
در این آموزش، یاد خواهید گرفت که چگونه یک برنامه FastAPI را با OpenAI CLIP، یک مدل قدرتمند برای وظایف تبدیل متن به تصویر و تصویر به متن، ادغام کنید. ما شما را از طریق تولید جاسازیهای تصویر و متن، ایجاد نقاط پایانی مجهز به هوش مصنوعی برای مطابقت دادن تصاویر بر اساس پرسشهای متنی یا تولید توضیحات برای تصاویر آپلود شده، آزمایش API خود با استفاده از رابط کاربری تعاملی Swagger FastAPI، و استقرار برنامه خود با Docker راهنمایی خواهیم کرد. در پایان، شما یک API کاملاً کاربردی خواهید داشت که برای موارد استفاده در دنیای واقعی آماده است.
FastAPI با OpenAI CLIP: ساخت و استقرار با Dockerاین درس آخرین قسمت از یک مجموعه 2 قسمتی در مورد استقرار یادگیری ماشین با استفاده از FastAPI و Docker است:
- شروع به کار با پایتون و FastAPI: راهنمای کامل مبتدیان
- آشنایی با FastAPI و OpenAI CLIP: ساخت و استقرار با Docker (این آموزش)
برای یادگیری نحوه ساخت یک برنامه FastAPI با OpenAI CLIP برای وظایف تبدیل متن به تصویر و تصویر به متن، تولید جاسازیها و استقرار آن با Docker، به خواندن ادامه دهید.
ساخت بر اساس مبانی FastAPI
در درس قبلی، ما پایههای درک و کار با FastAPI را بنا نهادیم. در اینجا خلاصهای سریع از آنچه آموختید آورده شده است:
- مقدمهای بر FastAPI: ما بررسی کردیم که چه چیزی FastAPI را به یک چارچوب وب پایتون مدرن و کارآمد تبدیل میکند، و بر قابلیتهای ناهمزمان، مستندسازی خودکار API و ادغام یکپارچه آن با Pydantic برای اعتبارسنجی دادهها تأکید کردیم.
- راهاندازی و اجرای FastAPI: شما یاد گرفتید که چگونه FastAPI و Uvicorn را نصب کنید، دایرکتوری پروژه خود را راهاندازی کنید و یک سرور اولیه ایجاد کنید.
- نقاط پایانی پایه: ما ایجاد یک نقطه پایانی ساده "Hello, World!"، مدیریت پارامترهای پرس و جو و کار با پارامترهای مسیر برای ساخت مسیرهای پویا را بررسی کردیم.
- روشهای HTTP و آزمایش: شما یک نقطه پایانی POST برای ایجاد یک منبع پیادهسازی کردید و آن را با استفاده از TestClient FastAPI آزمایش کردید.
- مستندسازی تعاملی: ما قدرت رابط کاربری خودکار Swagger و ReDoc FastAPI را برای بررسی و آزمایش APIها به نمایش گذاشتیم.
اکنون با این مهارتهای اساسی، آمادهاید تا به سطح بعدی بروید: ادغام یک مدل یادگیری ماشین در دنیای واقعی در یک برنامه FastAPI.
بعدش چی؟
در این آموزش، یک برنامه FastAPI را با استفاده از OpenAI CLIP (پیش آموزش زبان-تصویر متضاد)، مدلی که برای وظایفی مانند تطبیق متن به تصویر و شرح تصویر طراحی شده است، خواهیم ساخت. همچنین یاد خواهید گرفت که چگونه برنامه خود را با استفاده از Docker کانتینریزه و مستقر کنید، که آن را قابل حمل و به اشتراک گذاری آسان میکند.
در پایان این درس، شما خواهید داشت:
- یک برنامه کاربردی FastAPI با نقاط پایانی برای وظایف تبدیل متن به تصویر و تبدیل تصویر به متن.
- درک قوی از تولید و مدیریت جاسازیها با OpenAI CLIP.
