این یک راز سر به مهر است که آزمایشگاههای پیشرو هوش مصنوعی چگونه تیمهای آموزشی خود را سازماندهی میکنند. مانند سایر شرکتهای فناوری، این گفته که "شما نمودار سازمانی خود را ارائه میدهید" هنوز در مورد آموزش مدلهای هوش مصنوعی صدق میکند. نگاهی به این ساختارهای سازمانی نشان میدهد که تحقیق در کجا میتواند مقیاسبندی شود، محدودیتهای بالای اندازه چیست و حتی به طور بالقوه چه کسی از بیشترین محاسبات استفاده میکند.
نحوه کارکرد و عدم کارکرد تیمهای مدلسازی
حوزه مهمی که روی آن کار میکنم (اگر میخواهید اطلاعات بیشتری را به صورت غیررسمی به اشتراک بگذارید، با من تماس بگیرید) این است که چگونه این درسها را به تیمهای بزرگتر و پیچیدهتر تعمیم دهیم. عامل اصلی تمایز تیمهایی که موفق میشوند از تیمهایی که موفق نمیشوند، حفظ این اصول در حین مقیاسبندی اندازه تیم است.
تیمهای بزرگ ذاتاً منجر به سیاست و محافظت از قلمرو میشوند، در حالی که مدلهای زبانی نیاز دارند که اطلاعات از پایین به بالا در مورد قابلیتهای ممکن جریان یابد. صرف نظر از امکانات، رهبری میتواند منابع را برای اولویتبندی حوزههای خاص تغییر دهد، اما تمام سیگنالهای مربوط به اینکه آیا این کار مؤثر است یا خیر، از کسانی که مدلها را آموزش میدهند میآید. اگر مدیران ارشد قبل از رفع انسداد نسخههای مدل، نتایج را تحت امر خود اجباری کنند، کل سیستم از هم میپاشد.
با دیدن این حالت نهایی بالقوه - بدون نام بردن از شرکتهای خاص - بدیهی است که اجتناب از آن مطلوب است، اما پیشبینی و اجتناب از آن در طول رشد سریع، نیازمند تعهد قابل توجهی است.
در داخل آموزش، برنامهریزی برای پیشآموزش و پسآموزش به طور سنتی میتواند متفاوت مدیریت شود. پیشآموزش تعداد کمتری دارد، اما اجراهای بزرگتری دارد، بنابراین بهبودها باید برای آن تعداد اجراهای سالانه در نظر گرفته شوند. بهبودهای پسآموزش عمدتاً میتواند مستمر باشد. این تفاوتهای عملیاتی، علاوه بر تفاوتهای آشکار هزینهها، باعث میشود پسآموزش برای آزمایشگاههای غیر پیشرو بسیار در دسترستر باشد (اگرچه هنوز بسیار سخت است).
هر دو تیم دارای گلوگاههایی هستند که باید بهبودها در آن ادغام شوند. به نظر میرسد مقیاسبندی گلوگاههای پیشآموزش - یعنی کسانی که تصمیمات نهایی معماری و داده را میگیرند - غیرممکن است، اما مقیاسبندی تیمها در اطراف کسب داده، ایجاد ارزیابی و یکپارچهسازی بسیار آسان است. بخش عمدهای از تصمیمات محصول برای مدلهای هوش مصنوعی را میتوان بدون توجه به تصمیمات مدلسازی اتخاذ کرد. مقیاسبندی این موارد نیز آسان است.
به طور مؤثر، سازمانهایی که نمیتوانند مدلهای پیشگامانه تولید کنند، میتوانند تحقیقات معنادار سطح پایین زیادی انجام دهند، اما افزودن پیچیدگی سازمانی به طور چشمگیری خطر "عدم توانایی در کنار هم قرار دادن آن" را افزایش میدهد.
یکی دیگر از حالتهای شکست توسعه از بالا به پایین، به جای اطلاعات از پایین به بالا، این است که رهبران میتوانند به تیم دستور دهند که سعی کند از یک تصمیم فنی پیروی کند که توسط آزمایشها پشتیبانی نمیشود. مدیریت به اصطلاح "اجراهای یولو" به خوبی یک مهارت ارزشمند است، اما مهارتی است که نزدیک به مدلها نگهداری میشود. البته، تکنیکهای بسیار زیادی هنوز کار میکنند که دستورات نرخ شکست 100٪ ندارند، اما یک سابقه بد ایجاد میکند.
