دنیای سازمانی در آستانه یک تحول بنیادین قرار دارد و من معتقدم که ما عمق این تحول را دستکم گرفتهایم. طی ماه گذشته، من به دریافتهای ناگهانی متعددی درباره هوش مصنوعی مولد، گرافهای دانش و عاملهای هوش مصنوعی رسیدهام. آنچه اکنون میبینم، بازآفرینی یکی از بنیادیترین شیوههای مدیریتی است: یادگیری و بهبود مستمر.
مدلهای کلاسیک بهبود مستمر مانند دمینگ و ژوران با هدف پیشبرد چرخههای پیشرفت از طریق اندازهگیری و بازخورد طراحی شده بودند و در تاریخ گسترده مدیریت، سهم عظیمی در پیشرفت داشتند. اما بیایید صادق باشیم: در بسیاری از سازمانها، این مدلها به تشریفات بوروکراتیک تنزل یافتند. بهبود مستمر به یک بخش، یک جعبهابزار تبدیل شد، نه یک روش کار و بودن. حلقههای بازخورد شکسته شد. دادهها کهنه شدند. بینشها، صوری و سطحی بودند. هیجان از بین رفت.
اکنون این وضعیت تغییر میکند.
گشودن قفل دانش شما سرانجام ممکن میشود
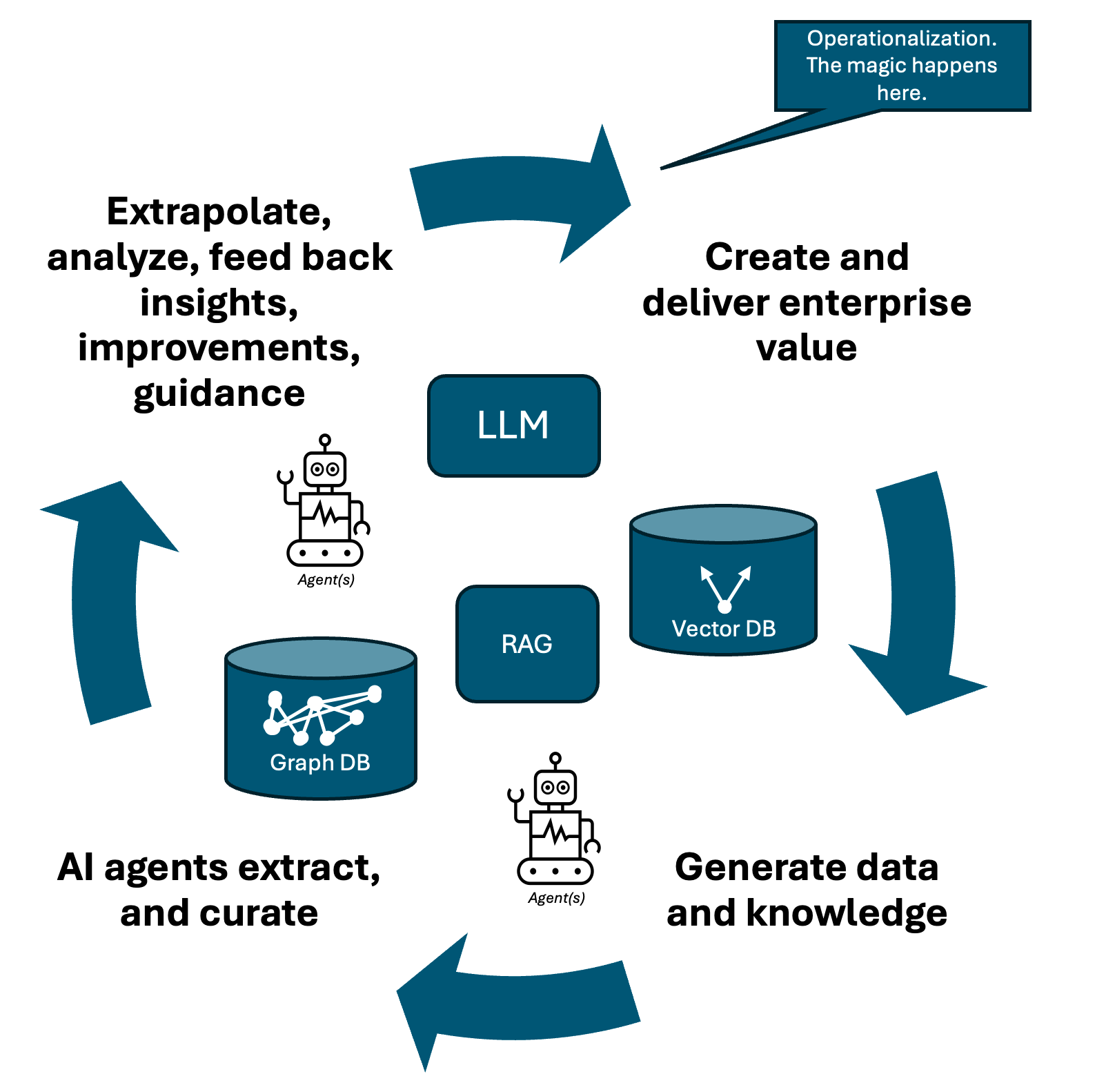
ما شاهد ظهور مجدد یادگیری و بهبود مستمر در مقیاس سازمانی هستیم، اما این بار، این فرآیند با هوش مصنوعی تقویت شده، از طریق عاملها عملیاتی شده، در گرافها ساختار یافته و با تلهمتری زنده غنی شده است.
