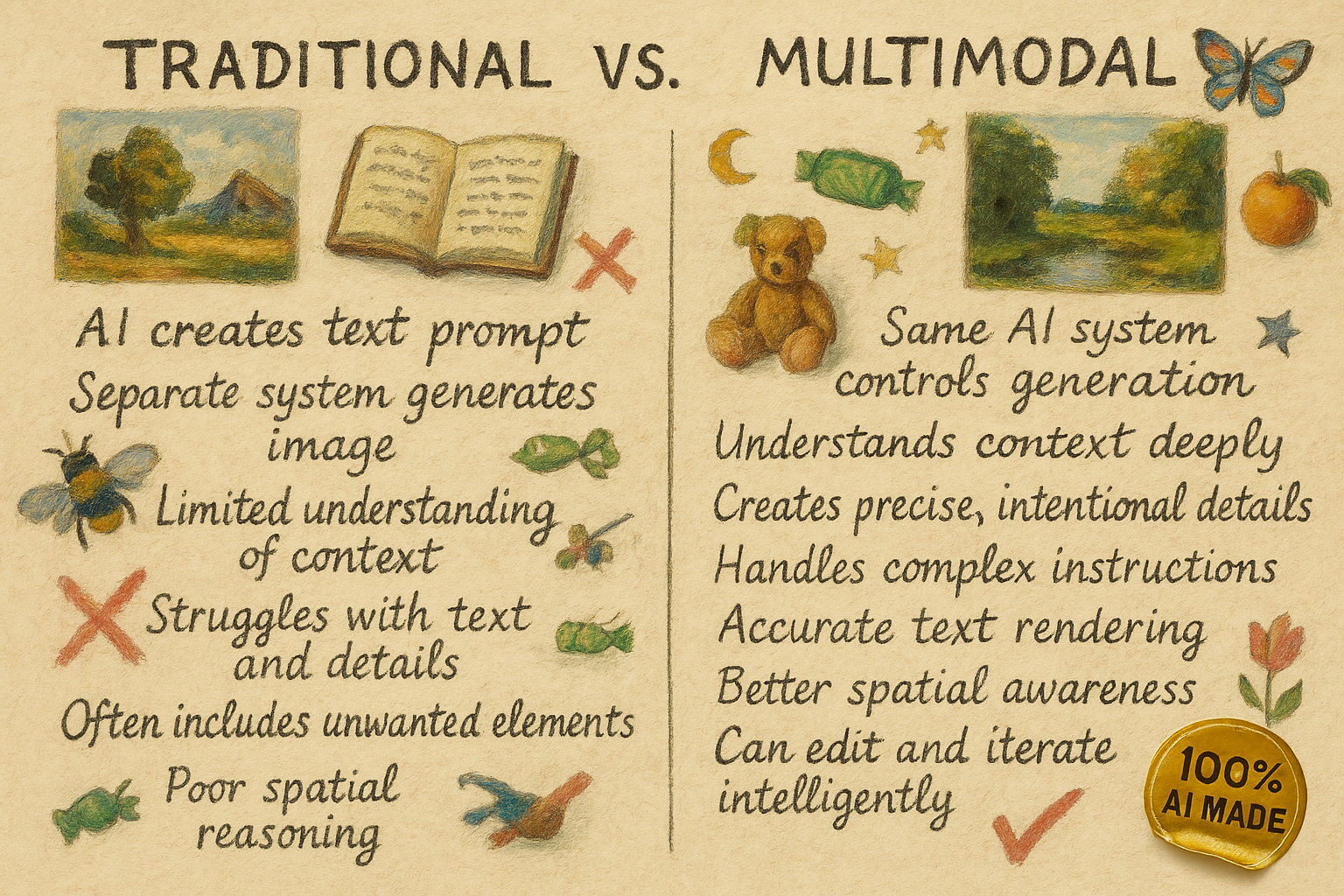
طی دو هفته گذشته، ابتدا گوگل و سپس OpenAI قابلیتهای تولید تصویر چندوجهی خود را عرضه کردند. این اتفاق بزرگی است. پیش از این، وقتی یک هوش مصنوعی مدل زبان بزرگ (LLM) تصویری تولید میکرد، در واقع این خود LLM نبود که کار را انجام میداد. بلکه هوش مصنوعی یک دستور متنی را به یک ابزار جداگانه تولید تصویر ارسال میکرد و نتیجه برگشتی را به شما نشان میداد. هوش مصنوعی دستور متنی را ایجاد میکرد، اما سیستمی دیگر و با هوش کمتر، تصویر را میساخت. برای مثال، اگر دستور داده میشد «به من اتاقی بدون فیل نشان بده، حتماً تصویر را حاشیهنویسی کن تا به من نشان دهی چرا هیچ فیل ممکنی وجود ندارد»، سیستم تولید تصویر کمهوشتر کلمه «فیل» را چندین بار میدید و آنها را به تصویر اضافه میکرد. در نتیجه، تصاویر تولید شده توسط هوش مصنوعی بسیار متوسط، با متنهای نامفهوم و عناصر تصادفی بودند؛ گاهی سرگرمکننده، اما به ندرت مفید.