با توجه به سرعت انتشار و پیشرفت، به نظر میرسد که Anthropic، OpenAI، DeepSeek، Google Gemini و برخی دیگر اشکال مثبتی از این فرهنگ از پایین به بالا با سرپرستان فنی بسیار ماهر که پیچیدگی را مدیریت میکنند، دارند. گوگل برای درست کردن آن با سازماندهی مجدد، پرتابهای آشفته (به یاد داشته باشید Bard) و غیره، طولانیترین زمان را صرف کرد. با فاصله زمانی بین نسخههای متا، هنوز به نظر میرسد که آنها در تلاشند تا این فرهنگ را پیدا کنند تا استعداد و منابع فوقالعاده خود را به حداکثر برسانند.
با همه اینها و مکالمات غیررسمی با رهبری در آزمایشگاههای پیشرو هوش مصنوعی، فهرستی از توصیهها را برای مدیریت تیمهای آموزش هوش مصنوعی گردآوری کردهام. این بر تحقیقات مدلسازی متمرکز است و اکثریت پرسنل در شرکتهای پیشرو هوش مصنوعی را در بر نمیگیرد.
توصیهها
مؤثرترین تیمهایی که به طور منظم مدلهای پیشرو را ارسال میکنند، از بسیاری از این اصول پیروی میکنند:
- تیمهای اصلی مدلسازی زبانی با بزرگتر شدن شرکتهای هوش مصنوعی، کوچک باقی میمانند.
- برای تیمهای کوچکتر، شما هنوز هم میتوانید همه را در یک اتاق داشته باشید، از این مزیت استفاده کنید. برای من شخصاً، فکر میکنم اینجاست که تیمهای راه دور میتوانند مضر باشند. حضوری برای این کار جواب میدهد، حداقل زمانی که بهترین شیوهها به سرعت در حال تکامل هستند.
- از سیلوهای اطلاعاتی اجتناب کنید. این هم برای تیمها و هم برای افراد صادق است. افراد باید بتوانند به سرعت بر اساس موفقیتهای اطرافیان خود بنا کنند و ارتباط واضح در طول پیشرفت سریع مداوم دشوار است.
- برای تیمهای بزرگتر، شما میتوانید تیمها را فقط در جایی مقیاسبندی کنید که طراحی مشترک مورد نیاز نیست. در جایی که تعاملات مورد نیاز نیست، میتواند فاصله سازمانی وجود داشته باشد.
- یک مثال این است که یک تیم بر الگوریتمها و رویکردهای پسآموزش تمرکز کند، در حالی که تیمهای دیگر شخصیت مدل، انواع مدل برای API و غیره (مشخصات و تکرارها) را مدیریت میکنند.
- مثال دیگر این است که تیمهای استدلال اغلب از سایر قطعات پسآموزش جدا هستند. این فقط برای بازیکنانی اعمال میشود که مقیاسبندی شدهاند.
- استقرار مدل زبانی بسیار شبیه به نرمافزار اولیه استارتآپ است. شما دقیقاً نمیدانید کاربران چه میخواهند و نه آنچه میتوانید ارائه دهید. عدم قطعیت را در آغوش بگیرید و به سرعت یاد بگیرید.
- سعی نکنید بیش از حد تیمهای مهندسی را از آموزش جدا کنید. مهندسی باید ابزارهایی برای مدل نسل +1 بسازد و نمیتواند این کار را بدون صحبت با محققان انجام دهد.
- تحقیقات همیشه سبز از تیمهای مدلسازی زبانی جدا است، اما هنوز در داخل "تحقیق" قرار دارد. در غیر این صورت، اولویتبندی ایدههای واقعاً بلندمدت غیرممکن خواهد بود. اهداف بلندمدت شکننده هستند و نیاز به پرورش دارند. مدلسازی زبانی در مورد 1 یا شاید 2 مدل بعدی است.
