انگیزه
سیستم پیشنهاد شخصیسازیشده نتفلیکس یک سیستم پیچیده است که دارای انواع مدلهای یادگیری ماشین تخصصی است که هر کدام نیازهای متمایزی از جمله "ادامه تماشا" و "برترینهای امروز برای شما" را برآورده میکنند. با این حال، با گسترش مجموعه الگوریتمهای شخصیسازی خود برای برآورده کردن نیازهای تجاری رو به رشد، نگهداری از سیستم پیشنهاد بسیار پرهزینه شد. علاوه بر این، انتقال نوآوریها از یک مدل به مدل دیگر دشوار بود، زیرا اکثر آنها به طور مستقل آموزش داده میشوند، علیرغم استفاده از منابع داده مشترک. این سناریو بر نیاز به یک معماری سیستم پیشنهاد جدید تأکید کرد که در آن یادگیری ترجیحات اعضا متمرکز شده و قابلیت دسترسی و سودمندی در مدلهای مختلف افزایش یابد.
به طور خاص، این مدلها عمدتاً ویژگیهایی را از تاریخچه تعاملات اخیر اعضا در پلتفرم استخراج میکنند. با این حال، بسیاری از آنها به دلیل محدودیت در تأخیر سرویس یا هزینههای آموزشی، به یک بازه زمانی کوتاه محدود میشوند. این محدودیت ما را بر آن داشته است تا یک مدل پایه برای پیشنهاد توسعه دهیم. هدف این مدل، جذب اطلاعات هم از تاریخچه تعاملات جامع اعضا و هم از محتوای ما در مقیاس بسیار بزرگ است. این امر توزیع این یادگیریها را به مدلهای دیگر، چه از طریق وزنهای مدل مشترک برای تنظیم دقیق و چه به طور مستقیم از طریق جاسازیها، تسهیل میکند.
انگیزه برای ساخت یک مدل پیشنهاد بنیادی بر اساس تغییر پارادایم در پردازش زبان طبیعی (NLP) به مدلهای زبان بزرگ (LLM) است. در NLP، روند از مدلهای کوچک و تخصصی متعدد به سمت یک مدل زبان بزرگ واحد است که میتواند انواع وظایف را مستقیماً یا با حداقل تنظیم دقیق انجام دهد. بینشهای کلیدی از این تغییر عبارتند از:
- رویکرد دادهمحور: تغییر تمرکز از استراتژیهای مدلمحور، که به شدت به مهندسی ویژگی متکی هستند، به یک رویکرد دادهمحور. این رویکرد جمعآوری دادههای با کیفیت و در مقیاس بزرگ را در اولویت قرار میدهد و در صورت امکان، هدف آن یادگیری سرتاسری است.
- بهرهگیری از یادگیری نیمهنظارتی: هدف پیشبینی توکن بعدی در LLMها به طور قابل توجهی مؤثر بوده است. این امر یادگیری نیمهنظارتی در مقیاس بزرگ را با استفاده از دادههای بدون برچسب امکانپذیر میکند و در عین حال مدل را به درک شگفتانگیزی از دانش جهان مجهز میکند.
این بینشها طراحی مدل پایه ما را شکل داده و انتقال از نگهداری مدلهای کوچک و تخصصی متعدد به ساخت یک سیستم مقیاسپذیر و کارآمد را امکانپذیر میکند. با افزایش دادههای آموزشی نیمهنظارتی و پارامترهای مدل، هدف ما توسعه مدلی است که نه تنها نیازهای فعلی را برآورده میکند، بلکه به طور پویا با خواستههای در حال تحول سازگار میشود و نوآوری پایدار و کارایی منابع را تضمین میکند.
داده
در نتفلیکس، تعامل کاربر طیف گستردهای را در بر میگیرد، از مرور معمولی گرفته تا تماشای متعهدانه فیلم. با بیش از 300 میلیون کاربر در پایان سال 2024، این به صدها میلیارد تعامل تبدیل میشود - یک مجموعه داده عظیم که از نظر مقیاس با حجم توکن مدلهای زبان بزرگ (LLM) قابل مقایسه است. با این حال، مانند LLMها، کیفیت دادهها اغلب از حجم محض آن بیشتر است. برای استفاده مؤثر از این دادهها، ما از فرآیند توکنسازی تعامل استفاده میکنیم و اطمینان حاصل میکنیم که رویدادهای معنادار شناسایی شده و افزونگیها به حداقل میرسند.
