
تنسنت میگوید مدل جدید Hunyuan-T1 آن میتواند پا به پای بهترین سیستمهای استدلالی OpenAI پیش برود.
به پیروی از رویکردی که برای همه مدلهای استدلالی بزرگ استفاده میشود، تنسنت در طول توسعه به شدت به یادگیری تقویتی متکی بود و ۹۶.۷ درصد از توان محاسباتی پس از آموزش بر بهبود استدلال منطقی و همسویی با ترجیحات انسانی متمرکز بود.
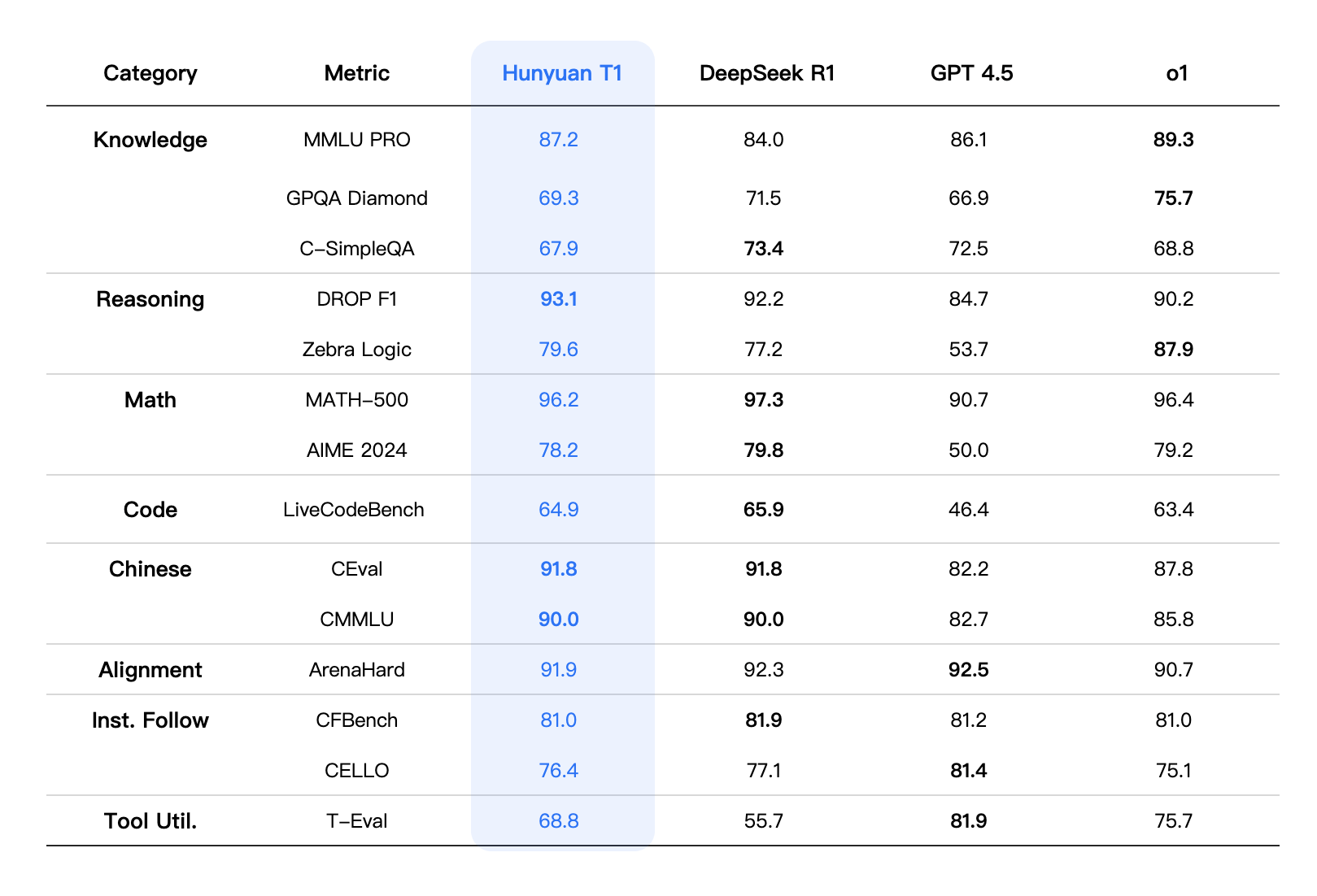
در MMLU-PRO، که دانش را در ۱۴ حوزه موضوعی آزمایش میکند، Hunyuan-T1 امتیاز ۸۷.۲ را کسب کرد و پس از o1 OpenAI در جایگاه دوم قرار گرفت. برای استدلال علمی، این مدل امتیاز ۶۹.۳ را در آزمون GPQA-diamond به دست آورد.