- بسیاری از کارهای جذاب چندان مفید نیستند و بسیاری از کارهای مفید جذاب نیستند. داده مثال اصلی به عنوان اغلب تأثیرگذارترین نوع کار است.
- انتظار داشته باشید آموزشها با شکست مواجه شوند و در طول مسیر به آنها واکنش بیش از حد نشان ندهید.
حالتهای شکست
پروژههای با اولویت بالا میتوانند شکست بخورند اگر شما…
- سعی کنید برای هر بهبود قابلیت، مدلهای زیادی را ارسال کنید. در عوض، به یک برنامه زمانی مشخص از آموزش مدل پایبند باشید. مدلهای کمتری داشته باشید که توانمندتر هستند.
- سعی کنید سهم از هم تیمیهای فردی را در محصول نهایی اجباری کنید. عملکرد را به خاطر شخصیتها در جستجوی "سهم" قربانی نکنید.
- اجازه دهید تیمهایی وارد شوند که سعی میکنند به زور قلمرو خود را وارد مشارکت در هدف بزرگ شرکت کنند.
- سازمان آموزش را بیش از حد مقیاسبندی کنید. داشتن افراد زیاد "انجام دادن کارها" و افزودن سر و صدا به سازمان، از جهتگیری سطح بالا و تمرکز بر اجرای اهداف خاص میکاهد. (این همچنین میتواند به 1 مربوط شود و سعی در انجام کارهای زیاد در یک مدل داشته باشد).
- اجازه دهید سیاست رشد کند، اشکال مختلفی به خود بگیرد و باعث مسائل درهم تنیده شود. حس اینکه نتایج عامل اصلی تصمیمات هستند را از دست ندهید. تصمیمات بد در اینجا ترکیب میشوند.
- بیش از حد فهرست کردن در یک ارزیابی مدل واحد، مانع پیشرفت واقعی در زمینههای دیگر میشود (یا به طور کامل مانع میشود).
قبل از بقیه پست، گسترش موضوعات بالا، ممکن است به مقالات قبلی در مورد این موضوع علاقه مند باشید.
نوشتههای مرتبط
برای مطالعه بیشتر در مورد نحوه کار تیمهای مدلسازی زبانی، برخی از نوشتههای دیگر من را در اینجا، در مورد ساختار تیم و…
OLMo 2 و ساخت تیمهای مؤثر برای آموزش مدلهای زبانی
Nathan Lambert · November 26, 2024
مدیریت ریسک.
OLMoE و سادگی پنهان در آموزش مدلهای پایه بهتر
Nathan Lambert · September 4, 2024
نمونهای از نحوه کار پروژههای آموزشی با اندازه متوسط
من اخیراً فهرستی از سؤالات در مورد نحوه عملکرد آموزش برای Tülu 3 دریافت کردم (که در واقع یک آنالوگ پسآموزشی برای OLMo است). من فکر کردم اینها را به اشتراک میگذارم و آنها به عنوان پایهای برای جمعآوری اطلاعات مفید از دوستان در آزمایشگاههای پیشرو در مورد میزان نمایندگی آن عمل میکنند.
با مدلهای استدلال، بیشتر اینها مستقیماً ترجمه میشوند. زیرساختها مهمتر میشوند زیرا تولید توالیهای طولانی به ویژه حافظه فشرده است (و میتواند مسائل مربوط به ابزارهای منبع باز را برای استنتاج نشان دهد)، اما وقتی زمان تهیه یک دستور العمل استدلالی کاملاً باز و پیشرفته فرا میرسد، درسهای آموخته شده در اینجا مستقیماً اعمال میشوند.
1. یک پروژه بزرگ پسآموزشی چقدر طول میکشد؟
Tülu 3 از اواسط جولای تا زمان انتشار آن در 21 نوامبر 2024، تمرکز تیم پسآموزش ما بود. ما بر اساس دستور العملهای قبلی خود در Tülu 2/2.5 بنا میکردیم، بنابراین چیز زیادی از این برای جبران دانش داخلی نبود، بلکه ادغام منابع خارجی جدید بود. اگر تیمی مانند این به طور مداوم تمام سال را روی همان تمرکز کار میکرد، تقریباً یک ماه کمتر طول میکشید تا به این نتایج دست یابد. راه اندازی زمان قابل توجهی میبرد، همانطور که مدیریت انتشار نیز زمان بر است.
