
لایههای نرمالسازی به اجزای اساسی شبکههای عصبی مدرن تبدیل شدهاند و با تثبیت جریان گرادیان، کاهش حساسیت به مقداردهی اولیه وزن و هموارسازی سطح زیان، به طور قابل توجهی بهینهسازی را بهبود میبخشند. از زمان معرفی نرمالسازی دستهای در سال ۲۰۱۵، تکنیکهای مختلف نرمالسازی برای معماریهای مختلف توسعه یافتهاند که نرمالسازی لایه (LN) به ویژه در مدلهای ترانسفورمر غالب شده است. استفاده گسترده از آنها تا حد زیادی به توانایی آنها در تسریع همگرایی و افزایش عملکرد مدل نسبت داده میشود، به ویژه با عمیقتر و پیچیدهتر شدن شبکهها. علیرغم نوآوریهای معماری مداوم که سایر اجزای اصلی مانند لایههای توجه یا کانولوشن را جایگزین میکنند، لایههای نرمالسازی جزء لاینفک اکثر طرحها باقی میمانند و بر ضرورت درک شده آنها در یادگیری عمیق تأکید میکنند.
در حالی که لایههای نرمالسازی مفید بودهاند، محققان همچنین روشهایی را برای آموزش شبکههای عمیق بدون آنها بررسی کردهاند. مطالعات، استراتژیهای جایگزین مقداردهی اولیه وزن، تکنیکهای نرمالسازی وزن و برش گرادیان تطبیقی را برای حفظ ثبات در مدلهایی مانند ResNet پیشنهاد کردهاند. در ترانسفورمرها، تلاشهای اخیر به بررسی اصلاحاتی پرداختهاند که وابستگی به نرمالسازی را کاهش میدهند، مانند بازسازی بلوکهای ترانسفورمر یا حذف تدریجی لایههای LN از طریق تنظیم دقیق. این رویکردها نشان میدهند که در حالی که لایههای نرمالسازی مزایای بهینهسازی را ارائه میدهند، اما کاملاً ضروری نیستند و تکنیکهای آموزشی جایگزین میتوانند به همگرایی پایدار با عملکرد قابل مقایسه دست یابند.
محققان FAIR، Meta، NYU، MIT و Princeton، تانژانت هذلولی پویا (Dynamic Tanh - DyT) را به عنوان جایگزینی ساده اما مؤثر برای لایههای نرمالسازی در ترانسفورمرها پیشنهاد میکنند. DyT به صورت یک تابع جزء به جزء عمل میکند، (DyT(x) = tanh(alpha x که در آن (alpha) یک پارامتر قابل یادگیری است که فعالسازیها را مقیاسبندی میکند و در عین حال مقادیر شدید را محدود میکند. برخلاف نرمالسازی لایه، DyT نیاز به آمار فعالسازی را از بین میبرد و محاسبات را ساده میکند. ارزیابیهای تجربی نشان میدهد که جایگزینی لایههای نرمالسازی با DyT، عملکرد را در وظایف مختلف بدون تنظیم گسترده ابرپارامترها حفظ یا بهبود میبخشد. علاوه بر این، DyT آموزش و کارایی استنتاج را افزایش میدهد و این فرضیه را به چالش میکشد که نرمالسازی برای شبکههای عمیق مدرن ضروری است.
محققان لایههای نرمالسازی را در ترانسفورمرها با استفاده از مدلهایی مانند ViT-B، wav2vec 2.0 و DiT-XL تجزیه و تحلیل کردند. آنها دریافتند که LN اغلب یک نگاشت ورودی-خروجی S شکل و شبیه به تانژانت هذلولی (tanh) را نشان میدهد که در درجه اول برای اکثر مقادیر خطی است اما فعالسازیهای شدید را سرکوب میکند. با الهام از این موضوع، آنها تانژانت هذلولی پویا (DyT) را به عنوان جایگزینی برای LN پیشنهاد میکنند. DyT به صورت DyT(x) = gamma *tanh(alpha x) + beta) تعریف میشود، که در آن آلفا، گاما و بتا پارامترهای قابل یادگیری هستند، DyT اثرات LN را بدون محاسبه آمار فعالسازی حفظ میکند. نتایج تجربی نشان میدهد که DyT به طور یکپارچه در معماریهای موجود ادغام میشود، ثبات را حفظ میکند و نیاز به تنظیم ابرپارامترها را کاهش میدهد.