از سوی دیگر، تولید تصویر چندوجهی به هوش مصنوعی اجازه میدهد تا مستقیماً تصویری را که ساخته میشود کنترل کند. اگرچه تنوع زیادی وجود دارد (و شرکتها برخی از روشهای خود را مخفی نگه میدارند)، در تولید تصویر چندوجهی، تصاویر به همان روشی که LLMها متن را تولید میکنند، یعنی توکن به توکن، ایجاد میشوند. به جای افزودن کلمات جداگانه برای ساختن یک جمله، هوش مصنوعی تصویر را در قطعات مجزا، یکی پس از دیگری، ایجاد میکند که در نهایت به یک تصویر کامل تبدیل میشوند. این به هوش مصنوعی امکان میدهد تصاویر بسیار تأثیرگذارتر و دقیقتری خلق کند. نه تنها تضمین میشود که فیلی وجود نخواهد داشت، بلکه نتایج نهایی این فرآیند خلق تصویر، بازتابدهنده هوشمندی «تفکر» LLM و همچنین نوشتار واضح و کنترل دقیق است.

در حالی که پیامدهای این مدلهای تصویر جدید گسترده است (و بعداً به برخی مسائل اشاره خواهم کرد)، ابتدا بیایید با چند مثال بررسی کنیم که این سیستمها واقعاً چه کاری میتوانند انجام دهند.
دستوردهی (Prompting)، اما برای تصاویر
در کتابم و در بسیاری از پستها، توضیح دادهام که یک راه مفید برای دستور دادن به هوش مصنوعی این است که با آن مانند یک شخص رفتار کنیم، حتی اگر اینطور نباشد. دادن دستورالعملهای واضح، بازخورد در حین تکرار، و زمینه مناسب برای تصمیمگیری، همگی به انسانها کمک میکنند و به هوش مصنوعی نیز کمک میکنند. قبلاً، این کاری بود که فقط با متن میشد انجام داد، اما اکنون میتوان آن را با تصاویر نیز انجام داد.
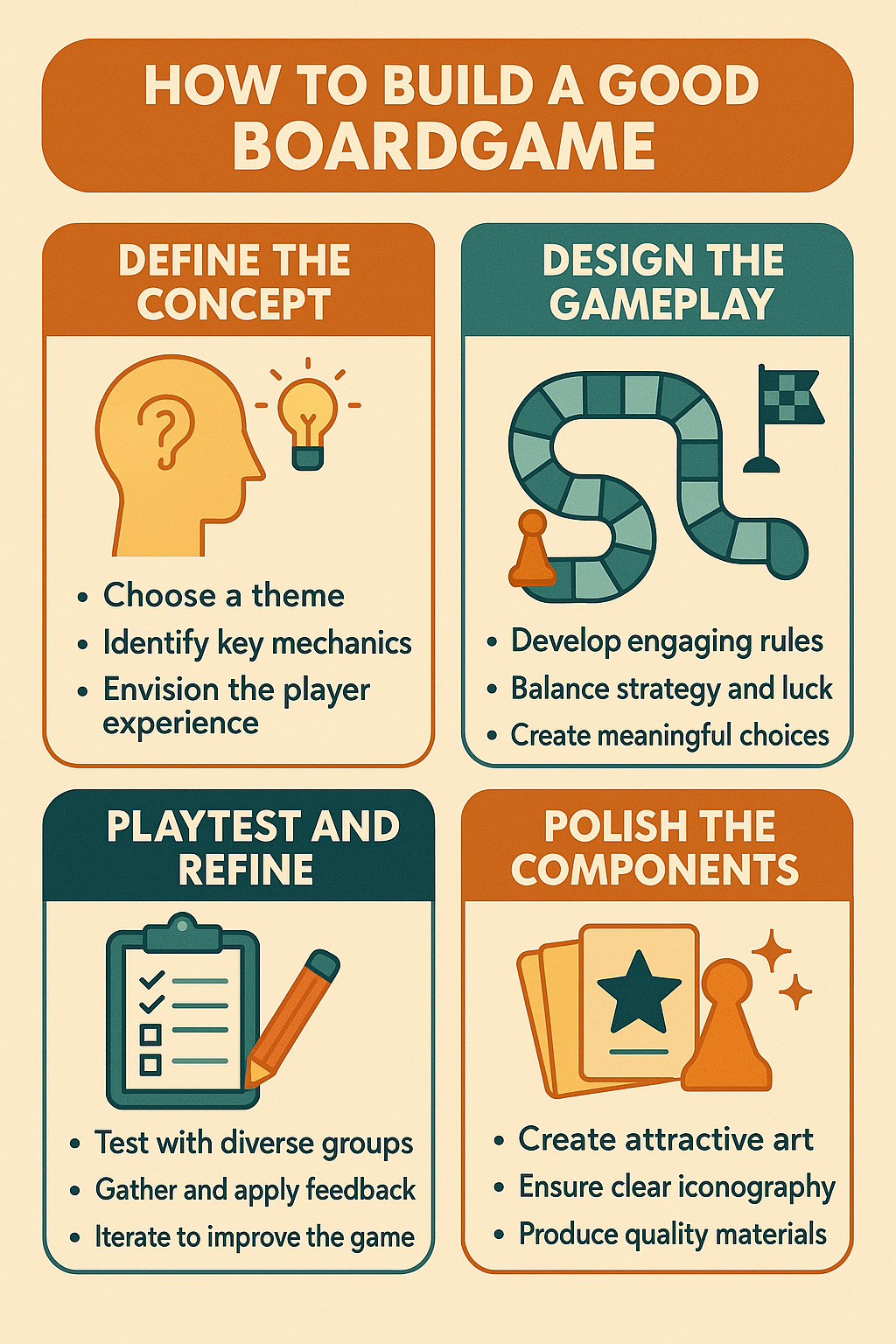
برای مثال، من به GPT-4o دستور دادم «یک اینفوگرافیک درباره نحوه ساخت یک بازی رومیزی خوب ایجاد کن.» با تولیدکنندگان تصویر قبلی، این منجر به نتایج بیمعنی میشد، زیرا هوشی برای هدایت تولید تصویر وجود نداشت و کلمات و تصاویر مخدوش میشدند. اکنون، در همان اولین تلاش، یک پیشنویس خوب دریافت میکنم. با این حال، من زمینهای در مورد آنچه به دنبالش بودم یا محتوای اضافی ارائه نکردم، بنابراین هوش مصنوعی تمام انتخابهای خلاقانه را انجام داد. اگر بخواهم آن را تغییر دهم چطور؟ بیایید امتحان کنیم.