شرکت مدرن را به عنوان یک ارگانیسم تصور کنید که دائماً خروجی دیجیتال تولید میکند: تراکنشها، گزارشها، مصنوعات، اسناد، کد منبع، لاگها، هشدارها، رشتههای همکاری، تیکتهای خدمات. این خروجی، به دور از اینکه زباله باشد، پتانسیل ناگفتهای برای تقویت نوآوری، رشد و یادگیری مستمر دارد. با این حال، برای دههها، ما فاقد ابزاری بودیم که این سیل اطلاعات را به دانشی منسجم، قابل اعتماد و عملیاتیشده تبدیل کنیم. مدیریت دانش تلاش کرد آن را مهار کند، اما زیر بار سنگین مدیریت دستی، قالبهای سیلو شده و تعامل ضعیف، با مشکل مواجه شد.
با همگرایی هوش مصنوعی مولد، تولید افزوده بازیابی (RAG)، گرافهای دانش و عاملهای خودکار، ما در لبه یک دوره جدید ایستادهایم.
چرا اکنون کار میکند
حلقه بازخورد جدید به طور اساسی متفاوت است. به این شکل است:
- عملیات سازمانی مانند همیشه ادامه مییابد: مجموعههای عظیمی از پیچیدگیهای دیجیتال و فیزیکی.
- آنها داده و اطلاعات تولید میکنند: سوابق فعالیت، ساختاریافته یا بدون ساختار.
- عاملهای هوش مصنوعی برداشتکننده (که توسط مدلهای زبان بزرگ [LLM] توانمند شدهاند) اطلاعات را در زمان واقعی مشاهده و تفسیر میکنند و آن را به یک گراف معنایی ساختار داده و مدیریت میکنند. اطلاعات متصل و بدون ساختار به بردارهای جاسازی شده در یک پایگاه داده برداری ترجمه میشوند.* آنها کیفیت، رانش معنایی، شکافهای همراستایی، الگوهای نوظهور و ناشناختههای ناشناخته را پایش میکنند و دادههای خام را برای سنتز و تحلیل به LLMها تغذیه میکنند.
- عاملهای عملیاتی به طور مداوم گراف و بردارها را تجزیه و تحلیل میکنند، اطلاعات جدید را با اطلاعات قبلی مقایسه میکنند، دانش را زنده و قابل اجرا میسازند — و آن را به مرحله اول بازخورد میدهند.
و برخلاف تحلیلگران انسانی، عاملها خسته نمیشوند. شما میتوانید دهها عامل در حال اجرا داشته باشید که دائماً بینشها را آشکار میکنند، به دنبال تناقضات هستند، الگوهای گذشته را با ناهنجاریهای فعلی مقایسه میکنند و اقداماتی را پیشنهاد میدهند. آنها جایگزین قضاوت نمیشوند — بلکه سرانجام بازخورد مرتبط و مستمر را واقعی میسازند. کنترل و بهبود این عاملها یک وظیفه مهم خواهد بود؛ انسانها با TuringBots (موتورهای کدنویسی مبتنی بر LLM) برای تکامل مداوم آنها همکاری خواهند کرد.
این فقط مربوط به فناوری اطلاعات نیست
برای روشن شدن موضوع، این امر فراتر از IT کاربرد دارد. صنعت IT — جایی که Forrester ظهور یک معماری صفحه کنترل جدید را مستند کرده است — و تلهمتری آن از قبل غنی و دیجیتالی شده است، بنابراین برای بهرهمندی از این مزایای جدید بسیار مناسب است. فروشندگانی مانند ServiceNow، Atlassian و Wiz در حال حاضر گرافهای مقیاس بزرگ را پیادهسازی میکنند. اما هر بخشی در سازمان میتواند شروع به حرکت به سمت یادگیری مبتنی بر گراف و فعالشده توسط عامل کند: فروش، بازاریابی، تحقیق و توسعه، منابع انسانی، مالی، ریسک، زنجیره تأمین، خدمات مشتری و غیره. هر حوزهای که کار قابل ردیابی تولید میکند، میتواند از آن بهرهمند شود.
چرا گرافها ضروری هستند
وسوسهانگیز است که فکر کنیم LLMها به تنهایی میتوانند این مشکل را حل کنند. اما متوجه میشویم که بدون ساختار، هوش مصنوعی مولد به تنهایی دچار انحراف میشود. گراف ضروری است. این اسکلت برای گوشت LLM است. گرافها به عاملها اجازه میدهند:
- وابستگیها را در بین دامنهها ردیابی کنند.