توکنسازی تعاملات کاربر: همه اقدامات خام کاربر به یک اندازه به درک ترجیحات کمک نمیکنند. توکنسازی به تعریف آنچه که یک "توکن" معنادار در یک توالی را تشکیل میدهد، کمک میکند. با ترسیم یک قیاس با کدگذاری جفت بایت (BPE) در NLP، میتوانیم توکنسازی را به عنوان ادغام اقدامات مجاور برای تشکیل توکنهای جدید و سطح بالاتر در نظر بگیریم. با این حال، بر خلاف توکنسازی زبان، ایجاد این توکنهای جدید مستلزم بررسی دقیق این است که چه اطلاعاتی باید حفظ شود. به عنوان مثال، ممکن است لازم باشد کل مدت زمان تماشا جمع شود یا انواع تعامل برای حفظ جزئیات حیاتی جمع شوند.
این مصالحه بین دادههای دانهبندیشده و فشردهسازی توالی مشابه تعادل در LLMها بین اندازه واژگان و پنجره زمینه است. در مورد ما، هدف این است که طول تاریخچه تعامل را در برابر سطح جزئیات حفظ شده در توکنهای فردی متعادل کنیم. توکنسازی بیش از حد زیانآور خطر از دست دادن سیگنالهای ارزشمند را دارد، در حالی که یک توالی بیش از حد دانهبندیشده میتواند از محدودیتهای عملی در زمان پردازش و حافظه فراتر رود.
حتی با چنین استراتژیهایی، تاریخچه تعامل کاربران فعال میتواند هزاران رویداد را در بر گیرد و از ظرفیت مدلهای ترانسفورماتور با لایههای توجه خودکار استاندارد فراتر رود. در سیستمهای پیشنهاد، پنجرههای زمینه در طول استنتاج اغلب به صدها رویداد محدود میشوند - نه به دلیل قابلیت مدل، بلکه به این دلیل که این سرویسها معمولاً به تأخیر در سطح میلیثانیه نیاز دارند. این محدودیت سختگیرانهتر از چیزی است که معمولاً در برنامههای LLM وجود دارد، جایی که زمانهای استنتاج طولانیتر (ثانیهها) قابل تحملتر هستند.
برای رسیدگی به این موضوع در طول آموزش، ما دو راه حل کلیدی را پیاده سازی می کنیم:
- مکانیسمهای توجه پراکنده: با استفاده از تکنیکهای توجه پراکنده مانند فشردهسازی رتبه پایین، مدل میتواند پنجره زمینه خود را تا چندین صد رویداد گسترش دهد و در عین حال کارایی محاسباتی را حفظ کند. این امر به آن امکان میدهد تاریخچه تعامل گستردهتری را پردازش کند و بینشهای غنیتری را در مورد ترجیحات بلندمدت به دست آورد.
- نمونهبرداری پنجره کشویی: در طول آموزش، ما پنجرههای همپوشانی از تعاملات را از توالی کامل نمونهبرداری میکنیم. این اطمینان میدهد که مدل در طول چندین دوره در معرض بخشهای مختلف تاریخچه کاربر قرار میگیرد و به آن اجازه میدهد از کل توالی بدون نیاز به یک پنجره زمینه غیرعملی بزرگ یاد بگیرد.
در زمان استنتاج، هنگامی که رمزگشایی چند مرحلهای مورد نیاز است، میتوانیم از حافظه پنهان KV برای استفاده مجدد کارآمد از محاسبات گذشته و حفظ تأخیر کم استفاده کنیم.
این رویکردها به طور جمعی به ما امکان می دهند تا نیاز به مدلسازی دقیق و طولانی مدت تعامل را با محدودیتهای عملی آموزش و استنتاج مدل متعادل کنیم و دقت و مقیاسپذیری سیستم پیشنهاد خود را افزایش دهیم.
