

پژوهشگران میدجرنی (Midjourney) و دانشگاه نیویورک رویکرد جدیدی را توسعه دادهاند که میتواند به مدلهای زبان کمک کند تا متون خلاقانه متنوعتری تولید کنند بدون آنکه کیفیت به طور قابل توجهی کاهش یابد.
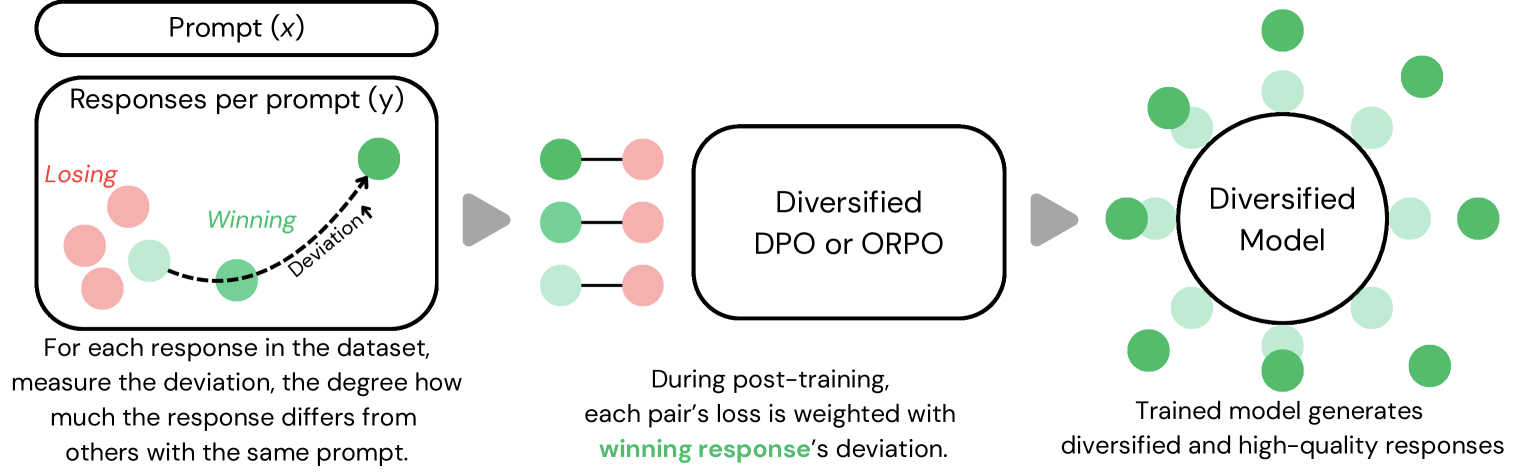
در مقالهای که اخیراً منتشر شده است، این تیم «معیارهای انحراف» (deviation metrics) را در فرآیند آموزش هوش مصنوعی معرفی میکند. این روش با اندازهگیری میزان تفاوت هر متن تولید شده با سایر متون ایجاد شده برای همان دستور (prompt)، کار میکند. این تفاوتها با استفاده از متون جاسازی شده (embedded texts) و فاصله کسینوسی زوجی آنها (pairwise cosine distance) محاسبه میشوند – اساساً روشی ریاضی برای درک تنوع متنی به سیستم ارائه میدهد.
آزمایشهای اولیه امیدوارکننده به نظر میرسند. مدلهایی که از این روش آموزشی جدید استفاده کردند، ۲۳ درصد متون متنوعتری تولید کردند، در حالی که امتیازات کیفیت طبق سیستم پاداش Reddit تنها پنج درصد کاهش یافت.
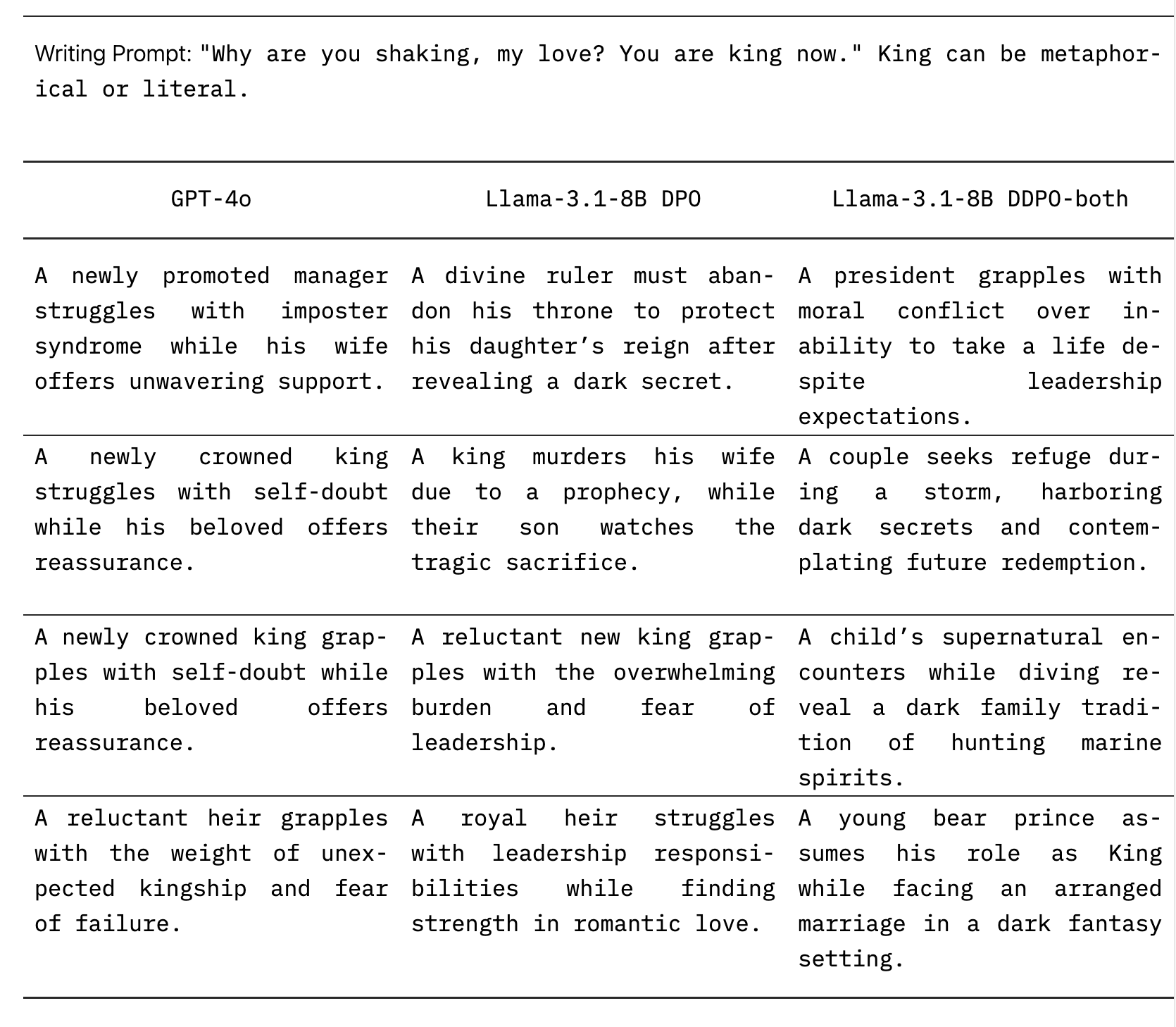
یک مورد آزمایشی نشان میدهد که این روش در عمل چگونه کار میکند. هنگامی که دستور «چرا میلرزی، عشق من؟ اکنون تو پادشاهی» به مدل استاندارد GPT-4o داده شد، عمدتاً به داستانهایی درباره فرمانروایان جدید عصبی پرداخت. مدل اصلاح شده Llama-3.1-8B، علیرغم کوچکتر بودن، همه چیز از داستانهای فانتزی تاریک درباره شاهزادگان خرس گرفته تا داستانهای فراطبیعی در زیر آب را تولید کرد.
آزمایشکنندگان انسانی نیز این یافتهها را تأیید کردند و گفتند که متون ضمن حفظ کیفیت، تنوع بیشتری نشان میدهند. با این حال، پژوهشگران فقط با مدل قدیمیتر GPT-4o آزمایش کردند، نه مدل جدیدتر GPT-4.5 که متنی با صدای طبیعیتر تولید میکند اما هزینه استفاده از آن بیشتر است.
