
مدلهای زبانی بزرگ (LLM) اغلب در هنگام پاسخ به سؤالات تخصصی، به ویژه آنهایی که نیازمند استدلال چند مرحلهای (multi-hop reasoning) یا دسترسی به دادههای اختصاصی هستند، با مشکل دقت مواجه میشوند. اگرچه تولید افزوده با بازیابی (RAG) میتواند کمککننده باشد، روشهای جستجوی برداری سنتی اغلب کافی نیستند.
در این آموزش، به شما نشان میدهیم که چگونه GraphRAG (تولید افزوده با بازیابی مبتنی بر گراف) را در ترکیب با مدلهای تنظیمشده GNN+LLM پیادهسازی کنید تا به دقتی ۲ برابر بیشتر از خطوط پایه استاندارد دست یابید.
این رویکرد بهویژه برای سناریوهای زیر ارزشمند است:
- دانش تخصصی (کاتالوگ محصولات، زنجیرههای تأمین)
- اطلاعات اختصاصی با ارزش بالا (کشف دارو، مدلهای مالی)
- دادههای حساس به حریم خصوصی (تشخیص تقلب، سوابق بیماران)
نحوه عملکرد GraphRAG
این رویکرد خاص تولید افزوده با بازیابی مبتنی بر گراف (GraphRAG) بر اساس معماری G-Retriever بنا شده است. G-Retriever دادههای پایه را به عنوان یک گراف دانش نشان میدهد که بازیابی مبتنی بر گراف را با پردازش عصبی ترکیب میکند:
- ساخت گراف دانش: نمایش دانش دامنه به عنوان ساختار گراف.
- بازیابی هوشمند: استفاده از کوئریهای گراف و الگوریتم درخت اشتاینر جمعآوریکننده جایزه (Prize-Collecting Steiner Tree - PCST) برای یافتن زیرگرافهای مرتبط.
- پردازش عصبی: ادغام لایههای شبکه عصبی گرافی (GNN) در طول تنظیم دقیق (fine-tuning) مدل زبانی بزرگ (LLM) برای بهینهسازی توجه بر روی زمینه بازیابیشده.
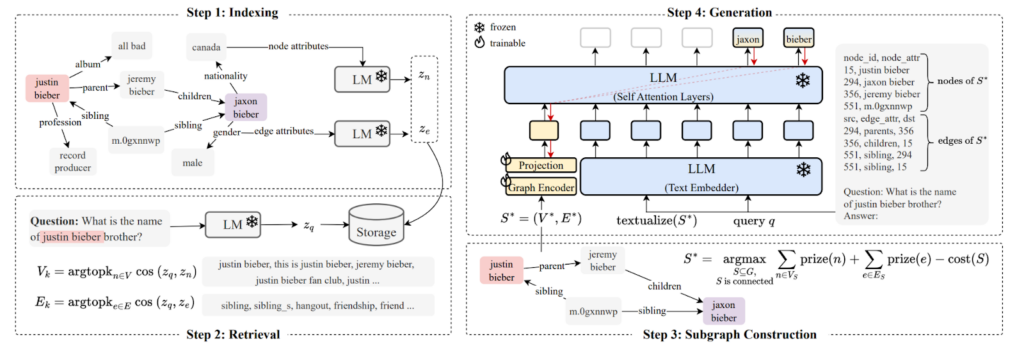
این فرآیند با سهگانههای داده آموزشی {(Qi, Ai, Gi)} کار میکند:
- Qi: سوال چند مرحلهای به زبان طبیعی
- Ai: مجموعهای از گرههای پاسخ
- Gi = (Vi, Ei): زیرگراف مرتبط (که قبلاً با روشی به دست آمده است)
پایپلاین مراحل زیر را دنبال میکند:
- یافتن گرههای Vj ⊆ Vi و یالهای Ej ⊆ Ei که از نظر معنایی به سوال Qi شبیه هستند.
- اختصاص جوایز بالا به این گرهها و یالهای منطبق.
- اجرای یک نوع از الگوریتم PCST برای یافتن زیرگراف بهینه Gi* ⊆ Gi که جایزه را حداکثر و اندازه را حداقل میکند.
- تنظیم دقیق مدل ترکیبی GNN+LLM بر روی جفتهای {(Qi, Gi*)} برای پیشبینی {Ai}.
کتابخانه PyG (PyTorch Geometric) یک تنظیم ماژولار برای G-Retriever ارائه میدهد. مخزن کد ما این را با یک پایگاه داده گرافی برای ذخیرهسازی گرافهای بزرگ و یک شاخص برداری و همچنین ارائه قالبهای کوئری بازیابی، ادغام میکند.
مثال واقعی: پرسش و پاسخ زیستپزشکی
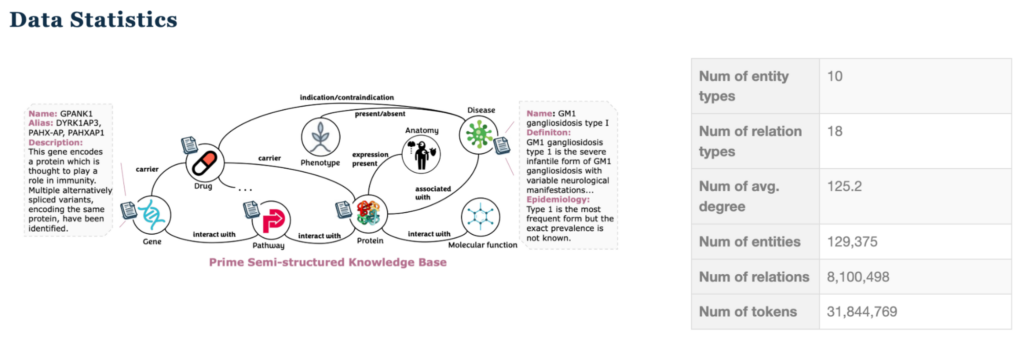
به مجموعه داده زیستپزشکی STaRK-Prime نگاه کنید. این سوال را در نظر بگیرید: «کدام داروها آنزیم CYP3A4 را هدف قرار میدهند و برای درمان استرونژیلوئیدیازیس استفاده میشوند؟»
پاسخ صحیح (ایورمکتین) نیازمند درک موارد زیر است:
- روابط مستقیم (ارتباط دارو-آنزیم، دارو-بیماری)
- ویژگیهای گره (توضیحات و طبقهبندی داروها)

این مجموعه داده به دلیل عوامل زیر بهطور خاص چالشبرانگیز است:
- انواع گره و رابطه ناهمگن
- ویژگیهای متنی با طول متغیر
- درجه متوسط بالای گره که باعث انفجار همسایگی میشود
- الزامات استدلال چند مرحلهای پیچیده
برای دنبال کردن این آموزش، توصیه میکنیم با موارد زیر آشنا باشید:
- پایگاههای داده گرافی: دانش عملی در مورد Neo4j و کوئریهای سایفر (Cypher)
- شبکههای عصبی گرافی (GNN): استفاده اولیه از PyTorch Geometric (PyG)
- مدلهای زبانی بزرگ (LLM): تجربه با تنظیم دقیق (fine-tuning) مدل
- جستجوی برداری: درک تعبیهها (embeddings) و جستجوی شباهت