تنسنت میگوید این مدل به ویژه در ریاضیات عالی است. این مدل امتیاز ۹۶.۲ را در محک MATH-500 به دست آورد و درست پس از Deepseek-R1 قرار گرفت. عملکردهای قوی دیگر شامل LiveCodeBench (۶۴.۹ امتیاز) و ArenaHard (۹۱.۹ امتیاز) است.
برای آموزش، تنسنت یک رویکرد یادگیری برنامه درسی را پیادهسازی کرد و به تدریج دشواری کار را افزایش داد. این شرکت همچنین یک سیستم خود پاداش ایجاد کرد که در آن نسخههای قبلی مدل، خروجیهای نسخههای جدیدتر را برای پیشبرد بهبودها ارزیابی میکردند.
این مدل از معماری Transformer Mamba استفاده میکند، که به گفته تنسنت، متون طولانی را دو برابر سریعتر از مدلهای معمولی در شرایط مشابه پردازش میکند. Hunyuan-T1 از طریق Tencent Cloud در دسترس است و یک نسخه آزمایشی در Hugging Face موجود است.
این انتشار پس از معرفی اخیر مدل o1-level خود توسط Baidu و قبل از آن Alibaba است. Alibaba، Baidu و Deepseek همگی استراتژیهای منبع باز را دنبال میکنند. سرمایهگذار هوش مصنوعی و رئیس سابق Google China، Kai-Fu Lee، این تحولات را یک تهدید وجودی برای OpenAI توصیف میکند.
محک زنیها فقط همین هستند
از آنجایی که مدلهای برتر به طور مرتب به دقت بالای ۹۰ درصد در آزمونهای استاندارد دست مییابند، Google Deepmind یک محک چالشبرانگیزتر به نام BIG-Bench Extra Hard (BBEH) را معرفی کرده است. حتی بهترین مدلها با این آزمون جدید دست و پنجه نرم میکنند - بهترین عملکرد OpenAI، o3-mini (high)، تنها به دقت ۴۴.۸ درصد دست یافت.
نتیجه شگفتانگیزتر این بود که Deepseek-R1، با وجود عملکرد قوی خود در سایر محک زنیها، تنها حدود هفت درصد امتیاز کسب کرد. این اختلاف نشان میدهد که نتایج محک زنی تمام داستان را نمیگویند و به ندرت عملکرد دنیای واقعی را منعکس میکنند، به خصوص که برخی از تیمهای مدل به طور خاص برای این آزمونها بهینهسازی میکنند. برخی از مدلهای چینی مشکلات خاصی دارند، مانند درج کاراکترهای چینی در پاسخهای انگلیسی.
خلاصه
- غول فناوری چینی تنسنت از Hunyuan-T1، یک مدل هوش مصنوعی که عملکردی قابل مقایسه با مدلهای استدلالی OpenAI در آزمونهای منطقی نشان میدهد، رونمایی کرده است.
- این مدل در درجه اول با استفاده از تکنیکهای یادگیری تقویتی آموزش داده شده است و با یادگیری برنامه درسی تکمیل شده است که به تدریج سطح دشواری را افزایش میدهد.
- تنسنت اولین شرکتی است که معماری Mamba را در یک مدل استدلالی به کار میگیرد و ادعا میکند که سرعت پردازش متون طولانی را افزایش میدهد و سرعت تولید پاسخ را در مقایسه با رویکردهای قبلی دو برابر میکند.