اطلاعات در هر "توکن": در حالی که قسمت اول فرآیند توکنسازی ما بر ساختاردهی توالیهای تعامل تمرکز دارد، گام حیاتی بعدی تعریف اطلاعات غنی موجود در هر توکن است. برخلاف LLMها، که معمولاً به یک فضای جاسازی واحد برای نمایش توکنهای ورودی متکی هستند، رویدادهای تعامل ما مملو از جزئیات ناهمگن هستند. اینها شامل ویژگیهای خود عمل (مانند مکان، زمان، مدت و نوع دستگاه) و همچنین اطلاعات مربوط به محتوا (مانند شناسه مورد و فرادادههایی مانند ژانر و کشور انتشار) است. اکثر این ویژگیها، به ویژه ویژگیهای طبقهبندیشده، مستقیماً در مدل جاسازی میشوند و رویکرد یادگیری سرتاسری را در بر میگیرند. با این حال، برخی از ویژگیها نیاز به توجه ویژه دارند. به عنوان مثال، مهر زمانی نیاز به پردازش اضافی دارد تا هر دو مفهوم مطلق و نسبی زمان را ثبت کند، و زمان مطلق به ویژه برای درک رفتارهای حساس به زمان مهم است.
برای افزایش دقت پیشبینی در سیستمهای پیشنهاد ترتیبی، ما ویژگیهای توکن را به دو دسته سازماندهی میکنیم:
- ویژگیهای زمان درخواست: اینها ویژگیهایی هستند که در لحظه پیشبینی در دسترس هستند، مانند زمان ورود به سیستم، دستگاه یا مکان.
- ویژگیهای پس از عمل: اینها جزئیاتی هستند که پس از وقوع یک تعامل در دسترس هستند، مانند نمایش خاصی که با آن تعامل شده یا مدت زمان تعامل.
برای پیشبینی تعامل بعدی، ما ویژگیهای زمان درخواست را از مرحله فعلی با ویژگیهای پس از عمل از مرحله قبلی ترکیب میکنیم. این ترکیب اطلاعات متنی و تاریخی تضمین میکند که هر توکن در توالی یک نمایش جامع را حمل میکند و هم زمینه فوری و هم الگوهای رفتاری کاربر را در طول زمان ثبت میکند.
ملاحظات برای هدف و معماری مدل
همانطور که قبلا ذکر شد، رویکرد پیشفرض ما از هدف پیشبینی توکن بعدی خودرگرسیون، مشابه GPT استفاده میکند. این استراتژی به طور موثری از مقیاس وسیع دادههای تعامل کاربر بدون برچسب استفاده میکند. اتخاذ این هدف در سیستمهای پیشنهاد موفقیتهای متعددی را نشان داده است [1-3]. با این حال، با توجه به تفاوتهای متمایز بین وظایف زبان و وظایف پیشنهاد، ما چندین تغییر مهم در هدف ایجاد کردهایم.
اولاً، در طول مرحله پیشآموزش LLMهای معمولی، مانند GPT، به طور کلی با هر توکن هدف با وزن یکسان رفتار میشود. در مقابل، در مدل ما، همه تعاملات کاربر از اهمیت یکسانی برخوردار نیستند. به عنوان مثال، یک تریلر 5 دقیقهای نباید همان وزن یک فیلم کامل 2 ساعته را داشته باشد. چالش بزرگتری هنگام تلاش برای همسو کردن رضایت کاربر بلندمدت با تعاملات و پیشنهادات خاص ایجاد میشود. برای رفع این مشکل، میتوانیم یک هدف پیشبینی چند توکنی را در طول آموزش اتخاذ کنیم، جایی که مدل به جای یک توکن واحد، n توکن بعدی را در هر مرحله پیشبینی میکند[4]. این رویکرد مدل را تشویق میکند تا وابستگیهای طولانیمدتتری را ثبت کند و از پیشبینیهای کوتهبینانه که صرفاً بر رویدادهای فوری بعدی متمرکز هستند، اجتناب کند.
ثانیاً، میتوانیم از فیلدهای متعددی در دادههای ورودی خود به عنوان اهداف پیشبینی کمکی علاوه بر پیشبینی شناسه مورد بعدی، که هدف اصلی باقی میماند، استفاده کنیم. به عنوان مثال، میتوانیم ژانرها را از موارد موجود در توالی اصلی استخراج کنیم و از این توالی ژانر به عنوان یک هدف کمکی استفاده کنیم. این رویکرد چندین هدف را دنبال میکند: به عنوان یک تنظیمکننده برای کاهش بیشبرازش در پیشبینیهای پر سر و صدای شناسه مورد عمل میکند، بینشهای بیشتری را در مورد اهداف کاربر یا ترجیحات ژانر طولانیمدت ارائه میدهد و در صورت ساختار سلسله مراتبی، میتواند دقت پیشبینی شناسه مورد هدف را بهبود بخشد. با پیشبینی ابتدا اهداف کمکی، مانند ژانر یا زبان اصلی، مدل به طور موثر فهرست نامزدها را محدود میکند و پیشبینی شناسه مورد بعدی را ساده میکند.
