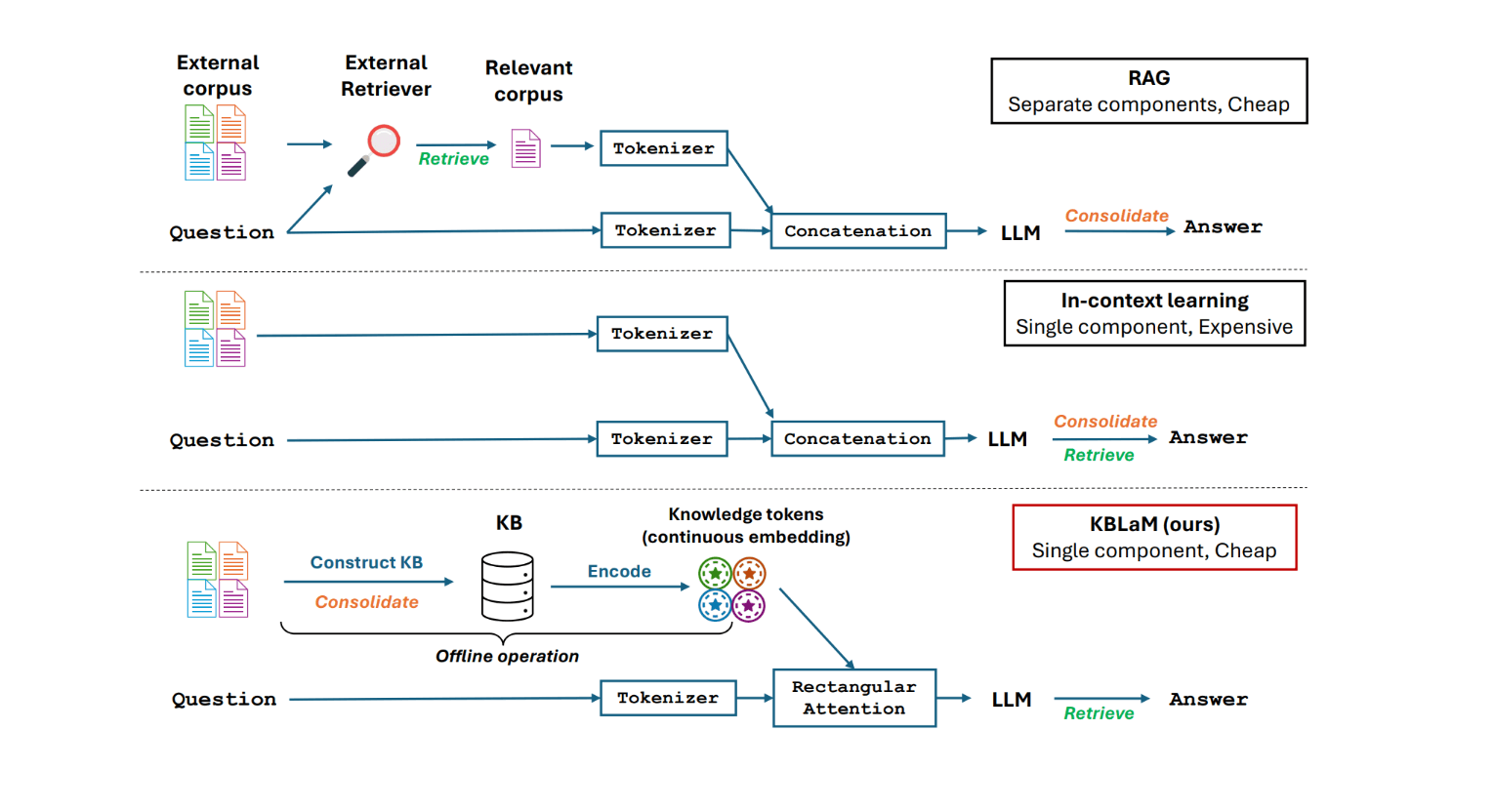
تحقیقات مایکروسافت روشی کارآمدتر برای ادغام دانش خارجی در مدلهای زبانی توسعه داده است. سیستم جدید با نام مدلهای زبانی تقویتشده با پایگاه دانش (Knowledge Base-Augmented Language Models - KBLaM)، از رویکردی plug-and-play استفاده میکند که نیازی به تغییر مدلهای موجود ندارد.