- روابط در حال تکامل را نشان دهند (قابلیتهای نسخهبندی شده، مالکیت در حال تغییر، بازارهای پویا).
- شباهت و رانش معنایی را شناسایی کنند.
- استدلال در طول زمان را فعال کنند.
ما میتوانیم از تلقی مدیریت دانش به عنوان یک مخزن ایستا دست برداریم و به جای آن، آن را به عنوان یک سیستم زنده، قابل پیمایش و خودترمیمشونده ببینیم. متفکران سیستمی میدانند که هیچ چیز قدرتمندتر از یک حلقه بازخورد تقویتی واقعی («مثبت») نیست. من معتقدم که این امر اکنون در حال شکلگیری است و حلقههای بازخورد عمده جدید در اقتصاد چندان مکرر ظاهر نمیشوند — «اثر شبکهای» که در روزهای اولیه اینترنت مشاهده شد، بارزترین مقایسه است. بله، پویاییهای متعادلکنندهای وجود خواهد داشت: امنیت، حریم خصوصی — اما بیشتر آنچه در اینجا در مورد آن صحبت میکنم میتواند در مرزهای یک شرکت رخ دهد، با این فرض که بتواند LLMهای مقیاس بزرگ خود را اجرا کند. آزمایشهای زیادی وجود خواهد داشت. آیا عاملها به عنوان مشاور عمل میکنند؟ تنظیمکنندهها؟ پلیس راهنمایی و رانندگی؟ حسابرسان؟ قاضی و هیئت منصفه … ؟ مردم همه اینها را امتحان خواهند کرد. (ما به ابزارهای تخصیص مسئولیت برای عاملها نیاز خواهیم داشت … حقوق تصمیمگیری عاملی، برای ابداع یک اصطلاح جدید، یک چالش جدید تحلیل کسبوکار خواهد بود.)
پیامدها برای سازمان
- معماران سازمانی و مدیران ارشد اطلاعات باید در مورد سیستمهای دانش بازنگری کنند نه به عنوان سیستمهای مبتنی بر فرم یا سند محور، بلکه به عنوان گرافمحور، با اطلاعات بدون ساختار به عنوان یک شهروند عملیاتی درجه یک، همه با تعامل مداوم عامل.
- فروشندگان باید پلتفرمهای یکپارچه با عامل را ارائه دهند که به مشتریان امکان تعریف، گسترش و کنترل مدلهای معنایی خود را میدهد.
- سرمایهگذاران خطرپذیر، خریداران و مشتریان سازمانی باید در بررسیهای دقیق خود به دنبال معماریهای بومی گراف و اکوسیستمهای عامل، و همچنین LLMها و RAG باشند.
- حاکمیت دانش باید برای تطبیق با مدیریت خودکار، نسخهبندی معنایی و اعتبارسنجی بازخورد تکامل یابد.
- هر مدل عملیاتی به یک حلقه بازخورد نیاز دارد که شامل ضبط تلهمتری، تفسیر هوش مصنوعی، غنیسازی گراف و اقدام تحت رهبری عامل باشد.
تشابه تاریخی
شما باید به اوایل قرن بیستم برگردید — به زمان ایجاد مدل عملیاتی شرکت مدرن در جنرال موتورز و دوپونت — تا تغییری به این اهمیت پیدا کنید. در آن زمان، حسابداری و علم مدیریت، سرمایهداری صنعتی را بازسازی کردند. من معتقدم که هوش مصنوعی مولد، عاملها و گرافها تأثیر قابل مقایسهای بر سرمایهداری دیجیتال خواهند داشت.
زمان آن فرا رسیده است که از اشکال شکننده بهبود مستمر که از مدیریت اواسط قرن به ارث بردهایم، فراتر رویم. بیایید روح آن را بازیابیم و به وعدهاش عمل کنیم، با ابزارهایی که سرانجام میتوانند آن را واقعی سازند.
حلقه بازخورد جدید یک نظریه نیست. در حال شروع شدن است. آیا سازمان شما پیشرو خواهد بود یا دنبالهرو؟
*و خود گراف نیز میتواند دارای بردارهای جاسازی شده باشد، اما این بحث عمیق را برای پاورقی نگه میدارم. من در حال انجام کارهای عملی با تمام این فناوریها بودهام و یکی از جالبترین افشاگریها این بود که یک قطعه متن بدون ساختار را به یک مدل زبان بزرگ دادم و از آن خواستم یک کوئری دقیق بهروزرسانی پایگاه داده ایجاد کند — چیزی که دانشگاهیان ممکن است آن را پردازش زبان طبیعی یا استخراج موجودیت، در سطح عملیاتی و کاربردی بنامند. واضح است که فرصتهایی برای کیفیت پایین دادهها و غیره وجود دارد، اما این امر با اپراتورهای انسانی نیز به همان اندازه ممکن است. ما باید کنترلها و حفاظها، بررسی استثنائات پس از وقوع … تمام موارد مربوط به کیفیت داده را اعمال کنیم. اما عاملهای خستگیناپذیری خواهیم داشت که مراقب یکپارچگی دادهها هستند.