
یک سیستم هوش مصنوعی جدید که توسط Google Research و Google DeepMind توسعه یافته است، عکسها را به صحنههای سهبعدی واقعگرایانه در عرض چند ثانیه تبدیل میکند، البته تا زمانی که بداند موقعیت دوربین کجا بوده است.
این سیستم که Bolt3D نام دارد، عکسها را به صحنههای سهبعدی کامل در عرض تنها 6.25 ثانیه روی یک پردازنده گرافیکی Nvidia H100 تبدیل میکند - کاری که معمولاً انجام آن با سیستمهای دیگر دقایق یا ساعتها طول میکشد.
Bolt3D ابتدا تشخیص میدهد که هر پیکسل در فضای سهبعدی به کجا تعلق دارد و رنگ آن باید چه باشد. سپس یک مدل دوم تعیین میکند که هر نقطه چقدر باید شفاف باشد و چگونه در فضا امتداد یابد.
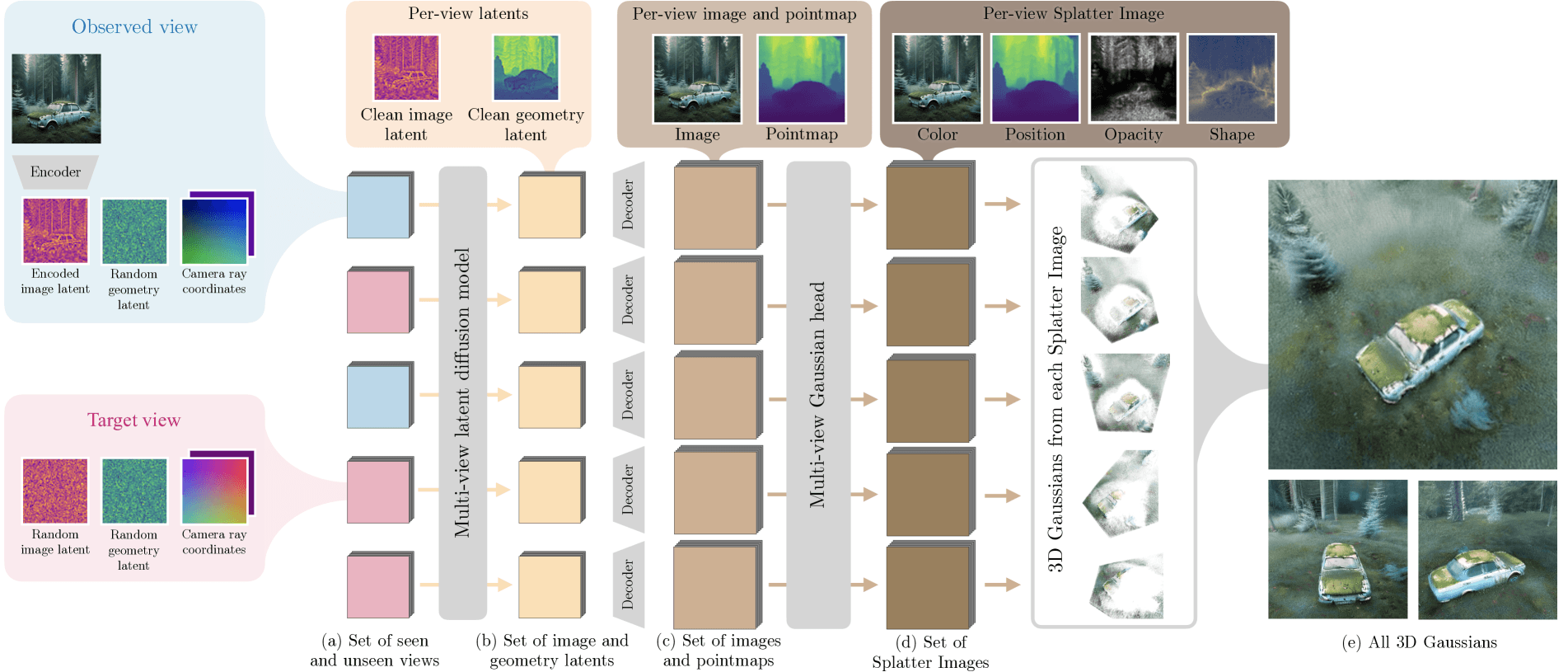
این سیستم متکی به تکنیکی به نام "Gaussian splatting" برای ذخیره دادههای خود است و صحنه سهبعدی را با استفاده از توابع گاوسی سهبعدی که در شبکههای دوبعدی چیده شدهاند، سازماندهی میکند. هر تابع موقعیت، رنگ، شفافیت و اطلاعات فضایی را ردیابی میکند و به کاربران اجازه میدهد صحنه را از هر زاویهای در زمان واقعی مشاهده کنند. برای اینکه فایلها قابل مدیریت باشند، سیستم نواحی شفاف را حذف و دادههای باقیمانده را به طور موثر فشرده میکند.