2. چگونه پرسنل مناسب را برای یک پروژه آموزشی با اندازه متوسط انتخاب میکنید؟
پروژهای مانند Tülu 3 یا هر تلاش دیگری برای پیشبرد مرزهای هوش مصنوعی در یک حوزه محبوب، معمولاً یک تیم با اندازه متوسط را میطلبد. هرچه جایگاه کوچکتر باشد، تیم کوچکتری نیاز دارید. تیم در Ai2 در مقایسه با مهندس سنگین در بین بیش از 20 نویسنده، محقق سنگین است. اگر فقط اولویتبندی عملکرد در تکنیکهای شناخته شده باشد، نسبت مهندسان میتواند بسیار بیشتر باشد. پیشبرد مرزها 10 برابر منابع بیشتری نسبت به تکرار کارهای مستند شده گسترده نیاز دارد.
در مورد Tülu 3، جایی که بیشتر تکنیکها ناشناخته هستند، بدیهی است که نسبت محققان بالاتر است. این، اگرچه، برای شرکتهایی که سعی در محدود کردن افرادی دارند که برای تیمهای مدلسازی استخدام کنند، یک مشکل بیاهمیت نیست. اول، باید سطح عدم قطعیت را در دامنه مورد علاقه تعیین کرد و سپس در اطراف آن استخدام کرد. استفاده از رویکردهای سبک Tülu قطعاً میتواند با تیمی متشکل از 2-4 مهندس متمرکز انجام شود.
3. از چه اندازههای مدلی برای تکرار استفاده میشود؟ نتایج چگونه مقیاس میشوند؟
یک اصل اصلی تحقیقات مدلسازی، تکرار در کوچکترین مدلی است که یک سیگنال قابل اعتماد ارائه میدهد. این کل اصل پشت قوانین مقیاسبندی به عنوان یک ابزار کاهش خطر است. در پسآموزش، هزینههای محاسباتی به طور قابل توجهی کمتر است، بنابراین مدلهای مورد استفاده در واقع میتوانند بزرگتر باشند. در این مورد، با توجه به پروژهای که بر اساس مدلهای پایه Llama 3.1 طراحی شده است، 80٪ یا بیشتر از آزمایشها در مقیاس 8B بود (معمولاً 8 یا 32 H100، در <1 روز به پایان میرسد)، ~ 19٪ در مقیاس 70B (معمولاً 32 یا 64 H100، در 2-3 روز به پایان میرسد) و فقط تعداد انگشت شماری از اجراها در مقیاس 405B که هر کدام از 256 GPU برای چندین روز استفاده میکردند. در استفاده کلی از GPU، پروژه به طور همزمان از 100-600 GPU برای کل دوره 4-5 ماهه استفاده کرد.
این روزها، نتایج تمایل دارند هنگام مقیاسبندی بسیار خوب انتقال یابند. مدلهای بزرگتر ممکن است به دادههای کمتری نیاز داشته باشند، به ویژه دادههای عمومی کمتر، و یک بهینهسازی ملایمتر (معمولاً نرخ یادگیری پایینتر)، اما انتقال چالش برانگیز نبوده است. تغییر مدلهای پایه سختتر از مقیاسبندی با تکنیکهای پسآموزش است.
