ترجمه ماشینی (MT) به عنوان یک جزء حیاتی از پردازش زبان طبیعی (Natural Language Processing) ظهور کرده است و تبدیل خودکار متن بین زبانها را برای پشتیبانی از ارتباطات جهانی تسهیل میکند. در حالی که ترجمه ماشینی عصبی (NMT) با استفاده از تکنیکهای یادگیری عمیق برای ثبت الگوهای زبانی پیچیده و وابستگیهای متنی، انقلابی در این زمینه ایجاد کرده است، چالشهای قابل توجهی همچنان وجود دارد. سیستمهای NMT فعلی برای ترجمه دقیق اصطلاحات اصطلاحی، مدیریت مؤثر زبانهای کممنبع با دادههای آموزشی محدود و حفظ انسجام در اسناد طولانیتر تلاش میکنند. این محدودیتها به طور قابل توجهی بر کیفیت ترجمه و قابلیت استفاده در سناریوهای دنیای واقعی تأثیر میگذارد.
مدلهای زبانی بزرگ (LLM) مانند GPT-4، LLaMA و Qwen انقلابی در MT ایجاد کردهاند و قابلیتهای چشمگیری را در سناریوهای ترجمه صفر-شات و چند-شات بدون نیاز به پیکرههای موازی گسترده نشان میدهند. چنین LLMهایی به عملکردی قابل مقایسه با سیستمهای نظارتشده دست مییابند و تطبیقپذیری را در انتقال سبک، خلاصهسازی و وظایف پرسش و پاسخ ارائه میدهند. مدلهای استدلال بزرگ (LRM) که بر اساس LLMها ساخته شدهاند، نشاندهنده گام تکاملی بعدی در MT هستند. LRMها قابلیتهای استدلال را از طریق تکنیکهایی مانند استدلال زنجیرهای (Chain-of-Thought reasoning) ادغام میکنند و به ترجمه به عنوان یک وظیفه استدلال پویا به جای یک تمرین نقشهبرداری ساده نگاه میکنند. این رویکرد LRMها را قادر میسازد تا به چالشهای مداوم در ترجمه، از جمله انسجام متنی، ظرافتهای فرهنگی و تعمیم ترکیبی رسیدگی کنند.
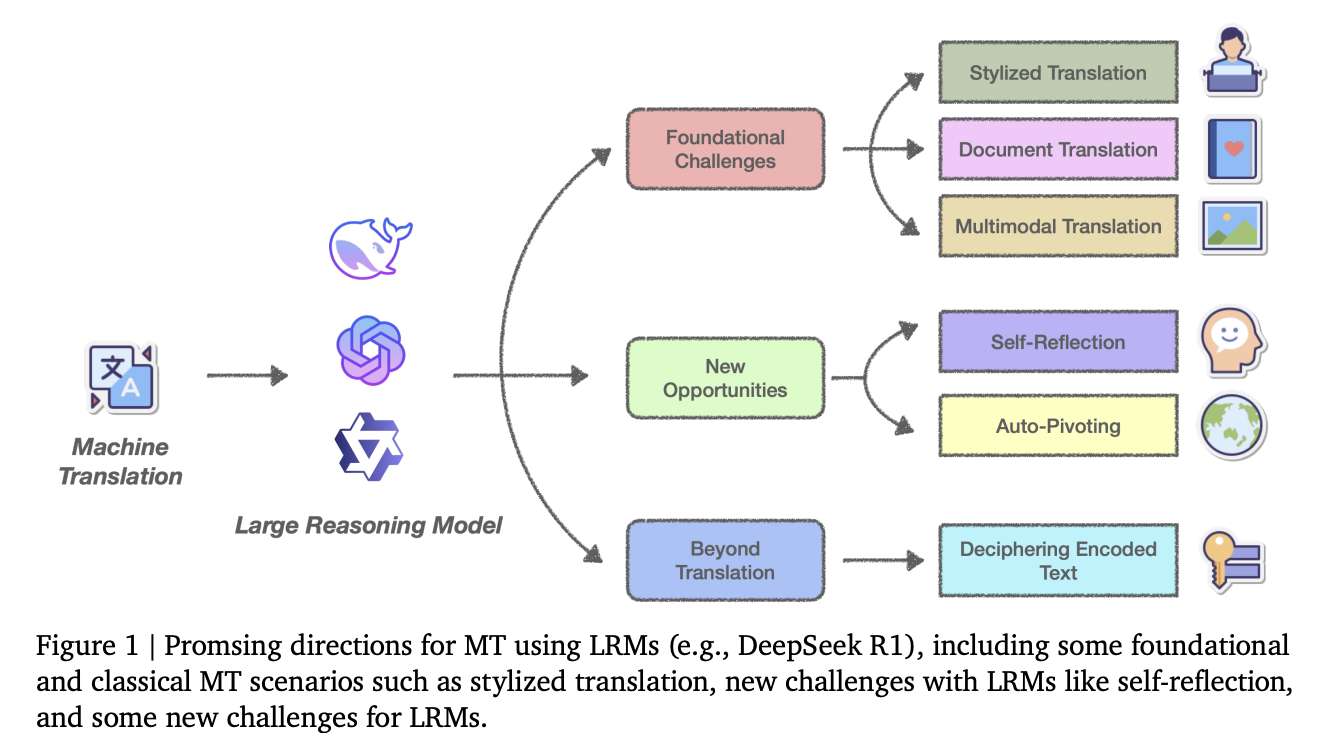
محققان تیم MarcoPolo، تجارت دیجیتال بینالمللی علیبابا و دانشگاه ادینبورگ رویکردی متحولکننده برای MT با استفاده از LRMها ارائه میدهند. مقاله موضعی آنها ترجمه را به عنوان یک وظیفه استدلال پویا با نیاز به درک عمیق متنی، فرهنگی و زبانی به جای نقشهبرداری ساده متن به متن، بازتعریف میکند. محققان سه تغییر اساسی را شناسایی میکنند که توسط LRMها امکانپذیر شدهاند، که عبارتند از: (الف) انسجام متنی برای رفع ابهامات و حفظ ساختار گفتمان در زمینههای پیچیده، (ب) قصد فرهنگی برای انطباق ترجمهها بر اساس قصد گوینده و هنجارهای اجتماعی-زبانی، و (ج) قابلیتهای خودبازتابی که به مدلها اجازه میدهد تا ترجمهها را در طول استنتاج به صورت تکراری اصلاح کنند. این تغییرات LRMها را به عنوان برتر از رویکردهای سنتی NMT و مبتنی بر LLM قرار میدهد.