- یک برنامه کانتینریزه شده که برای استقرار در هر محیطی آماده است.
OpenAI CLIP چیست؟
OpenAI CLIP (پیش آموزش زبان-تصویر متضاد) یک مدل هوش مصنوعی چندوجهی پیشگامانه است که توسط OpenAI توسعه یافته است. این مدل با استفاده از فضای نمایش مشترک، شکاف بین متن و تصاویر را پر میکند و آن را قادر میسازد تا توصیفهای متنی را با تصاویر مربوطه مرتبط کند. برخلاف مدلهای سنتی که نیاز به آموزش گسترده و خاص وظیفه دارند، پیش آموزش CLIP آن را قادر میسازد تا طیف گستردهای از وظایف را بدون تنظیم دقیق انجام دهد، که آن را بسیار متنوع میکند.
CLIP با استفاده از یک رمزگذار متن و یک رمزگذار تصویر، در وظایفی مانند شناسایی بهترین تصویر مطابق با یک درخواست متنی یا تولید توصیفهای متنی دقیق برای یک تصویر، برتری دارد. این امر آن را به ابزاری بسیار ارزشمند برای یادگیری صفر شات (zero-shot learning) تبدیل میکند، جایی که مدل میتواند وظایفی را انجام دهد که به طور خاص برای آنها آموزش ندیده است.
OpenAI CLIP چگونه کار میکند: درک تطبیق متن-تصویر و یادگیری متضاد
CLIP از یادگیری متضاد برای همتراز کردن دادههای بصری و متنی در یک فضای جاسازی مشترک استفاده میکند. در طول آموزش، دادههای تصویر و متن جفت شده با استفاده از دو رمزگذار پردازش میشوند: یک رمزگذار متن و یک رمزگذار تصویر. این روش تضمین میکند که جاسازیهای جفتهای تصویر-متن مطابق در کنار هم قرار میگیرند، در حالی که جفتهای نامرتبط از هم دورتر میشوند.
این فرآیند با یک تابع از دست دادن متضاد بهینه میشود، که هم ترازی جفتهای واقعی را تقویت میکند و هم ترازی جفتهای نامتطابق را تضعیف میکند. این فضای جاسازی مشترک CLIP را قادر میسازد تا وظایفی مانند طبقهبندی صفر شات و بازیابی متقابل را بدون تنظیم دقیق اضافی انجام دهد.
CLIP با نگاشت متن و تصاویر به یک فضای برداری یکسان، میتواند به طور کارآمد وظایفی مانند یافتن بهترین تصویر مطابق برای یک درخواست متنی یا تولید توصیفهای متنی دقیق از تصاویر را انجام دهد. این مکانیسم به صورت بصری در نمودار زیر نشان داده شده است.
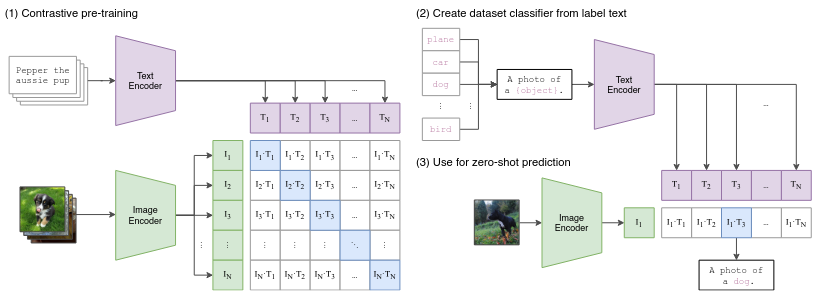
پیش آموزش متضاد: همتراز کردن جاسازیهای متن و تصویر
نوآوری اصلی CLIP در رویکرد یادگیری متضاد آن نهفته است، که به طور مشترک یک رمزگذار متن و یک رمزگذار تصویر را آموزش میدهد تا توصیفهای متنی را با تصاویر مربوطه همتراز کند.