دو نوع تنوع
پژوهشگران بر دو نوع تنوع تمرکز کردند: معنایی (محتوا و طرحهای داستانی متفاوت) و سبکی (نوشتاری که به نظر میرسد از نویسندگان مختلفی آمده است). آنها نسخههای خاصی برای هر نوع توسعه دادند اما دریافتند که ترکیب آنها بهترین نتیجه را میدهد.
برای پژوهش خود، تیم از بیش از ۱۰۰,۰۰۰ جفت دستور-پاسخ از انجمن r/WritingPrompts در Reddit استفاده کرد. آنها دریافتند که تنها با چهار پاسخ متفاوت برای هر دستور میتوانند به تنوع بسیار بهتری دست یابند.
این سیستم میتواند با استفاده از نمونههای آموزشی با دقت انتخاب شده یا تعیین استانداردهای حداقلی برای میزان تفاوت پاسخها، کیفیت را حفظ کند. این امر آن را نسبت به سایر روشهای افزایش تنوع خروجی، انعطافپذیرتر میکند.
برخی سوالات هنوز بیپاسخ ماندهاند. پژوهشگران هنوز نشان ندادهاند که آیا روش آنها فراتر از نوشتار خلاق عمل میکند یا خیر - مستندات فنی و خلاصهها ممکن است به رویکردهای متفاوتی نیاز داشته باشند. اثربخشی این تکنیک در محیطهای آموزشی آنلاین، که بسیاری از مدلهای بزرگ از آن استفاده میکنند، نیز آزمایش نشده است.
خود سیستم اندازهگیری کیفیت نیز سوالاتی را ایجاد میکند. در حالی که رأیهای مثبت Reddit بینشی در مورد کیفیت متن ارائه میدهند، عوامل مهمی مانند دقت فنی، انسجام و استانداردهای نوشتاری حرفهای را نادیده میگیرند. این محدودیتها نشان میدهد که ممکن است به روشهای ارزیابی جامعتری نیاز باشد.
حتی با وجود این پرسشهای باز، این تکنیک میتواند نحوه برخورد مدلهای زبان بزرگ با وظایف نوشتار خلاق را تغییر دهد، جایی که مدلهای فعلی اغلب در الگوهای تکراری گرفتار میشوند. پژوهشگران میگویند که کد خود را در GitHub به اشتراک خواهند گذاشت تا دیگران بتوانند بر اساس کار آنها پیشرفت کنند.