ویدیو: Szymanowicz et al.
پیشرفتهای چشمگیر در تولید سهبعدی
آزمایشها نشان میدهند که Bolt3D به طور قابل توجهی بهتر از روشهای سریع موجود مانند Flash3D و DepthSplat عمل میکند. در حالی که این سیستمها فقط میتوانند نواحیای را که نمیتوانند ببینند تار کنند، Bolt3D در واقع محتوای واقعی برای بخشهای پنهان صحنهها ایجاد میکند.
این قابلیت از یک مدل هوش مصنوعی تخصصی ناشی میشود که به طور خاص برای مدیریت دادههای فضایی طراحی شده است - محققان دریافتند که مدلهای معمولی که فقط روی عکسها آموزش دیدهاند نمیتوانند از عهده پیچیدگیهای اطلاعات سهبعدی برآیند.
برای ایجاد این قابلیت، تیم Bolt3D را روی حدود 300,000 صحنه سهبعدی، با استفاده از ترکیبی از بازسازیهای مبتنی بر عکس و مدلهای تولید شده توسط رایانه، آموزش داد. این مجموعه داده گسترده به سیستم کمک میکند تا حدسهای آگاهانهای درباره بخشهایی از صحنهها که نمیتواند به طور کامل ببیند، بزند.
ویدیو: Szymanowicz et al.
این سیستم هنوز محدودیتهایی دارد. با جزئیات بسیار ریز (هر چیزی کمتر از هشت پیکسل عرض)، مواد شفاف مانند شیشه و سطوح بسیار بازتابنده مشکل دارد. کیفیت نتایج نیز به شدت به نحوه گرفتن عکسها و اندازه صحنه نهایی بستگی دارد.
حتی با وجود این محدودیتها، به نظر میرسد Bolt3D یک گام رو به جلو در ایجاد محتوای سهبعدی باشد. این مقاله نشان میدهد که سرعت آن میتواند تولید صحنههای سهبعدی در مقیاس بزرگ را برای اولین بار عملی کند. در حالی که هنوز خبری از در دسترس بودن عمومی آن نیست، کاربران علاقهمند میتوانند اطلاعات بیشتر و نسخههای نمایشی تعاملی را در وبسایت پروژه پیدا کنند.
این توسعه در حالی صورت میگیرد که Stability AI سیستم SPAR3D خود را نیز منتشر میکند که میتواند اشیاء سهبعدی را از تصاویر تکی به سرعت تولید کند. تفاوت اصلی: در حالی که SPAR3D با اشیاء منفرد کار میکند، Bolt3D میتواند کل صحنهها را مدیریت کند.
خلاصه
- Google Research و Google Deepmind یک سیستم هوش مصنوعی به نام Bolt3D ایجاد کردهاند که صحنههای سهبعدی واقعگرایانه را از عکسها تنها در 6.25 ثانیه تولید میکند، که بهبود قابل توجهی نسبت به روشهای قبلی است که دقایق یا ساعتها طول میکشید.
- Bolt3D در دو مرحله کار میکند: ابتدا، یک مدل هوش مصنوعی پیکسلها را تجزیه و تحلیل میکند و سپس یک مدل دوم شفافیت و وسعت فضایی آنها را تعیین میکند. دادهها در قالب "Gaussian splatting" ذخیره میشوند که امکان تجسم در زمان واقعی را فراهم میکند.
- این هوش مصنوعی روی 300,000 صحنه سهبعدی آموزش داده شده است و میتواند به طور واقعبینانه نواحی غیرقابل مشاهده را پر کند. با این حال، با ساختارهای ریز کوچکتر از هشت پیکسل محدودیت دارد و با شیشه و سطوح بازتابنده مشکل دارد.