- مجموعه داده آموزشی:
- CLIP بر روی یک مجموعه داده عظیم از جفتهای (تصویر، متن) آموزش داده میشود، مانند "یک سگ در حال دویدن در یک مزرعه" که با تصویری از یک سگ در یک مزرعه جفت شده است.
- دو رمزگذار:
- رمزگذار متن دادههای متنی (به عنوان مثال، "Pepper توله سگ استرالیایی") را پردازش میکند تا جاسازیها، نمایشهای عددی متن را در یک فضای چند بعدی ایجاد کند.
- رمزگذار تصویر تصاویر (به عنوان مثال، عکسی از یک سگ) را پردازش میکند تا جاسازیهای مربوطه را تولید کند.
- یادگیری متضاد:
- در طول آموزش، CLIP از یک تابع از دست دادن متضاد استفاده میکند که جفتهای مثبت (به عنوان مثال، تصویری از یک سگ و توضیحات مطابق آن) را تشویق میکند تا شباهت بالایی در فضای جاسازی داشته باشند.
- به طور همزمان، شباهت بین جفتهای منفی را به حداقل میرساند (به عنوان مثال، تصویری از یک گربه با توضیحات "یک سگ در حال دویدن در یک مزرعه").
- یادگیری صفر شات:
- پس از آموزش، CLIP میتواند تصاویر یا پرسشهای متنی جدید را بدون تنظیم دقیق اضافی طبقهبندی کند. این مدل پرس و جو را جاسازی میکند و آن را با جاسازیهای از پیش محاسبه شده مقایسه میکند و نزدیکترین مطابقت را شناسایی میکند.
شکل 1 فرآیند پیش آموزش متضاد را نشان میدهد:
- ورودیهای متنی (به عنوان مثال، "Pepper توله سگ استرالیایی") توسط رمزگذار متن به جاسازیها (T1، T2 و غیره) پردازش میشوند.
- تصاویر توسط رمزگذار تصویر به جاسازیها (I1، I2 و غیره) پردازش میشوند.