برای ارزیابی اثربخشی DyT، آزمایشهایی در سراسر معماریها و وظایف مختلف با جایگزینی LN یا RMSNorm با DyT انجام شد در حالی که ابرپارامترها بدون تغییر باقی ماندند. در وظایف بینایی تحت نظارت، DyT کمی بهتر از LN در طبقهبندی ImageNet-1K عمل کرد. برای یادگیری خود نظارتی، مدلهای انتشار، مدلهای زبان، پردازش گفتار و مدلسازی توالی DNA، DyT به عملکردی قابل مقایسه با روشهای نرمالسازی موجود دست یافت. تستهای کارایی روی LLaMA-7B نشان داد که DyT زمان محاسبات را کاهش میدهد. مطالعات حذف، اهمیت تابع تانژانت هذلولی و پارامتر قابل یادگیری a را برجسته کرد، که با انحراف معیار فعالسازی مرتبط است و به عنوان یک مکانیسم نرمالسازی ضمنی عمل میکند. DyT عملکرد رقابتی با کارایی بهبود یافته را نشان داد.
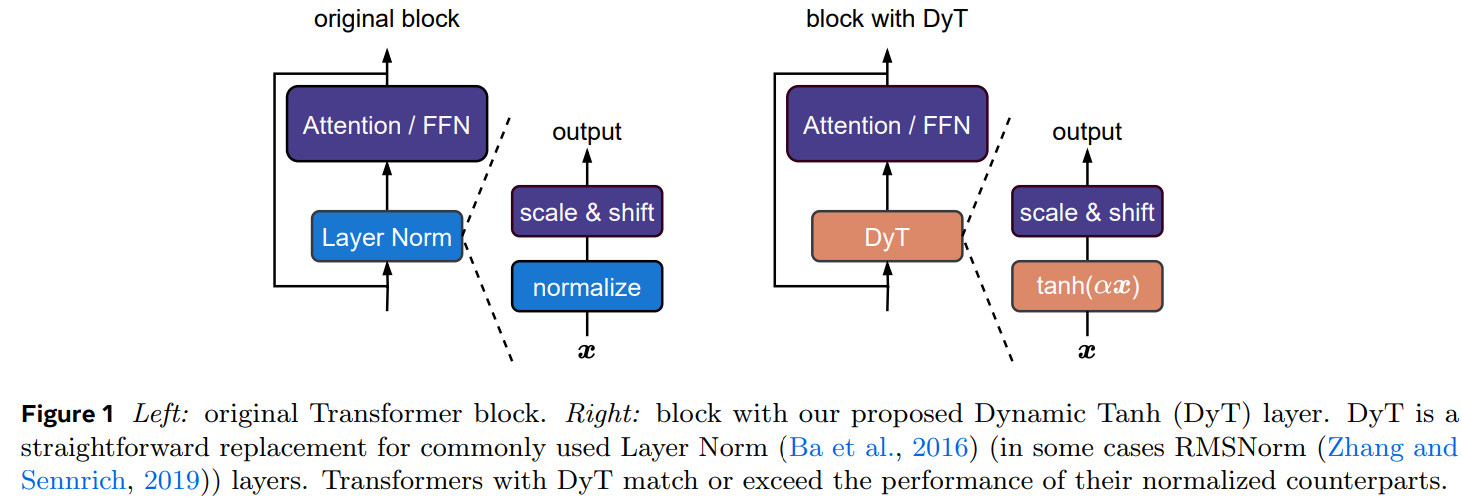
در نتیجه، این مطالعه نشان میدهد که شبکههای عصبی مدرن، به ویژه ترانسفورمرها، میتوانند به طور موثر بدون لایههای نرمالسازی آموزش داده شوند. DyT پیشنهادی، نرمالسازی سنتی را با استفاده از یک عامل مقیاسبندی قابل یادگیری آلفا و یک تابع تانژانت هذلولی S شکل برای تنظیم مقادیر فعالسازی جایگزین میکند. علیرغم سادگی آن، DyT رفتار نرمالسازی را تکرار میکند و به عملکردی قابل مقایسه یا برتر در وظایف مختلف، از جمله تشخیص، تولید و یادگیری خود نظارتی دست مییابد. نتایج این فرضیه را به چالش میکشد که لایههای نرمالسازی ضروری هستند و بینشهای جدیدی را در مورد عملکرد آنها ارائه میدهند. DyT یک جایگزین سبک وزن ارائه میدهد که آموزش را ساده میکند و در عین حال عملکرد را حفظ یا بهبود میبخشد، اغلب بدون نیاز به تنظیمات ابرپارامتر.
مقاله و صفحه پروژه را بررسی کنید. تمام اعتبار این تحقیق به محققان این پروژه میرسد. همچنین، میتوانید ما را در توییتر دنبال کنید و فراموش نکنید که به سابردیت ۸۰k+ ML ما بپیوندید.