چالشهای منحصر به فرد برای پیشنهاد FM
علاوه بر چالشهای زیرساختی ناشی از آموزش مدلهای بزرگتر با مقادیر قابل توجهی از دادههای تعامل کاربر که هنگام تلاش برای ساخت مدلهای پایه رایج هستند، چندین مانع منحصر به فرد برای توصیهها وجود دارد تا آنها را زنده کند. یکی از چالشهای منحصر به فرد، سرد شروع نهاد است.
در نتفلیکس، ماموریت ما سرگرم کردن جهان است. عناوین جدید به طور مکرر به کاتالوگ اضافه میشوند. بنابراین، مدلهای پایه پیشنهاد به قابلیت شروع سرد نیاز دارند، به این معنی که مدلها باید ترجیحات اعضا را برای عناوین تازه راهاندازی شده قبل از اینکه کسی با آنها درگیر شود، تخمین بزنند. برای فعال کردن این، چارچوب آموزش مدل پایه ما با دو قابلیت زیر ساخته شده است: آموزش افزایشی و توانایی استنتاج با موجودیتهای دیده نشده.
- آموزش افزایشی: مدلهای پایه بر روی مجموعههای داده گسترده، از جمله تاریخچه پخش و اقدامات هر عضو آموزش داده میشوند، که باعث میشود آموزش مجدد مکرر غیرعملی شود. با این حال، کاتالوگ و ترجیحات اعضای ما دائماً در حال تکامل هستند. برخلاف مدلهای زبان بزرگ، که میتوانند به طور افزایشی با واژگان توکن پایدار آموزش داده شوند، مدلهای پیشنهاد ما به جاسازیهای جدید برای عناوین جدید نیاز دارند، که نیاز به لایههای جاسازی گسترده و اجزای خروجی دارد. برای رفع این مشکل، ما با استفاده مجدد از پارامترهای مدلهای قبلی و مقداردهی اولیه پارامترهای جدید برای عناوین جدید، مدلهای جدید را گرم شروع میکنیم. به عنوان مثال، جاسازیهای عنوان جدید را میتوان با افزودن نویز تصادفی جزئی به جاسازیهای میانگین موجود یا با استفاده از ترکیبی وزنی از جاسازیهای عناوین مشابه بر اساس فراداده مقداردهی اولیه کرد. این رویکرد به عناوین جدید اجازه میدهد تا با جاسازیهای مرتبط شروع کنند و تنظیم دقیق سریعتر را تسهیل کنند. در عمل، روش مقداردهی اولیه زمانی که از دادههای تعامل اعضای بیشتری برای تنظیم دقیق استفاده شود، اهمیت کمتری پیدا میکند.
- برخورد با موجودیتهای دیده نشده: حتی با آموزش افزایشی، همیشه تضمین نمیشود که به طور کارآمد بر روی موجودیتهای جدید (به عنوان مثال: عناوین تازه راهاندازی شده) یاد بگیرید. همچنین این احتمال وجود دارد که برخی از موجودیتهای جدید وجود داشته باشند که حتی اگر مدلهای پایه را به طور مکرر تنظیم کنیم، در دادههای آموزشی گنجانده نشده/دیده نشده باشند. بنابراین، مهم است که مدلهای پایه از اطلاعات فرادادهای موجودیتها و ورودیها، نه فقط دادههای تعامل اعضا نیز استفاده کنند. بنابراین، مدل پایه ما هم جاسازیهای شناسه مورد قابل یادگیری و هم جاسازیهای قابل یادگیری از فراداده را ترکیب میکند. نمودار زیر این ایده را نشان میدهد.