- جاسازیها در یک فضای برداری مشترک همتراز میشوند، جایی که جفتهای واقعی به هم نزدیکتر میشوند و جفتهای نامتطابق از هم دور میشوند.
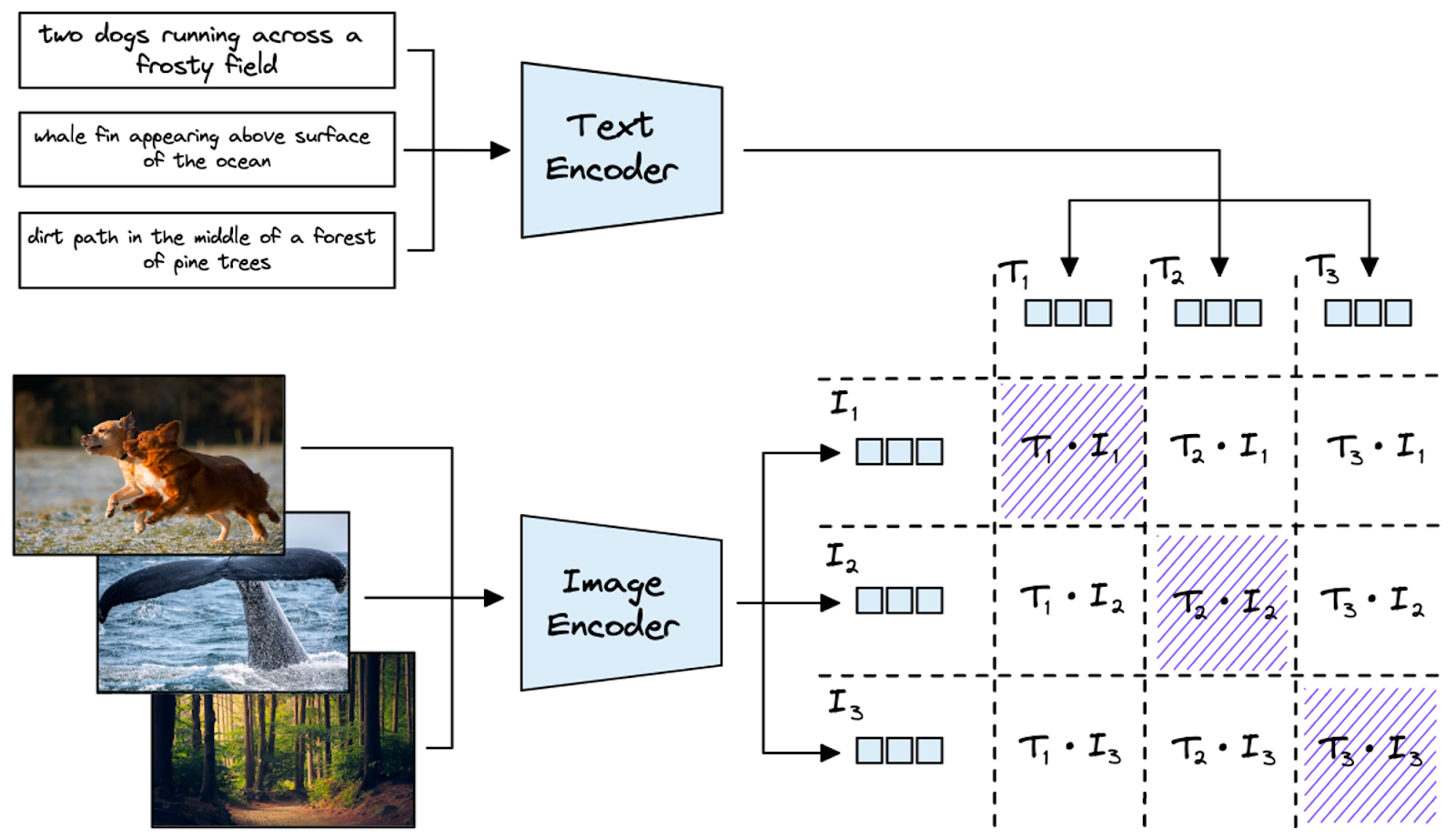
فضای جاسازی مشترک: فعال کردن وظایف تبدیل متن به تصویر و تصویر به متن
پس از پیش آموزش متضاد، فضای جاسازی مشترک CLIP به آن اجازه میدهد تا با همتراز کردن جاسازیهای متن و تصویر، در وظایف مختلف تعمیم یابد.
- تطبیق متن به تصویر
- هنگامی که یک پرس و جوی متنی مانند "دو سگ در حال دویدن در یک مزرعه یخ زده" داده میشود، رمزگذار متن یک جاسازی برای پرس و جو تولید میکند.
- این جاسازی با تمام جاسازیهای تصویر در مجموعه داده مقایسه میشود تا نزدیکترین مطابقت را پیدا کند.
- تطبیق تصویر به متن
- برعکس، اگر تصویری داده شود (به عنوان مثال، عکسی از یک سگ در یک مزرعه)، رمزگذار تصویر یک جاسازی برای تصویر ایجاد میکند.
- این جاسازی در برابر جاسازیهای متن مقایسه میشود و مرتبطترین توضیحات متنی را برمیگرداند.
- قابلیتهای صفر شات
- CLIP میتواند وظایفی مانند بازیابی تصویر یا شرح تصویر را بدون هیچ گونه آموزش اضافی بر روی مجموعههای داده جدید انجام دهد. این امر را با استفاده از فضای جاسازی مشترک قوی خود به دست میآورد.
شکل 2 فرآیند تطبیق در سطح دستهای را به تصویر میکشد:
- توضیحات متنی (به عنوان مثال، "دو سگ در حال دویدن در یک مزرعه یخ زده") به جاسازیها (T1، T2 و غیره) پردازش میشوند.
