
در NVIDIA GTC25، کارشناسان Gnani.ai از پیشرفتهای چشمگیر در هوش مصنوعی صوتی پرده برداشتند و بر توسعه و استقرار مدلهای بنیادین گفتار به گفتار تمرکز کردند. این رویکرد نوآورانه وعده میدهد که بر محدودیتهای معماریهای آبشاری سنتی هوش مصنوعی صوتی غلبه کرده و عصر تعاملات صوتی یکپارچه، چندزبانه و آگاه از احساسات را آغاز کند.
محدودیتهای معماریهای آبشاری
معماری پیشرفته کنونی که به عوامل صوتی نیرو میدهد، شامل یک خط لوله سه مرحلهای است: گفتار به متن (STT)، مدلهای زبانی بزرگ (LLM) و متن به گفتار (TTS). در حالی که این معماری موثر است، از معایب قابل توجهی رنج میبرد، که عمدتاً شامل تأخیر و انتشار خطا است. یک معماری آبشاری دارای بلوکهای متعددی در خط لوله است و هر بلوک تأخیر خاص خود را اضافه میکند. تأخیر تجمعی در این مراحل میتواند از ۲.۵ تا ۳ ثانیه متغیر باشد که منجر به تجربه کاربری ضعیف میشود. علاوه بر این، خطاهایی که در مرحله STT معرفی میشوند، در طول خط لوله منتشر شده و باعث افزایش نادرستیها میشوند. این معماری سنتی همچنین ویژگیهای مهم فرازبانی مانند احساسات، عواطف و لحن را از دست میدهد و در نتیجه پاسخهایی یکنواخت و از نظر عاطفی مسطح ایجاد میکند.
معرفی مدلهای بنیادین گفتار به گفتار
به منظور رفع این محدودیتها، Gnani.ai یک مدل بنیادین گفتار به گفتار جدید ارائه میدهد. این مدل به طور مستقیم صدا را پردازش و تولید میکند و نیاز به نمایشهای متنی واسط را از بین میبرد. نوآوری کلیدی در آموزش یک رمزگذار صوتی عظیم با ۱.۵ میلیون ساعت داده برچسبگذاری شده در ۱۴ زبان نهفته است که تفاوتهای ظریف احساسات، همدلی و لحن را ثبت میکند. این مدل از یک رمزگذار XL تودرتو استفاده میکند که با دادههای جامع دوباره آموزش داده شده است و یک لایه پروژکتور صوتی ورودی برای نگاشت ویژگیهای صوتی به جاسازیهای متنی به کار میرود. برای پخش جریانی بیدرنگ، ویژگیهای صوتی و متنی با هم درآمیخته میشوند، در حالی که موارد استفاده غیر جریانی از یک لایه ادغام جاسازی استفاده میکنند. لایه LLM که در ابتدا مبتنی بر Llama 8B بود، برای شامل شدن ۱۴ زبان گسترش یافت و نیاز به بازسازی توکنسازها داشت. یک مدل پروژکتور خروجی، طیفنگاشتهای mel را تولید میکند و امکان ایجاد صداهای فوقالعاده شخصیسازی شده را فراهم میکند.