برای ایجاد جاسازی عنوان نهایی، ما این جاسازی مبتنی بر فراداده را با یک جاسازی مبتنی بر شناسه کاملاً قابل یادگیری با استفاده از یک لایه اختلاط ترکیب می کنیم. به جای جمع کردن ساده این جاسازی ها، از یک مکانیسم توجه بر اساس "سن" موجودیت استفاده می کنیم. این رویکرد به عناوین جدید با دادههای تعامل محدود اجازه میدهد تا بیشتر به فراداده تکیه کنند، در حالی که عناوین تثبیت شده میتوانند بیشتر به جاسازیهای مبتنی بر شناسه تکیه کنند. از آنجایی که عناوینی با فراداده مشابه میتوانند تعامل کاربر متفاوتی داشته باشند، جاسازیهای آنها باید این تفاوتها را منعکس کند. معرفی مقداری تصادفی در طول آموزش، مدل را تشویق میکند تا از فراداده یاد بگیرد تا اینکه صرفاً به جاسازیهای شناسه تکیه کند. این روش تضمین می کند که عناوین تازه راه اندازی شده یا قبل از راه اندازی حتی بدون دادههای تعامل کاربر، جاسازیهای معقولی دارند.
برنامههای کاربردی و چالشهای پایین دستی
مدل پایه پیشنهاد ما برای درک ترجیحات اعضای بلندمدت طراحی شده است و میتواند به روشهای مختلف توسط برنامههای کاربردی پایین دستی مورد استفاده قرار گیرد:
- استفاده مستقیم به عنوان یک مدل پیشبینی مدل در درجه اول برای پیشبینی نهاد بعدی که کاربر با آن تعامل خواهد داشت، آموزش داده میشود. این شامل چندین هد پیشبینی کننده برای وظایف مختلف است، مانند پیشبینی ترجیحات اعضا برای ژانرهای مختلف. اینها را میتوان مستقیماً برای برآورده کردن نیازهای تجاری متنوع اعمال کرد.
- استفاده از جاسازیها مدل جاسازیهای ارزشمندی را برای اعضا و نهادهایی مانند فیلمها، بازیها و ژانرها تولید میکند. این جاسازیها در مشاغل دستهای محاسبه میشوند و برای استفاده در برنامههای آفلاین و آنلاین ذخیره میشوند. آنها میتوانند به عنوان ویژگی در مدلهای دیگر عمل کنند یا برای تولید نامزد استفاده شوند، مانند بازیابی عناوین جذاب برای یک کاربر. جاسازیهای عنوان با کیفیت بالا همچنین از توصیههای عنوان به عنوان پشتیبانی میکنند. با این حال، یک نکته مهم این است که فضای جاسازی دارای ابعاد دلخواه و غیرقابل تفسیر است و در بین آموزشهای مختلف مدل ناسازگار است. این امر چالشهایی را برای مصرف کنندگان پایین دستی ایجاد میکند، که باید با هر آموزش مجدد و استقرار مجدد سازگار شوند و به دلیل فرضیات نامعتبر در مورد ساختار جاسازی، خطر اشکالات را به همراه دارد. برای رفع این مشکل، ما یک تبدیل رتبه پایین متعامد را برای تثبیت فضای جاسازی کاربر/مورد اعمال میکنیم و معنای ثابتی از ابعاد جاسازی را تضمین میکنیم، حتی زمانی که مدل پایه پایه مجدداً آموزش داده شده و مجدداً مستقر میشود.
- تنظیم دقیق با دادههای خاص سازگاری مدل امکان تنظیم دقیق با دادههای خاص برنامه را فراهم میکند. کاربران میتوانند مدل کامل یا زیرگرافها را در مدلهای خود ادغام کنند و آنها را با دادههای کمتر و توان محاسباتی تنظیم کنند. این رویکرد به عملکردی قابل مقایسه با مدلهای قبلی دست مییابد، علیرغم اینکه مدل پایه اولیه به منابع قابل توجهی نیاز دارد.