- تصاویر به جاسازیها (I1، I2 و غیره) رمزگذاری میشوند.
- یک امتیاز شباهت برای هر جفت متن-تصویر محاسبه میشود و نزدیکترین مطابقتها (ورودیهای مورب) برجسته میشوند.
کاربردهای رویکرد CLIP
- بازیابی متن به تصویر: با توجه به یک پرس و جو مانند "یک ماشین اسپورت قرمز"، CLIP میتواند مرتبطترین تصویر را از یک پایگاه داده پیدا کند.
- شرح تصویر: با استفاده از رویکرد معکوس، CLIP میتواند یک توصیف متنی از یک تصویر تولید کند.
- طبقهبندی صفر شات: CLIP میتواند دستههای تصویری را که هرگز به طور صریح برای آنها آموزش ندیده است با تطبیق آنها با توضیحات دسته پیشبینی کند.
CLIP از طریق مکانیسم یادگیری متضاد و فضای جاسازی مشترک خود، طیف وسیعی از کاربردها را فعال میکند و آن را به یک مدل چند وجهی قدرتمند برای سناریوهای دنیای واقعی تبدیل میکند.
پیکربندی محیط توسعه شما
برای دنبال کردن این راهنما و ساخت یک برنامه FastAPI یکپارچه با OpenAI CLIP، باید اطمینان حاصل کنید که کتابخانههای مورد نیاز در محیط پایتون شما نصب شدهاند.
کتابخانههای مورد نیاز را با استفاده از pip نصب کنید:
pip install fastapi[all]==0.98.0 transformers==4.30.2 datasets==2.13.1 Pillow==9.5.0 torch
کتابخانههای کلیدی مورد نیاز برای این پروژه عبارتند از fastapi، که برای ایجاد و مدیریت نقاط پایانی API استفاده میشود، و transformers، که مدل CLIP (CLIPModel) و پردازشگر (CLIPProcessor) را برای رسیدگی به وظایف تبدیل متن به تصویر ارائه میدهد. datasets برای بارگیری و مدیریت مجموعه داده Flickr8k استفاده میشود و دسترسی آسان به جفتهای تصویر-متن را برای آزمایش امکانپذیر میکند. Pillow برای پردازش تصویر استفاده میشود و اطمینان میدهد که تصاویر میتوانند به عنوان پاسخهای API ارائه شوند، در حالی که torch محاسبات مورد نیاز برای مدل CLIP و محاسبات جاسازی را تامین میکند.
این کتابخانهها با هم، ابزارهای ضروری برای ساخت و استقرار برنامه را فراهم میکنند.
ساختار پروژه
قبل از ورود به پیادهسازی، بیایید ساختار دایرکتوری پروژه را مرور کنیم. این به شما کمک میکند تا درک کنید که هر یک از اجزای ادغام FastAPI + OpenAI CLIP در کجا قرار دارند.
fastapi-clip-docker/
+-- pyimagesearch
¦ +-- __init__.py
¦ +-- api.py
¦ +-- config.py
¦ +-- dataset_loader.py
¦ +-- embeddings.py
¦ +-- model.py
¦ +-- helpers.py
+-- server.py
+-- Dockerfile
فایل server.py برنامه FastAPI را تعریف میکند، درخواستها را پردازش میکند و تصاویر مطابق را با استفاده از OpenAI CLIP برمیگرداند. مسیرهای API در pyimagesearch/api.py ثبت شدهاند، در حالی که pyimagesearch/dataset_loader.py بارگیری و پیش پردازش مجموعه داده را مدیریت میکند. جاسازیهای تصویر در pyimagesearch/embeddings.py تولید و ذخیره میشوند و از مدل از پیش آموزش دیده openai/clip-vit-base-patch32 که در pyimagesearch/model.py بارگیری شده است، استفاده میکنند.
