
مدلهای زبانی بزرگ (LLM) قابلیتهای استدلال و دانش قویای را نشان دادهاند، اما اغلب هنگامی که بازنماییهای داخلیشان فاقد جزئیات خاصی است، نیازمند افزایش دانش خارجی هستند. یک روش برای گنجاندن اطلاعات جدید، تنظیم دقیق نظارتشده است، جایی که مدلها روی مجموعهدادههای اضافی آموزش داده میشوند تا وزنهای خود را بهروز کنند. با این حال، این رویکرد ناکارآمد است، زیرا هر زمان که دانش جدیدی معرفی میشود، نیاز به آموزش مجدد دارد و ممکن است منجر به فراموشی فاجعهبار شود و عملکرد مدل را در وظایف عمومی تخریب کند. برای غلبه بر این محدودیتها، تکنیکهای جایگزینی که وزنهای مدل را حفظ میکنند، محبوبیت پیدا کردهاند. تولید تقویتشده با بازیابی (RAG) یک رویکرد است که دانش مرتبط را از متن بدون ساختار بازیابی میکند و قبل از عبور از مدل، آن را به پرسش ورودی اضافه میکند. با بازیابی پویای اطلاعات، RAG مدلهای زبانی بزرگ را قادر میسازد تا به پایگاههای دانش بزرگ دسترسی داشته باشند در حالی که اندازه متن کوچکتری را حفظ میکنند. با این حال، از آنجایی که مدلهای متن طولانی مانند GPT-4 و Gemini ظاهر شدهاند، محققان یادگیری در متن را بررسی کردهاند، جایی که دانش خارجی مستقیماً در ورودی مدل ارائه میشود. این امر نیاز به بازیابی را از بین میبرد، اما با چالشهای محاسباتی همراه است، زیرا پردازش متون طولانی به حافظه و زمان بسیار بیشتری نیاز دارد.
تکنیکهای پیشرفته متعددی برای افزایش توانایی مدلهای زبانی بزرگ در ادغام کارآمدتر دانش خارجی توسعه یافتهاند. مکانیسمهای توجه ساختیافته با تقسیمبندی متن به بخشهای مستقل، کارایی حافظه را بهبود میبخشند و بار محاسباتی توجه به خود را کاهش میدهند. ذخیرهسازی کلید-مقدار (KV) با ذخیره جاسازیهای از پیش محاسبهشده در لایههای مختلف، تولید پاسخ را بهینه میکند و به مدل اجازه میدهد تا اطلاعات مرتبط را بدون محاسبه مجدد به خاطر بیاورد. این امر پیچیدگی را از درجه دوم به خطی در رابطه با طول متن کاهش میدهد. برخلاف ذخیرهسازی KV سنتی، که هنگام تغییر ورودی نیاز به محاسبه مجدد کامل دارد، روشهای جدیدتر امکان بهروزرسانیهای انتخابی را فراهم میکنند و ادغام دانش خارجی را انعطافپذیرتر میکنند.
محققان دانشگاه جانز هاپکینز و مایکروسافت یک مدل زبانی تقویتشده با پایگاه دانش (KBLAM) را پیشنهاد میکنند، روشی برای ادغام دانش خارجی در مدلهای زبانی بزرگ. KBLAM سهتاییهای پایگاه دانش (KB) ساختیافته را به جفتهای برداری کلید-مقدار تبدیل میکند و به طور یکپارچه آنها را در لایههای توجه LLM تعبیه میکند. برخلاف RAG، این روش بازیابهای خارجی را حذف میکند و برخلاف یادگیری در متن، با اندازه KB به صورت خطی مقیاس مییابد. KBLAM امکان بهروزرسانیهای پویای کارآمد بدون آموزش مجدد را فراهم میکند و قابلیت تفسیر را افزایش میدهد. این مدل که با استفاده از تنظیم دستورالعمل روی دادههای مصنوعی آموزش داده شده است، با امتناع از پاسخ دادن در صورت عدم وجود دانش مرتبط، قابلیت اطمینان را بهبود میبخشد، توهمات را کاهش میدهد و مقیاسپذیری را افزایش میدهد.
KBLAM مدلهای زبانی بزرگ را با ادغام یک KB از طریق دو مرحله افزایش میدهد. ابتدا، هر سهتایی KB با استفاده از یک رمزگذار جمله از پیش آموزشدیده و آداپتورهای خطی، به جاسازیهای کلید-مقدار پیوسته تبدیل میشود که به عنوان نشانههای دانش نامیده میشوند. این نشانهها سپس از طریق یک ساختار توجه مستطیلی در هر لایه توجه گنجانده میشوند و امکان بازیابی کارآمد را بدون تغییر پارامترهای اصلی LLM فراهم میکنند. این روش مقیاسپذیری را تضمین میکند، سوگیری موقعیتی را کاهش میدهد و تواناییهای استدلال را حفظ میکند. علاوه بر این، تنظیم دستورالعمل، طرحریزی نشانه دانش را بدون تغییر LLM بهینه میکند و از یک KB مصنوعی برای جلوگیری از حفظ کردن استفاده میکند. این رویکرد به طور موثر KBهای بزرگ را ادغام میکند در حالی که قابلیتهای اصلی مدل را حفظ میکند.