ابتدا، از آن خواستم «گرافیکها را به جای آن، فوقالعاده واقعگرایانه کن» و میتوانید ببینید که چگونه مفاهیم پیشنویس اولیه را گرفت و ظاهر آنها را بهروز کرد. تغییرات بیشتری میخواستم: «میخواهم رنگها کمتر خاکی باشند و بیشتر شبیه فلز بافتدار باشند، بقیه چیزها را همانطور نگه دار، همچنین مطمئن شو که متنهای نقطهای کوچک روشنتر باشند تا خواندنشان آسانتر شود.» ظاهر جدید را دوست داشتم، اما متوجه شدم خطایی رخ داده است، کلمه «Define» به «Definc» تبدیل شده بود - نشانهای از اینکه این سیستمها، هرچقدر هم خوب باشند، هنوز به کمال نزدیک نیستند. دستور دادم «کلمه Define را به صورت Definc نوشتهای، لطفاً اصلاح کن» و خروجی معقولی گرفتم.

اما نکته جذاب در مورد این مدلها این است که قادر به تولید تقریباً هر تصویری هستند: «این اینفوگرافیک را در دستان یک سمور آبی قرار بده که جلوی یک آتشفشان ایستاده است، باید شبیه یک عکس باشد و انگار سمور آبی این را روی یک لوح فلزی حک شده نگه داشته است»
اینجاست که همه چیز جالب میشود. اینها ابزارهای بسیار توانمندی هستند.
اما…
بدیهی است که این توانایی جدید، سوالات جدیدی را مطرح میکند. به طور خاص، من به اینها فکر میکنم:
- مجوز و حقوق تصویر: چه اتفاقی میافتد اگر به یک هوش مصنوعی دستور دهید که «دقیقاً مانند استایل X» یا «شخصیت Y» را ارائه دهد؟ قبلاً با متن مشکلی نداشت، اما تصاویر جدید دقیقاً همان چیزها را تکرار میکنند. چه کسی مسئول است؟
- شناسایی محتوا: برای محتوای ویدیویی یا متنی، شناسایی اینکه چه چیزی توسط هوش مصنوعی ایجاد شده آسانتر است، اما با این تولیدکنندههای جدید تصویر، انجام این کار بسیار سختتر است. چطور میتوانیم حقیقت را از داستان تشخیص دهیم؟
- تأثیر خلاقیت انسانی: من فکر میکنم در نهایت به سمتی پیش میرویم که انسانها دستور میدهند و هوش مصنوعی آن را ایجاد میکند. چطور انسانها را در این فرآیند سهیم کنیم و به آنها کمک کنیم یاد بگیرند که چگونه به سیستمهای هوش مصنوعی آموزش دهند؟
- کنترل: واضح است که OpenAI و Google محافظتهای زیادی را در سیستمهای خود ایجاد کردهاند، به ویژه در رابطه با تولید تصاویر سمی. با این حال، این چیزی است که به صورت مستمر در حال تغییر است. چه کسی این سیستمها را کنترل میکند و چگونه مطمئن شویم که این کار به روشی که اکثریت موافق آن هستند انجام میشود؟
هیجانانگیزترین چیز در مورد هوش مصنوعی این نیست که میتوانیم انجام دهیم، بلکه باید انجام دهیم.