یک مدل زبانی متنباز جدید به عملکردی قابل مقایسه با سیستمهای تجاری پیشرو دست یافته است در حالی که شفافیت کامل را حفظ میکند.
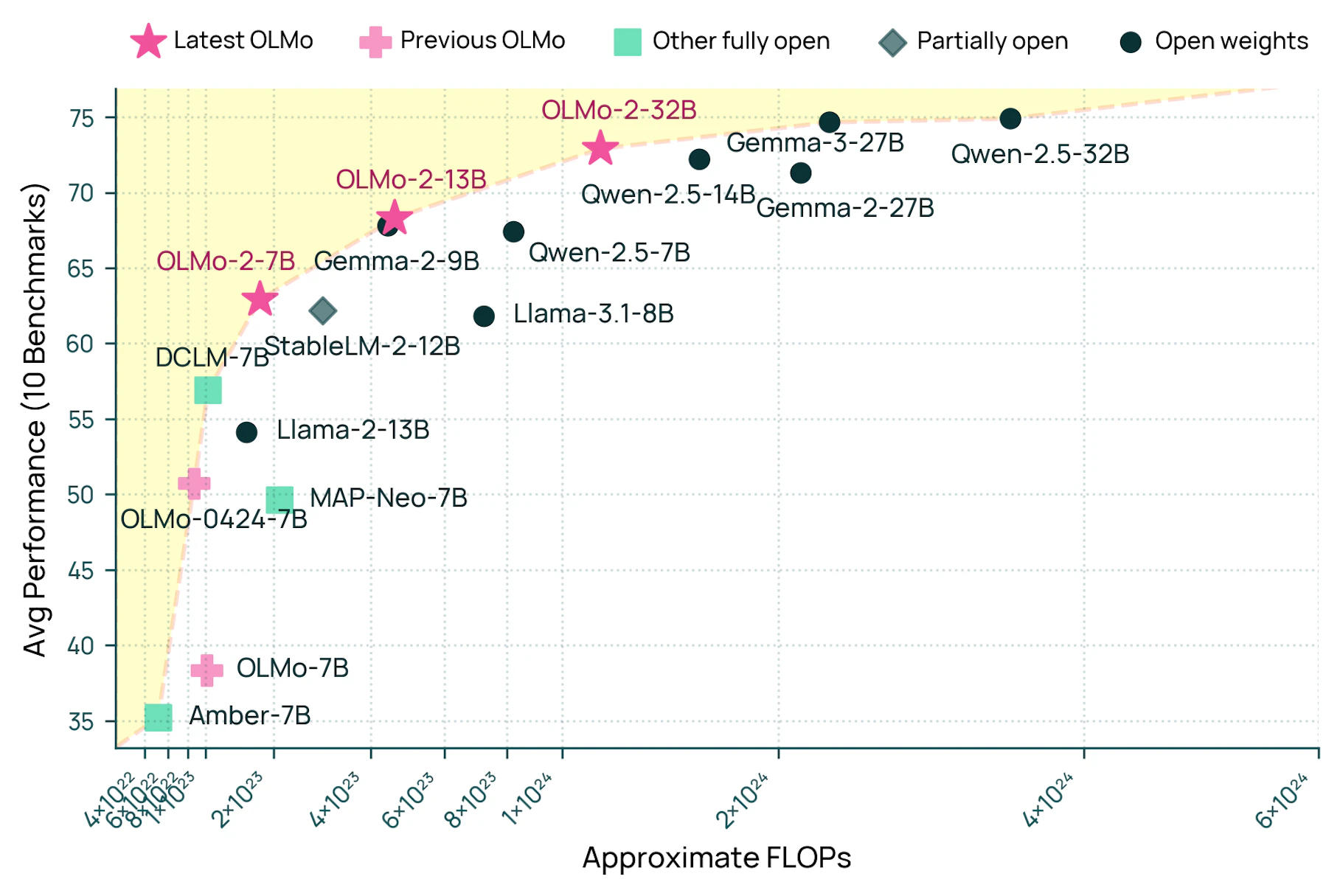
مؤسسه هوش مصنوعی آلن (Ai2) اعلام کرد که مدل OLMo 2 32B آن از GPT-3.5-Turbo و GPT-4o mini پیشی میگیرد در حالی که کد، دادههای آموزشی و جزئیات فنی خود را به صورت عمومی در دسترس قرار میدهد.
این مدل به دلیل کارایی خود متمایز است و تنها یک سوم منابع محاسباتی مورد نیاز مدلهای مشابه مانند Qwen2.5-32B را مصرف میکند. این امر آن را به ویژه برای محققان و توسعهدهندگانی که با منابع محدود کار میکنند، در دسترس قرار میدهد.