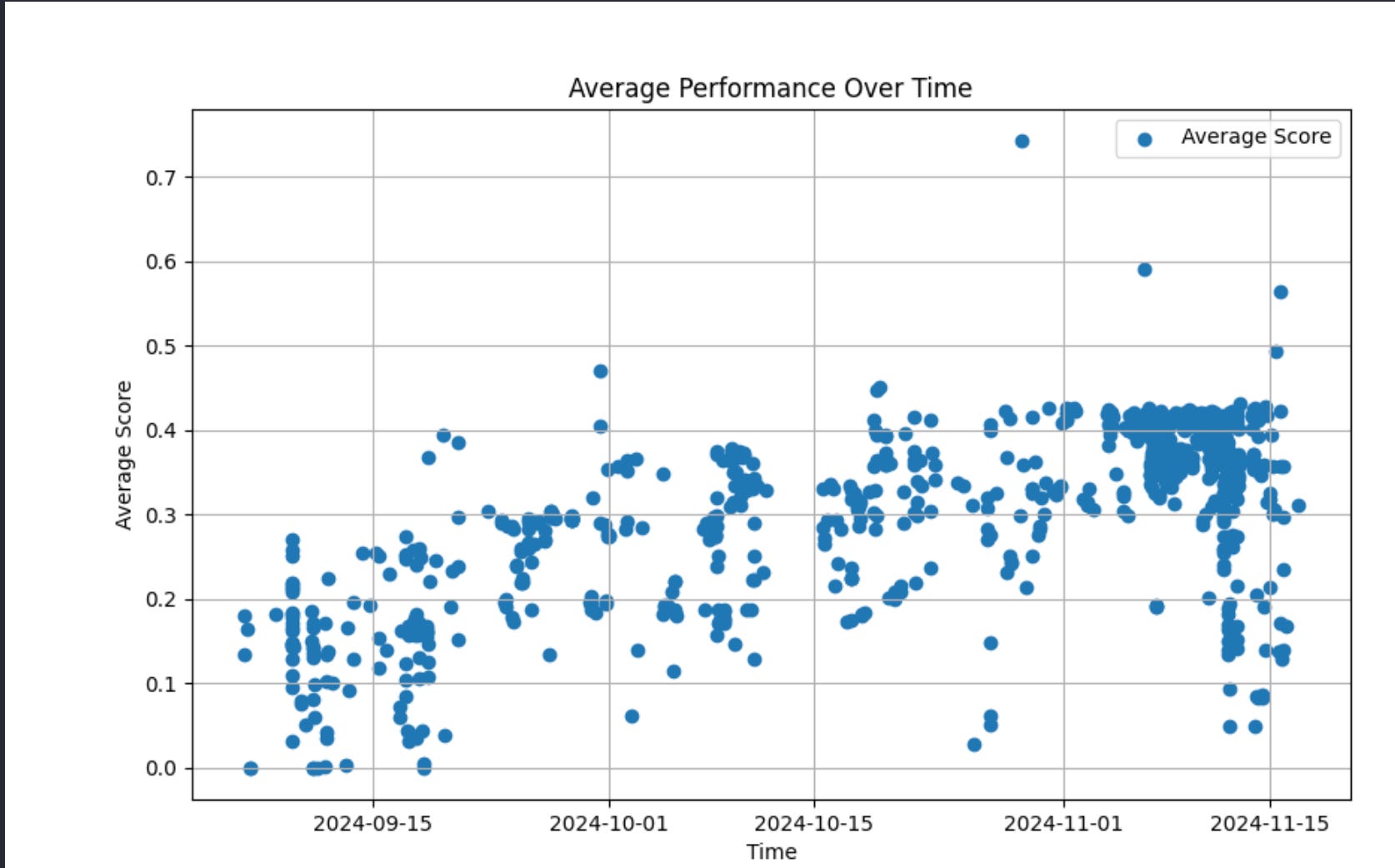
4. در واقع چند آزمایش اجرا میشود؟
پروژه Tülu حدود 1000 ایست بازرسی را در فرآیند ما ارزیابی کرد. این برای یک فرآیند بزرگ پسآموزشی درست به نظر میرسد. برخی از اینها مدلهای واسطه یا رقیب هستند، اما بیشتر آنها، 100، اجراهای آموزشی آزمایشی هستند. نمرات مدل را میتوان در یک توالی زمانی با فرادادهای که جمعآوری کردهایم، ترسیم کرد. وقتی نیم نگاهی میاندازید، عمدتاً یک منحنی لگاریتمی با دستاوردهای سریعتر در ابتدا و هموار شدن در انتها است. البته، شما همچنین میتوانید هجوم مدلهایی را که درست در چند هفته آخر آموزش داده شدهاند، ببینید.