ارزیابی تجربی KBLAM اثربخشی آن را به عنوان یک مدل بازیابی و استدلال دانش نشان میدهد. پس از تنظیم دستورالعمل، ماتریس توجه آن الگوهای قابل تفسیری را نشان میدهد که امکان بازیابی دقیق را فراهم میکند. KBLAM به عملکردی قابل مقایسه با یادگیری در متن دست مییابد در حالی که به طور قابل توجهی استفاده از حافظه را کاهش میدهد و مقیاسپذیری را تا 10 هزار سهتایی حفظ میکند. همچنین میتواند در صورت عدم وجود دانش مرتبط از پاسخ دادن امتناع ورزد و "امتناع بیش از حد" دیرتر از یادگیری در متن رخ میدهد. این مدل روی یک Llama3-8B با دستورالعمل تنظیمشده آموزش داده شده و با استفاده از AdamW بهینه شده است. ارزیابی مجموعهدادههای مصنوعی و Enron صحت بازیابی قوی، ادغام دانش کارآمد و توانایی KBLAM در به حداقل رساندن توهمات را تأیید میکند.
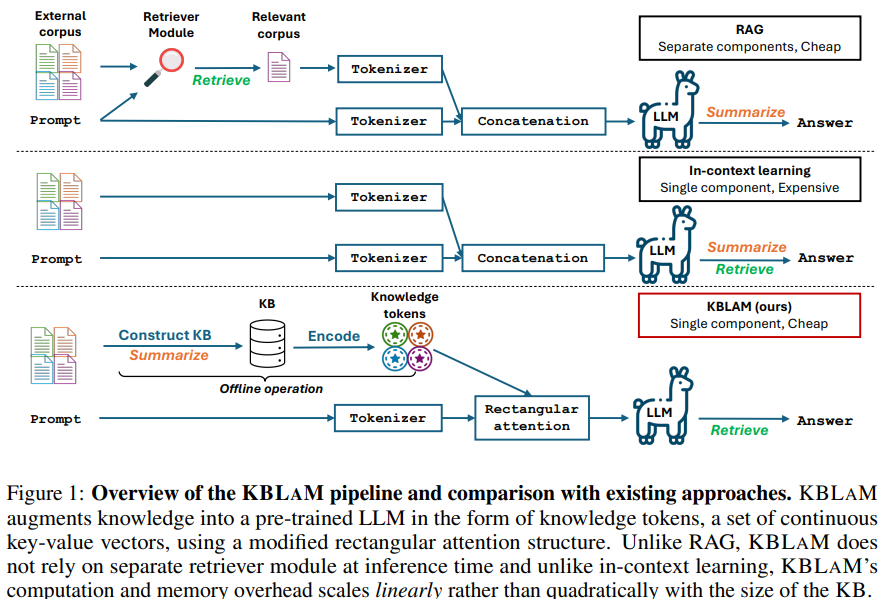
در نتیجه، KBLAM یک رویکرد برای افزایش LLMها با KBهای خارجی است. این روش ورودیهای KB را به عنوان جفتهای برداری کلید-مقدار پیوسته با استفاده از رمزگذارهای جمله از پیش آموزشدیده با آداپتورهای خطی رمزگذاری میکند و آنها را از طریق یک مکانیسم توجه تخصصی در LLMها ادغام میکند. برخلاف تولید تقویتشده با بازیابی، KBLAM ماژولهای بازیابی خارجی را حذف میکند و برخلاف یادگیری در متن، با اندازه KB به صورت خطی مقیاس مییابد. این امر امکان ادغام کارآمد بیش از 10 هزار سهتایی را در یک LLM 8B در یک پنجره متنی 8K روی یک GPU A100 فراهم میکند. آزمایشها اثربخشی آن را در پاسخگویی به پرسشها و وظایف استدلال در حین حفظ قابلیت تفسیر و فعالسازی بهروزرسانیهای پویای دانش نشان میدهد.
مقاله را بررسی کنید و صفحه GitHub. تمام اعتبار این تحقیق به محققان این پروژه میرسد. همچنین، در توییتر ما را دنبال کنید و فراموش نکنید که به 85k+ ML SubReddit ما بپیوندید.
درباره نویسنده: ثنا حسن
ثنا حسن، کارآموز مشاوره در Marktechpost و دانشجوی دو رشتهای در IIT Madras، مشتاقانه به کاربرد فناوری و هوش مصنوعی برای رسیدگی به چالشهای دنیای واقعی میپردازد. او با علاقه فراوان به حل مسائل عملی، دیدگاه تازهای را به تقاطع هوش مصنوعی و راهحلهای واقعی زندگی میآورد.