اسکریپتهای پشتیبانی شامل pyimagesearch/helpers.py، که جاسازیها را عادی میکند و تصاویر را پردازش میکند، و pyimagesearch/config.py، که مسیرهای مجموعه داده و پارامترهای مدل را ذخیره میکند، هستند.
Dockerfile یک محیط کانتینریزه شده با Uvicorn را پیکربندی میکند و استقرار یکپارچه را تضمین میکند. این فایل وابستگیهای لازم را تعریف میکند و برنامه FastAPI را برای اجرای کارآمد در یک کانتینر Docker تنظیم میکند.
تولید جاسازیها با OpenAI CLIP
جاسازیها نقش مهمی در فعال کردن مدلهایی مانند OpenAI CLIP برای انجام وظایفی مانند تطبیق متن به تصویر و توصیف تصویر به متن ایفا میکنند. در این بخش، نحوه استفاده از جاسازیها در پیش آموزش زبان-تصویر متضاد را بررسی خواهیم کرد و شما را از طریق تولید و راهنمایی خواهیم کرد و شما را از طریق تولید و مدیریت جاسازیها برای برنامه FastAPI خود با استفاده از مدل openai/clip-vit-base-patch32 راهنمایی خواهیم کرد.
جاسازیها چیست؟
جاسازیها نمایشهای عددی از دادهها هستند - چه متن باشد و چه تصاویر - که یک مدل میتواند آنها را پردازش کند. در متن OpenAI CLIP، جاسازیها بردارهایی هستند که اطلاعات معنایی در مورد تصاویر و متن را در یک فضای نمایش مشترک رمزگذاری میکنند. این فضای مشترک به مدل اجازه میدهد تا روابط بین تصاویر و متن را شناسایی کند و امکان یافتن جفتهای مشابه یا تولید مطابقتها را فراهم میکند.
با استفاده از openai/clip-vit-base-patch32، میتوانید جاسازیهای با کیفیت بالا تولید کنید که وظایف پیشرفته تبدیل متن به تصویر را تامین میکنند.
چرا جاسازیها در CLIP مهم هستند؟
قدرت OpenAI CLIP در توانایی آن در قرار دادن متن و تصاویر از نظر معنایی مشابه در نزدیکی یکدیگر در این فضای جاسازی مشترک نهفته است. به عنوان مثال:
- یک درخواست متنی مانند "غروب خورشید بر فراز اقیانوس" و تصویری از چنین غروبی، جاسازیهایی دارند که در نزدیکی یکدیگر قرار دارند.
- این نزدیکی در فضای جاسازی به CLIP اجازه میدهد تا ورودیها را به طور کارآمد در بین روشها مطابقت دهد.
گام به گام: تولید جاسازیهای تصویر
در اینجا نحوه تولید جاسازیها برای مجموعهای از تصاویر با استفاده از مدل OpenAI CLIP openai/clip-vit-base-patch32 آورده شده است.
بارگیری مدل و پردازشگر CLIP
CLIPModel و CLIPProcessor از کتابخانه transformers ابزارهایی را برای پردازش تصاویر و تولید جاسازیها ارائه میدهند.
from transformers import CLIPModel, CLIPProcessor
# Load the model and processor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch")
بارگیری مجموعه داده
از کتابخانه datasets برای بارگیری مجموعهای از تصاویر که میخواهید برای آنها جاسازی تولید کنید، استفاده کنید. در این مثال، ما از مجموعه داده Flickr8k استفاده میکنیم.
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("jxie/flickr8k")
images = dataset['trains']
پیش پردازش تصاویر
تصاویر را با استفاده از processor CLIP پیش پردازش کنید تا آنها را برای مدل آماده کنید.
from PIL import Image
# Preprocess images
image_tensors = [
processor(images[i]["image"], return_tensors="pt")[]
for i in range(len(image))
]
تولید جاسازیها
از مدل CLIP برای محاسبه جاسازیها برای تصاویر از پیش پردازش شده استفاده کنید.
import torch
# Generate embeddings
with torch.no_grad():
image_embeds = torch.cat([model.get_image_features(img) for img in image_tensors])
عادی سازی جاسازیها
جاسازیها را عادی کنید تا اطمینان حاصل شود که بردارهای واحد هستند، که محاسبات شباهت را کارآمدتر میکند.
