
پیشرفتها در مدلهای زبانی بزرگ چندوجهی، توانایی هوش مصنوعی را در تفسیر و استدلال در مورد اطلاعات بصری و متنی پیچیده افزایش داده است. با وجود این بهبودها، این حوزه با چالشهای مداومی روبرو است، به ویژه در وظایف استدلال ریاضی. سیستمهای سنتی هوش مصنوعی چندوجهی، حتی آنهایی که دارای دادههای آموزشی گسترده و تعداد پارامترهای بزرگ هستند، اغلب در تفسیر دقیق و حل مسائل ریاضی شامل زمینههای بصری یا پیکربندیهای هندسی مشکل دارند. این محدودیتها نیاز فوری به مدلهای تخصصی را برجسته میکند که قادر به تجزیه و تحلیل مسائل پیچیده ریاضی چندوجهی با دقت، کارایی و پیچیدگی استدلال بیشتر باشند.
محققان دانشگاه فناوری نانیانگ (NTU) مدل MMR1-Math-v0-7B و مجموعه داده تخصصی MMR1-Math-RL-Data-v0 را برای پرداختن به چالشهای مهم فوق معرفی کردند. این مدل پیشگام به طور خاص برای استدلال ریاضی در وظایف چندوجهی طراحی شده است و کارایی قابل توجه و عملکرد پیشرفته را به نمایش میگذارد. MMR1-Math-v0-7B به دلیل توانایی خود در دستیابی به عملکرد پیشرو با استفاده از یک مجموعه داده آموزشی بسیار کم، از مدلهای چندوجهی قبلی متمایز است و در نتیجه معیارهای جدیدی را در این حوزه تعریف میکند.
این مدل با استفاده از تنها 6000 نمونه داده به دقت تنظیم شده از مجموعههای داده در دسترس عموم، تنظیم شده است. محققان از یک استراتژی انتخاب داده متعادل استفاده کردند و بر یکنواختی از نظر دشواری مسئله و تنوع استدلال ریاضی تاکید کردند. محققان NTU با فیلتر کردن سیستماتیک مسائل بیش از حد ساده، اطمینان حاصل کردند که مجموعه داده آموزشی شامل مسائلی است که به طور موثر تواناییهای استدلال مدل را به چالش میکشد و بهبود میبخشد.
معماری MMR1-Math-v0-7B بر اساس ستون فقرات چندوجهی Qwen2.5-VL ساخته شده است و با استفاده از یک روش آموزشی جدید به نام بهینهسازی سیاست مبتنی بر پاداش تعمیمیافته (GRPO) بیشتر اصلاح شده است. استفاده از GRPO به محققان اجازه داد تا به طور موثر مدل را در یک تنظیم یادگیری تقویتی در طول 15 دوره آموزش دهند، که تقریباً شش ساعت بر روی 64 واحد پردازش گرافیکی NVIDIA H100 طول کشید. دوره آموزش نسبتاً کوتاه و استفاده کارآمد از منابع محاسباتی، ظرفیت چشمگیر مدل را برای جذب سریع دانش و تعمیم نشان میدهد.
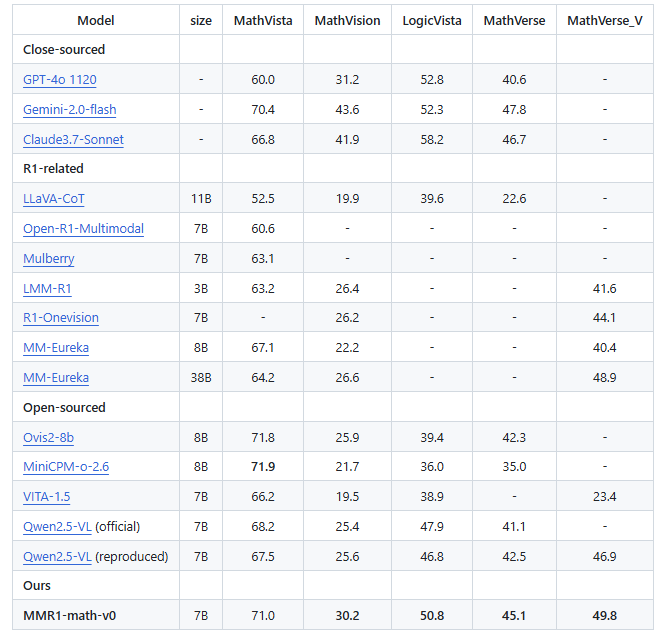
MMR1-Math-v0-7B با استفاده از VLMEvalKit استاندارد شده، در برابر معیارهای established ارزیابی شد و بر وظایف استدلال ریاضی چندوجهی تمرکز داشت. این معیارها شامل MathVista_MINI، MathVision، LogicVista و MathVerse_MINI بودند. MMR1-Math-v0-7B نتایج پیشگامانهای را ارائه کرد و از مدلهای 7B منبع باز موجود پیشی گرفت و حتی با مدلهای اختصاصی با پارامترهای بسیار بزرگتر رقابت کرد.
چندین نکته کلیدی از این انتشار عبارتند از:
- مدل MMR1-Math-v0-7B که توسط محققان NTU توسعه یافته است، یک معیار جدید پیشرفته برای استدلال ریاضی چندوجهی در میان مدلهای پارامتر 7B منبع باز تعیین میکند.
- با استفاده از یک مجموعه داده آموزشی فوقالعاده کوچک متشکل از تنها 6000 نمونه چندوجهی به دقت تنظیم شده، به عملکرد برتر دست مییابد.
- پس از 6 ساعت آموزش بر روی 64 واحد پردازش گرافیکی NVIDIA H100، یک روش یادگیری تقویتی کارآمد (GRPO) به طور قوی عمل میکند.
- مجموعه داده مکمل MMR1-Math-RL-Data-v0، شامل 5780 مسئله ریاضی چندوجهی، محتوای متنوع، متعادل و چالشبرانگیز را برای آموزش مدل تضمین میکند.
- از سایر مدلهای چندوجهی برجسته در سراسر معیارهای استاندارد بهتر عمل میکند و کارایی، تعمیم و قابلیت استدلال استثنایی را در سناریوهای پیچیده ریاضی نشان میدهد.
برای اطلاعات بیشتر به صفحه Hugging Face و صفحه GitHub مراجعه کنید. اعتبار کامل این تحقیق به محققان این پروژه میرسد. همچنین، میتوانید ما را در توییتر دنبال کنید و فراموش نکنید که به انجمن ML SubReddit با بیش از 80 هزار عضو ما بپیوندید.