5. بزرگترین گلوگاه در پیشرفت چیست؟
همه این پروژهها با محاسباتی که در دسترس است گلوگاه دارند. کارآمدتر کردن سیستمها یک ضرب کننده محاسباتی است، اما اگر نقطه شروع در تعداد GPUها خیلی کم باشد، مهم نیست. اغلب پتانسیل تسریع پروژهها با افزودن افراد بیشتر به اکتشافات وجود دارد، چه رویکردهای آموزشی مانند مدلهای پاداش فرآیند (PRM) یا جمعآوری دادهها، اما مقیاسبندی مدیریت و یکپارچهسازی دادهها در ارزیابیهای متعدد میتواند دشوار باشد. بهترین شیوهها برای مدلهایی با 100 ارزیابی هدف (همانطور که در آزمایشگاههای پیشرو انجام میشود) به جای ~10 مورد استفاده ما، هنوز بسیار دور از استقرار هستند.
دومین گلوگاه پرسنلی است که مایل به آسیاب مداوم روی آزمایشهای داده جدید هستند. تمرکز بر داده تقریباً همیشه نسبتاً سریع نتیجه میدهد.
6. برای شروع یک تلاش جدی پسآموزشی از یک شروع سرد به چه چیزی نیاز دارم؟
تنظیم دقیق درجه بندی بسیار زیادی دارد که میتوان تقریباً با هر اندازه تیم تأثیرگذار بود. برای انجام کارهای واقعاً عالی بیشتر صبر و منابع متناسب لازم است. درست کردن دقیق مدل نیاز به آموزش مجدد بارها و بارها دارد حتی پس از رسیدن به اهداف اولیه معیار خود.
برای شرکتهایی که بر مدلهای محلی تمرکز دارند، چند گره H100 (~100 GPU) میتواند راه طولانی را طی کند. برای شرکتهایی که سعی در ساخت مدلهای واقعاً پیشرفته بالای مقیاس 7B دارند، تلاش برای انجام این کار با <500 H100 GPU بعید است که ارزش آن را داشته باشد. بسیار آسان است که در وسط گیر کنید و محاسبات هنوز بزرگترین عامل تعیین کننده موفقیت است.
این اعداد با استقرار بهترین شیوههای تقطیر از مدلهای قوی کاهش مییابند، اما این دانش هنوز بسیار دور از شناخته شدن است. اگر میخواهید در آموزش سرمایهگذاری کنید، باید به اندازه کافی برای پیشبرد مرزها انجام دهید، در غیر این صورت ناگزیر عقب خواهید ماند و بهتر است از دنباله دیگران استفاده کنید.
7. سختترین بخش این پروژهها چیست؟ در واقع کجا وقت میگذرانید؟
پروژههای آموزشی زمان و تمرکز زیادی را میطلبند تا به جزئیات توجه شود. تیمها برای تمرکز بر هدف واحد آموزش، نیاز به انزوای شدید از سایر اهداف شرکت دارند. سختترین بخش اغلب همین است - داشتن همه اعضای تیم آموزشی که بر یک خروجی واحد برای دورههای پایدار تمرکز کنند. پیگیری تحولات اخیر، آزمایشهای کوچک با الگوریتمهای آموزشی، جمعآوری دادهها (به احتمال زیاد بیشتر زمان در ساعت به عنوان پرستاری از GPUها تا حد زیادی یک فعالیت بیکار است) و غیره، همه نان و کره استعداد مهندسی جامد هستند. موفقیت ناشی از تصمیمگیری خوب توسط سرپرستان فنی و مدیران است در حالی که عکسهای کوچک زیادی روی هدف میزنند.
در مورد پروژههایی مانند Tülu 3، دلیل اینکه ما بلافاصله به Tülu 4 نمیرویم این است که افراد علاقههای دیگری دارند. شرکتهایی که مستقیماً آموزش را با سود خود همسو میکنند، نیازی به انجام این کار ندارند.
با تشکر از نیکول فیتزجرالد، فینبار تیمبرز (Midjourney یکی از شرکتهایی نبود که من مطالعه کردم) و دیگران که نامشان برده نشد در آزمایشگاههای پیشرو هوش مصنوعی برای نظرات یا ورودیهایی که به این پست کمک کردند.