ایجاد یک سیستم هوش مصنوعی شفاف
تیم توسعه از یک رویکرد آموزشی سه مرحلهای استفاده کرد. این مدل ابتدا الگوهای اساسی زبان را از ۳.۹ تریلیون توکن آموخت، سپس اسناد با کیفیت بالا و محتوای آکادمیک را مطالعه کرد و در نهایت با استفاده از چارچوب Tulu 3.1، که تکنیکهای یادگیری نظارت شده و تقویتی را ترکیب میکند، بر پیروی از دستورالعملها مسلط شد.
برای مدیریت این فرآیند، تیم OLMo-core را ایجاد کرد، یک پلتفرم نرمافزاری جدید که به طور موثر چندین رایانه را هماهنگ میکند در حالی که پیشرفت آموزش را حفظ میکند. آموزش واقعی در Augusta AI، یک شبکه ابررایانهای از ۱۶۰ ماشین مجهز به GPUهای H100، با دستیابی به سرعت پردازش بیش از ۱۸۰۰ توکن در ثانیه برای هر GPU انجام شد.
در حالی که بسیاری از پروژههای هوش مصنوعی، مانند Llama متا، ادعای وضعیت متنباز دارند، OLMo 2 هر سه معیار اساسی را برآورده میکند: کد مدل عمومی، وزنها و دادههای آموزشی. این تیم همه چیز را منتشر کرده است، از جمله مجموعه داده آموزشی Dolmino، که امکان بازتولید و تجزیه و تحلیل کامل را فراهم میکند.
Nathan Lambert از Ai2 میگوید: «با کمی پیشرفت بیشتر، هر کسی میتواند آموزش اولیه، آموزش میانی، آموزش پس از آن را انجام دهد، هر آنچه که برای به دست آوردن یک مدل کلاس GPT 4 در کلاس خود نیاز دارد. این یک تغییر اساسی در نحوه رشد هوش مصنوعی متنباز به برنامههای کاربردی واقعی است.»
این بر اساس کار قبلی آنها با Dolma در سال ۲۰۲۳ است، که به ایجاد پایه و اساس برای آموزش هوش مصنوعی متنباز کمک کرد. این تیم همچنین نقاط بازرسی مختلفی را آپلود کرده است، یعنی نسخههای مدل زبانی در زمانهای مختلف در طول آموزش. مقالهای که در دسامبر به همراه نسخههای 7B و 13B از OLMo 2 منتشر شد، اطلاعات فنی بیشتری را ارائه میدهد.
به گفته تحلیل Lambert، شکاف بین سیستمهای هوش مصنوعی متنباز و متنبسته به حدود ۱۸ ماه کاهش یافته است. در حالی که OLMo 2 32B در آموزش اولیه با Gemma 3 27B گوگل مطابقت دارد، Gemma 3 پس از تنظیم دقیق، عملکرد قویتری نشان میدهد، که نشان میدهد فضای زیادی برای بهبود در روشهای آموزش پس از منبع باز وجود دارد.
این تیم قصد دارد استدلال منطقی مدل را افزایش دهد و توانایی آن را برای مدیریت متون طولانیتر گسترش دهد. کاربران میتوانند OLMo 2 32B را از طریق Chatbot Playground Ai2 آزمایش کنند.
در حالی که Ai2 همچنین مدل بزرگتر Tülu-3-405B را در ژانویه منتشر کرد که از GPT-3.5 و GPT-4o mini پیشی میگیرد، Lambert توضیح میدهد که این مدل به طور کامل متنباز نیست زیرا آزمایشگاه در آموزش اولیه آن دخالت نداشته است.
خلاصه
- محققان موسسه هوش مصنوعی آلن (Ai2) OLMo 2 32B را توسعه دادهاند، یک مدل زبانی متنباز جدید که با عملکرد مدلهای تجاری مانند GPT-3.5-Turbo مطابقت دارد.
- این مدل با استفاده از تنها یک سوم منابع محاسباتی مورد نیاز مدلهای قابل مقایسه، با استفاده از یک فرآیند سه مرحلهای آموزش داده شد: آموزش زبان پایه، اصلاح با اسناد با کیفیت بالا و آموزش دستورالعمل.
- Ai2 با انتشار کد منبع، نقاط بازرسی آموزشی، مجموعه داده "Dolmino" و تمام جزئیات فنی به صورت عمومی، کل فرآیند توسعه را شفاف کرده است.
منابع: Ai2, Interconnects