مقیاسبندی مدلهای پایه برای توصیههای نتفلیکس
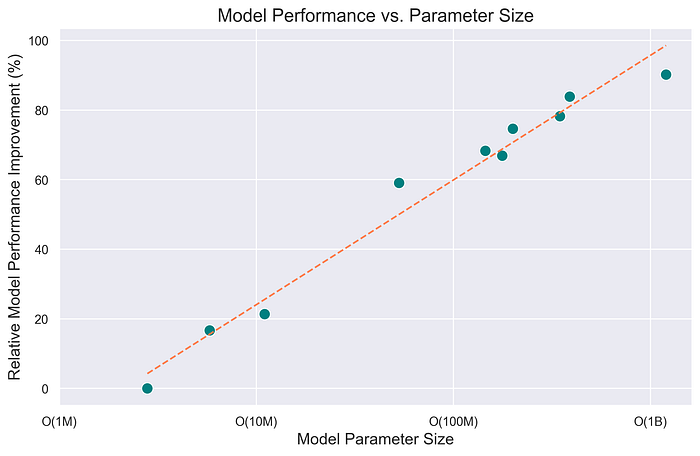
در مقیاسبندی مدل پایه خود برای توصیههای نتفلیکس، از موفقیت مدلهای زبان بزرگ (LLM) الهام میگیریم. درست همانطور که LLMها قدرت مقیاسبندی را در بهبود عملکرد نشان دادهاند، ما میبینیم که مقیاسبندی برای بهبود وظایف توصیه مولد بسیار مهم است. مقیاسبندی موفقیتآمیز مستلزم ارزیابی قوی، الگوریتمهای آموزشی کارآمد و منابع محاسباتی قابل توجه است. ارزیابی باید به طور موثر عملکرد مدل را متمایز کند و زمینههای بهبود را شناسایی کند. مقیاسبندی شامل مقیاسبندی دادهها، مدل و زمینه، ترکیب تعامل کاربر، بررسیهای خارجی، داراییهای چندرسانهای و جاسازیهای با کیفیت بالا است. آزمایشهای ما تأیید میکند که قانون مقیاسبندی نیز برای مدل پایه ما اعمال میشود و با افزایش دادهها و اندازه مدل، بهبودهای ثابتی مشاهده میشود.
نتیجهگیری
در پایان، مدل پایه ما برای پیشنهاد شخصیسازیشده گامی مهم در جهت ایجاد یک سیستم یکپارچه و دادهمحور است که از دادههای در مقیاس بزرگ برای افزایش کیفیت توصیهها برای اعضای ما استفاده میکند. این رویکرد از مدلهای زبان بزرگ (LLM)، به ویژه اصول یادگیری نیمهنظارتی و آموزش سرتاسری، وام میگیرد و هدف آن استفاده از مقیاس وسیع دادههای تعامل کاربر بدون برچسب است. این مدل با پرداختن به چالشهای منحصربهفرد، مانند شروع سرد و سوگیری ارائه، تفاوتهای متمایز بین وظایف زبان و توصیه را نیز تشخیص میدهد. مدل پایه به برنامههای کاربردی پایین دستی مختلف، از استفاده مستقیم به عنوان یک مدل پیشبینی کننده گرفته تا تولید جاسازیهای کاربر و نهاد برای برنامههای دیگر، اجازه میدهد و میتواند برای بومهای خاص تنظیم شود. ما نتایج امیدوارکنندهای را از ادغامهای پایین دستی میبینیم. این حرکت از چندین مدل تخصصی به یک سیستم جامعتر نشاندهنده یک توسعه هیجانانگیز در زمینه سیستمهای پیشنهاد شخصیسازیشده است.
تشکر و قدردانی
همکاران در این کار (نام به ترتیب حروف الفبا): Ai-Lei Sun Aish Fenton Anne Cocos Anuj Shah Arash Aghevli Baolin Li Bowei Yan Dan Zheng Dawen Liang Ding Tong Divya Gadde Emma Kong Gary Yeh Inbar Naor Jin Wang Justin Basilico Kabir Nagrecha Kevin Zielnicki Linas Baltrunas Lingyi Liu Luke Wang Matan Appelbaum Michael Tu Moumita Bhattacharya Pablo Delgado Qiuling Xu Rakesh Komuravelli Raveesh Bhalla Rob Story Scott Sanner Shreekant Gade Shuo Qi Soumyadeep Ghosh Steve Velez Subhabrata Mukherjee Thomas Schwarz Tianqi Liu Tsung-Yi Lin Wei Teng Xuguang Yang Yang Zhang Yuanpu Xie Yuting Lin Zeyu Li Zhe Xue و Zhenqin Li. Hanlin Zhou، Jennifer Chhay، Jeremy Barnes، Yashar Mehdad و Cody Evans در بررسی این پست وبلاگ به ما کمک کردند.