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
ذخیره و مدیریت جاسازیها
پس از تولید جاسازیها، آنها را برای استفاده مجدد کارآمد در برنامه FastAPI خود save کنید.
import numpy as np
# Save embeddings to a file
np.save("image_embeds.npy", image_embeds.numpy())
بعداً، میتوانید این جاسازیها را مستقیماً بدون تولید مجدد آنها load کنید:
# Load embeddings
image_embeds = torch.tensor(np.load("image_embeds.npy"))
این رویکرد سربار زمان اجرا را به حداقل میرساند و به API شما اجازه میدهد تا تطبیق متن به تصویر و توصیف تصویر را به سرعت انجام دهد.
ایجاد برنامه FastAPI
در این مرحله، شما یک برنامه FastAPI را تنظیم خواهید کرد که میتواند درخواستها را مدیریت کند و از مدل CLIP برای تولید پاسخها استفاده کند.
وارد کردن کتابخانهها و ماژولها
وارد کردن کتابخانهها و ماژولهای مورد نیاز برای ایجاد برنامه FastAPI.
import io
from typing import List
from PIL import Image
from fastapi import FastAPI, UploadFile, File, HTTPException
from fastapi.responses import FileResponse
from pyimagesearch import embeddings, model, helpers
تنظیم FastAPI
نمونهای از کلاس FastAPI ایجاد کنید و نام و توضیحات متا را برای مستندسازی API تنظیم کنید.
app = FastAPI(
title="CLIP API",
description="API for image search using CLIP",
)
تعریف نقاط پایانی
تعریف نقاط پایانی برای:
- جستجوی تصاویر بر اساس متن
- شرح تصاویر
نقطه پایانی جستجوی تصویر بر اساس متن
این نقطه پایانی یک درخواست متنی را میپذیرد و با استفاده از مدل CLIP نزدیکترین تصاویر را برمیگرداند.
@app.post("/search/")
async def search_images(query: str, top_k: int = 5):
# Generate text embeddings for the query
text_embed = model.get_text_features(model.processor(text=[query], return_tensors="pt")[])
text_embed = text_embed / text_embed.norm(p=2, dim=-1, keepdim=True)
# Compute similarity scores
similarity = text_embed @ embeddings.image_embeds.T
# Get indices of top k images
top_indices = torch.argsort(similarity, descending=True)[][:top_k]
# Return the top k images
return [dataset["trains"][i]["file_name"] for i in top_indices]
نقطه پایانی شرح تصویر
این نقطه پایانی یک تصویر را میپذیرد و با استفاده از مدل CLIP شرحی را تولید میکند.
@app.post("/describe/")
async def describe_image(image: UploadFile = File(...)):
# Read the image
image_data = await image.read()
image = Image.open(io.BytesIO(image_data))
# Preprocess the image
image_input = model.processor(images=image, return_tensors="pt")[]
# Generate image embeddings
image_embed = model.get_image_features(image_input)
image_embed = image_embed / image_embed.norm(p=2, dim=-1, keepdim=True)
# Compute similarity scores with text embeddings
similarity = image_embed @ embeddings.text_embeds.T
# Get the index of the most similar text
index = torch.argmax(similarity)[]
# Return the description
return descriptions[index]
نقطه پایانی ریشه
این نقطه پایانی سلامتی API را تأیید میکند.
@app.get("/")
def read_root():
return {"message": "CLIP API is running"}
کامل کردن برنامه FastAPI
این فرآیند به شما یک API میدهد که میتواند تصاویر را بر اساس ورودی متن جستجو کند یا تصاویر را توصیف کند، و با استفاده از مدل CLIP تطبیق متن به تصویر و تصویر به متن را فعال میکند.