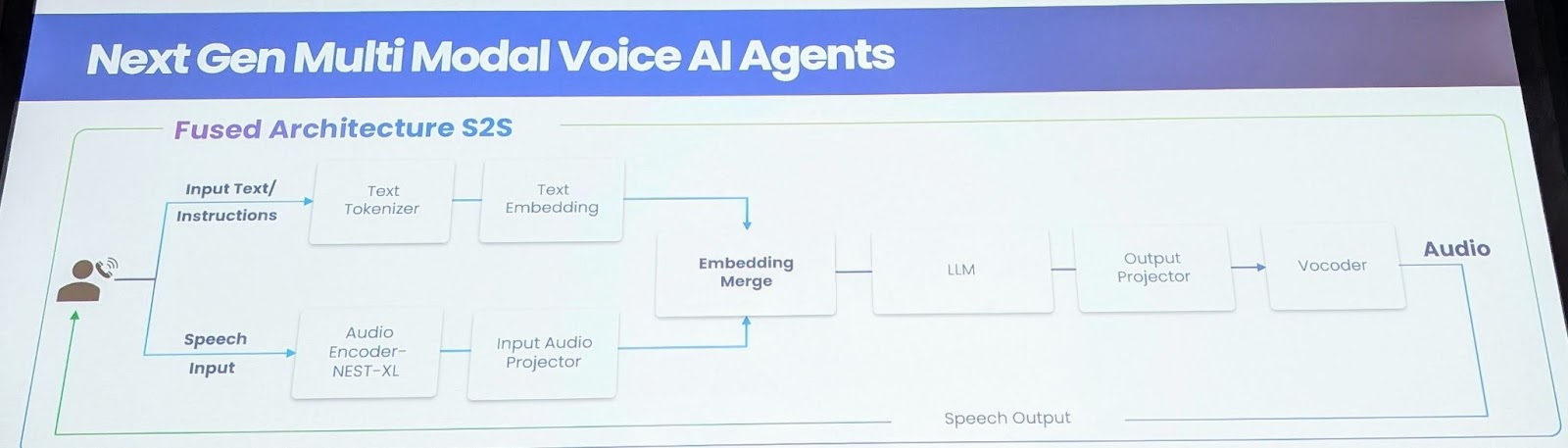
مزایای کلیدی و موانع فنی
مدل گفتار به گفتار چندین مزیت قابل توجه ارائه میدهد. اولا، این مدل به طور قابل توجهی تأخیر را کاهش میدهد و از ۲ ثانیه به تقریبا ۸۵۰-۹۰۰ میلی ثانیه برای خروجی اولین توکن میرسد. ثانیا، با ادغام ASR با لایه LLM، دقت را افزایش میدهد و عملکرد را به ویژه برای سخنرانیهای کوتاه و طولانی بهبود میبخشد. ثالثا، این مدل با ضبط و مدلسازی لحن، استرس و سرعت گفتار، به آگاهی عاطفی دست مییابد. رابعا، این مدل از طریق آگاهی متنی، امکان مدیریت بهبود یافته وقفه را فراهم میکند و تعاملات طبیعیتری را تسهیل میکند. در نهایت، این مدل برای مدیریت موثر صدای کم پهنای باند طراحی شده است که برای شبکههای تلفنی بسیار مهم است. ساخت این مدل چالشهای متعددی را به همراه داشت، به ویژه نیازهای عظیم داده. این تیم یک سیستم جمعسپاری با ۴ میلیون کاربر ایجاد کرد تا دادههای مکالمهای غنی از نظر احساسی تولید کند. آنها همچنین از مدلهای بنیادین برای تولید دادههای مصنوعی استفاده کردند و بر روی ۱۳.۵ میلیون ساعت داده در دسترس عموم آموزش دیدند. مدل نهایی شامل یک مدل پارامتری ۹ میلیارد است که ۶۳۶ میلیون برای ورودی صوتی، ۸ میلیارد برای LLM و ۳۰۰ میلیون برای سیستم TTS در نظر گرفته شده است.
نقش NVIDIA در توسعه
توسعه این مدل به شدت به پشته NVIDIA متکی بود. NVIDIA Nemo برای آموزش مدلهای رمزگذار-رمزگشا استفاده شد و NeMo Curator تولید دادههای متنی مصنوعی را تسهیل کرد. NVIDIA EVA برای تولید جفتهای صوتی، ترکیب اطلاعات اختصاصی با دادههای مصنوعی به کار گرفته شد.
موارد استفاده
Gnani.ai دو مورد استفاده اصلی را به نمایش گذاشت: ترجمه زبانی بیدرنگ و پشتیبانی مشتری. نسخه نمایشی ترجمه زبانی بیدرنگ شامل یک موتور هوش مصنوعی بود که مکالمه بین یک نماینده انگلیسی زبان و یک مشتری فرانسوی زبان را تسهیل میکرد. نسخه نمایشی پشتیبانی مشتری، توانایی مدل در مدیریت مکالمات بین زبانی، وقفهها و تفاوتهای ظریف احساسی را برجسته کرد.
مدل بنیادین گفتار به گفتار
مدل بنیادین گفتار به گفتار نشاندهنده یک جهش قابل توجه رو به جلو در هوش مصنوعی صوتی است. این مدل با از بین بردن محدودیتهای معماریهای سنتی، تعاملات صوتی طبیعیتر، کارآمدتر و آگاهانهتر از نظر احساسی را امکانپذیر میکند. با ادامه تکامل این فناوری، وعده میدهد که صنایع مختلف، از خدمات مشتری گرفته تا ارتباطات جهانی را متحول کند.