برخلاف رویکردهای فعلی مانند RAG (Retrieval-Augmented Generation) یا یادگیری درونمتنی (In-Context Learning)، KBLaM از سیستمهای بازیابی جداگانه استفاده نمیکند. در عوض، دانش را به جفتهای برداری تبدیل میکند و با استفاده از چیزی که مایکروسافت آن را "توجه مستطیلی" مینامد، مستقیماً در معماری مدل ادغام میکند.
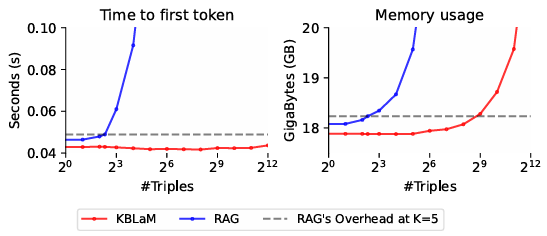
سیستمهای RAG فعلی به دلیل مکانیسم خود-توجه (self-attention) خود با مشکل مقیاسپذیری درجه دوم (quadratic scaling) مواجه هستند - هر توکن باید با هر توکن دیگری تعامل داشته باشد. هنگامی که 1000 توکن از پایگاه دانش در متن قرار داده میشود، مدل باید یک میلیون جفت توکن را پردازش کند. با 10000 توکن، این تعداد به 100 میلیون تعامل افزایش مییابد.
KBLaM این مشکل را دور میزند: در حالی که ورودی کاربر میتواند به همه توکنهای دانش دسترسی داشته باشد، آن توکنهای دانش با یکدیگر یا ورودی تعامل ندارند. این بدان معناست که با رشد پایگاه دانش، توان محاسباتی مورد نیاز فقط به صورت خطی افزایش مییابد. به گفته محققان، یک GPU واحد میتواند بیش از 10000 سهتایی دانش (حدود 200000 توکن) را مدیریت کند.
دسترسی برای توسعهدهندگان
آزمایشها نتایج امیدوارکنندهای را نشان میدهند. KBLaM با حدود 200 مورد دانش، در اجتناب از توهم (hallucination) و امتناع از پاسخ دادن به سؤالاتی که اطلاعاتی در مورد آنها ندارد، بهتر از مدلهای سنتی عمل میکند. همچنین شفافتر از یادگیری درونمتنی است زیرا میتواند دانش را به توکنهای خاص پیوند دهد.
کد و مجموعهدادهها برای KBLaM اکنون در GitHub در دسترس هستند. این سیستم با چندین مدل محبوب از جمله Llama 3 متا و Phi-3 مایکروسافت کار میکند و برنامههایی برای افزودن پشتیبانی از Hugging Face Transformers وجود دارد. محققان تاکید میکنند که KBLaM هنوز برای استفاده گسترده آماده نیست. در حالی که سناریوهای پرسش و پاسخ سرراست را به خوبی انجام میدهد، هنوز به کار بر روی وظایف استدلال پیچیدهتر نیاز دارد.
مدلهای زبانی بزرگ (LLM) با یک تناقض جالب دست و پنجه نرم میکنند: پنجرههای متنی (context windows) آنها به طور مداوم بزرگتر میشوند، که به آنها اجازه میدهد اطلاعات بیشتری را به طور همزمان پردازش کنند، اما پردازش قابل اعتماد همه آن دادهها همچنان یک چالش است. در نتیجه، RAG به یک راه حل مناسب برای تغذیه اطلاعات خاص به مدلها با قابلیت اطمینان نسبی تبدیل شده است، اما KBLaM نشان میدهد که ممکن است راه کارآمدتری برای پیشرفت وجود داشته باشد.
خلاصه
- تحقیقات مایکروسافت، KBLaM را توسعه داده است، روشی جدید که پایگاههای داده دانش ساختاریافته را مستقیماً در مدلهای زبانی ادغام میکند بدون اینکه به ماژولهای بازیابی جداگانه یا آموزش مجدد مدل نیاز باشد.
- تلاش محاسباتی KBLaM به صورت خطی با میزان داده افزایش مییابد، در مقابل روشهای مرسوم مانند RAG که به صورت درجه دوم مقیاس مییابند. این سیستم به ویژه در جلوگیری از توهم مؤثر است.
- کد و مجموعهدادهها به صورت متنباز (open source) در دسترس قرار گرفتهاند و از مدلهای مختلفی مانند Llama-3 و Phi-3 پشتیبانی میکنند. با این حال، مایکروسافت اعلام میکند که قبل از استفاده از این روش در مقیاس بزرگ، تحقیقات بیشتری مورد نیاز است.