تست API با Swagger UI
FastAPI به طور خودکار اسناد API تعاملی را از طریق Swagger UI ارائه میدهد، که به شما اجازه میدهد تا نقاط پایانی API را مستقیماً از مرورگر خود تست کنید.
شروع برنامه
اطمینان حاصل کنید که Uvicorn در حال اجرا است.
python server.py
دسترسی به Swagger UI
به Swagger UI با رفتن به http://localhost:8000/docs در مرورگر خود دسترسی پیدا کنید.
تست نقطه پایانی جستجو
در Swagger UI، نقطه پایانی /search/ را پیدا کنید.
- برای
query، یک ورودی متنی مانندآسمان آبی با ابرهارا وارد کنید. - برای
top_k، تعداد تصاویری را که میخواهید برگردانده شوند، مانند3وارد کنید. - روی
اجراکلیک کنید تا درخواست API را آغاز کنید.
تست نقطه پایانی شرح
به طور مشابه، نقطه پایانی /describe/ را تست کنید:
- روی
انتخاب فایلکلیک کنید و یک فایل تصویر را آپلود کنید. - روی
اجراکلیک کنید. - پاسخ API شامل شرح تولید شده توسط مدل خواهد بود.
این اسناد تعاملی به شما اجازه میدهد تا به سرعت و به طور موثر عملکرد API خود را آزمایش کنید.
کانتینریزه کردن برنامه با Docker
Docker اطمینان میدهد که برنامه شما به طور مداوم در محیطهای مختلف از طریق کانتینریزه کردن آن کار میکند.
ایجاد یک Dockerfile
یک فایل جدید به نام Dockerfile در دایرکتوری اصلی پروژه خود ایجاد کنید و محتویات زیر را اضافه کنید:
FROM python:3.9-slim-buster
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8000"]
این Dockerfile چند عمل انجام میدهد:
- یک تصویر پایتون 3.9 را به عنوان تصویر پایه تعیین میکند.
- یک دایرکتوری کار برای برنامه در داخل کانتینر تنظیم میکند.
- فایل
requirements.txtرا کپی میکند و وابستگیهای لازم را نصب میکند. - کد منبع برنامه را کپی میکند.
- برنامه FastAPI را با استفاده از Uvicorn بر روی پورت 8000 شروع میکند.
ایجاد فایل requirements.txt
مطمئن شوید که فایل requirements.txt خود را از محیط پروژه فعلی تولید کردهاید. این فایل تمام پکیجهایی را لیست میکند که برای اجرای برنامه FastAPI شما مورد نیاز هستند:
pip freeze > requirements.txt
ساخت تصویر Docker
یک تصویر Docker از Dockerfile با استفاده از دستور زیر بسازید:
docker build -t fastapi-clip .
این دستور یک تصویر Docker با تگ fastapi-clip در دایرکتوری فعلی ایجاد میکند.
اجرای کانتینر Docker
برنامه FastAPI را در یک کانتینر Docker با استفاده از دستور زیر اجرا کنید:
docker run -p 8000:8000 fastapi-clip
این دستور:
- یک پورت از ماشین محلی شما (8000) را به پورت 8000 در داخل کانتینر نگاشت میکند.
- کانتینر را در حالت جدا شده اجرا میکند، به این معنی که در پسزمینه اجرا میشود.
دسترسی به برنامه
پس از اینکه کانتینر در حال اجرا است، میتوانید به برنامه FastAPI در مرورگر خود با رفتن به http://localhost:8000/docs دسترسی پیدا کنید.
خلاصه
شما با موفقیت یک برنامه FastAPI را با OpenAI CLIP یکپارچه کردهاید. با Docker، میتوانید به طور موثر API خود را کانتینریزه کنید و استقرار آن را به یک فرآیند ساده تبدیل کنید.