ویژگیهای LRMها در MT شامل خودبازتابی و ترجمه خودکار-محور است. خودبازتابی مدلها را قادر میسازد تا تشخیص خطا و تصحیح را در طول فرآیند ترجمه انجام دهند، که هنگام کار با ورودیهای مبهم یا پر سر و صدا، مانند متنی که حاوی غلط املایی یا جملات درهم ریخته است که سیستمهای مرسوم برای تفسیر دقیق آنها مشکل دارند، ارزشمند است. در پدیده ترجمه خودکار-محور، LRMها به طور خودکار از زبانهای پرمنبع به عنوان واسطه هنگام ترجمه بین جفت زبانهای کممنبع استفاده میکنند، به عنوان مثال، هنگام ترجمه از ایرلندی به چینی، مدل به طور داخلی از طریق انگلیسی استدلال میکند قبل از تولید خروجی نهایی. با این حال، این رویکرد چالشهای بالقوهای را در مورد کارایی محاسباتی و اعوجاجهای احتمالی در زمانی که عبارات معادل در زبان محور وجود ندارند، معرفی میکند.
هنگامی که با استفاده از معیارهایی مانند BLEURT و COMET ارزیابی شد، هیچ تفاوت قابل توجهی بین چهار مدل آزمایش شده ظاهر نشد، اما مدلهایی با نمرات پایینتر ترجمههای بهتری تولید کردند. به عنوان مثال، DeepSeek-R1 ترجمههای بهتری را در مقایسه با DeepSeek-V3 تولید کرد. علاوه بر این، مدلهای تقویتشده با استدلال، ترجمههای متنوعتری تولید میکنند که ممکن است با ترجمههای مرجع متفاوت باشند در حالی که دقت و بیان طبیعی را حفظ میکنند. برای مثال، برای جمله "? ??????? ??"، ترجمه مرجع "The orchard worker in the orchard is harvesting" است. DeepSeek-R1 آن را به عنوان "The orchard farmers are harvesting" ترجمه کرد، با نمره COMET 0.7748، و ترجمه تولید شده توسط DeepSeek-V3 "The orchard farmers are currently harvesting the fruits" است که نمره COMET 0.8039 را دریافت کرد.
در این مقاله، محققان پتانسیل تحولآفرین LRMها را در MT بررسی کردهاند. LRMها به طور موثر با استفاده از قابلیتهای استدلال، از جمله ترجمه سبکدار، ترجمه در سطح سند و ترجمه چندوجهی، به چالشهای دیرینه رسیدگی میکنند، در حالی که قابلیتهای نوآورانهای مانند خودبازتابی و ترجمه زبان خودکار-محور را معرفی میکنند. با این حال، محدودیتهای قابل توجهی، به ویژه در وظایف استدلال پیچیده و حوزههای تخصصی، همچنان وجود دارد. در حالی که LRMها میتوانند با موفقیت رمزهای ساده را رمزگشایی کنند، اما با چالشهای رمزنگاری پیچیده دست و پنجه نرم میکنند و ممکن است هنگام مواجهه با عدم قطعیت، محتوای توهمی تولید کنند. تحقیقات آینده شامل بهبود استحکام LRM هنگام رسیدگی به وظایف مبهم یا محاسباتی فشرده است.
مقاله را بررسی کنید. تمام اعتبار این تحقیق به محققان این پروژه میرسد. همچنین، با خیال راحت ما را در توییتر دنبال کنید و فراموش نکنید که به 80 هزار+ ML SubReddit ما بپیوندید.
درباره نویسنده
سجاد انصاری دانشجوی سال آخر IIT Kharagpur است. او به عنوان یک علاقهمند به فناوری، به کاربردهای عملی هوش مصنوعی با تمرکز بر درک تأثیر فناوریهای هوش مصنوعی و پیامدهای واقعی آنها میپردازد. هدف او بیان مفاهیم پیچیده هوش مصنوعی به روشی واضح و در دسترس است.