
بررسی اجمالی
این مقاله شما را در ساخت یک پایپلاین پیشرفته تولید افزوده بازیابی (RAG) با استفاده از چارچوب llama-index راهنمایی
میکند.
یک سیستم تولید افزوده بازیابی (RAG) چارچوبی است که با استفاده از اطلاعات از منابع خارجی، مدلهای هوش مصنوعی مولد را دقیقتر و قابل اعتمادتر میکند. در متن این پروژه، از اسناد قانونی به عنوان پایگاه دانش خارجی استفاده خواهد شد.
در این آموزش، ما با ایجاد یک سیستم RAG اساسی شروع خواهیم کرد قبل از اینکه نشان دهیم چگونه ویژگیهای پیشرفته را در آن قرار دهیم. یکی از چالشها در ساخت چنین سیستمی، تصمیمگیری در مورد بهترین اجزا برای خط لوله است. ما تلاش خواهیم کرد با ارزیابی اجزای مهم خط لوله به این سوال پاسخ دهیم.
این مقاله به عنوان یک آموزش عملی برای پیادهسازی سیستمهای RAG، از جمله ارزیابی آنها، عمل میکند. در حالی که به جنبههای نظری عمیقاً نمیپردازد، مفاهیم استفاده شده در این مقاله را تا حد امکان به طور کامل توضیح خواهد داد.
راهاندازی
1- کد
برای دسترسی به کد این پروژه، دستور زیر را برای شبیهسازی مخزن مربوطه از GitHub اجرا کنید:
git clone [email protected]:HamzaG737/legal-code-rag.gitدر مرحله بعد، باید بستههای لازم را نصب کنید. ما از poetry به عنوان مدیر بسته خود برای مدیریت بهتر وابستگیهای پروژه استفاده کردیم. poetry را با استفاده از دستور زیر نصب کنید.
curl -sSL https://install.python-poetry.org | python3 -شما میتوانید اطلاعات بیشتری در مورد نصب poetry اینجا پیدا کنید.
سپس، در ریشه پروژه، از دستور زیر برای نصب بستههای پایتون استفاده کنید:
poetry installبرای این پروژه، داشتن یک محیط پایتون که نسخهای در محدوده 3.9 تا 3.11 را اجرا میکند، مورد نیاز است. ما اکیداً توصیه میکنیم یک محیط مجازی ایجاد کنید تا وابستگیهای بسته پروژه خود را جدا کنید و اطمینان حاصل کنید که با بستههای نصب شده به صورت سراسری در سیستم شما تضاد ندارند.
شما همچنین برای این پروژه به Docker نیاز خواهید داشت.
در نهایت، اطمینان حاصل کنید که متغیر محیطی OPENAI_API_KEY تعریف شده است زیرا ما از LLM gpt-3.5-turbo
OpenAI و جاسازی Ada در این پروژه استفاده خواهیم کرد. اگر علاقهمند به انجام آزمایش با جاسازی Mistral هستید، باید یک کلید API
از پلتفرم Mistral دریافت کنید. سپس باید متغیر محیطی مربوطه
MISTRAL_API_KEY را ایجاد کنید.
2- داده
پایگاه دانش RAG ما شامل نمونههایی از کدهای قانون فرانسه است. یک کد قانون، قطعه قانون جامعی است که برای تعیین معتبر و منطقی اصول و قوانین در یک حوزه خاص از قانون طراحی شده است.
به عنوان مثال، قانون مدنی هدفش اصلاح و تدوین قوانین فرانسه مربوط به حقوق خصوصی یا مدنی است. این شامل زمینههایی مانند مالکیت، قراردادها، حقوق خانواده و وضعیت شخصی است.
به طور کلی، یک کد مجموعهای از مقالات مرتب شده است که با فرادادههای خاصی مانند فصل، عنوان، بخش و غیره مرتبط هستند…
در حال حاضر، تقریباً 78 کد قانونی در فرانسه در حال اجرا هستند. دولت فرانسه این کدها را به صورت رایگان در وب سایتی به نام Légifrance منتشر میکند.
برای این پروژه، شما دو گزینه برای ایجاد پایگاه دانش دارید:
- بارگیری دادههای تازه از API Legifrance که دارای وضعیت داده باز است. شما میتوانید دستورالعملهای ایجاد کلیدهای API را اینجا پیدا کنید. سپس ما از کتابخانه پایتون pylegifrance برای درخواست کدهای خاص از API استفاده خواهیم کرد.
- بارگیری دادههای پردازش شده از مخزن در
./data/legifrance/ {code_name}.json.
از آنجایی که کدهای قانون اغلب تغییر میکنند، توصیه میکنیم اگر علاقهمند به دریافت آخرین نسخههای کدهای قانون هستید، دادهها را مستقیماً از API بارگیری کنید. با این حال، ایجاد کلیدهای API میتواند کمی خستهکننده باشد. اگر عجله دارید و به آخرین محتوا نیاز ندارید، میتوانید دادهها را به صورت محلی بارگیری کنید، که تنظیمات پیشفرض است.
اگر کلیدهای API را دارید و میخواهید دادهها را دوباره بارگیری کنید، هنگام ایجاد موتور پرس و جو، آرگومان reload_data
را روی True تنظیم کنید. این موتور نشان دهنده خط لوله RAG سرتاسری ما است (مفهوم موتور پرس و جو را بعداً توضیح
خواهیم داد).
3- تبدیل دادههای خام
این بخش برای خوانندگانی است که علاقهمند به دانستن چگونگی تبدیل دادههایی هستند که از API legifrance دریافت کردهایم.
در ./data_ingestion/preprocess_legifrance_data.py ما دادههای دریافتی از API را با استفاده از مراحل زیر پیش
پردازش میکنیم:
- ما محتوای یک کد معین را از API درخواست میکنیم.
- ما محتوای مقالات را به صورت بازگشتی از json پاسخ API بازیابی میکنیم.
- ما مقالات را رفع تکرار میکنیم و برخی از پاکسازیها را انجام میدهیم، مانند حذف برخی از تگهای html، حذف متن و غیره…
دادههایی که در پایان این فرآیند به دست میآوریم، فهرستی از مقالات است که در آن هر مقاله با محتوای آن، فرادادههای آن (به عنوان مثال عنوان، بخش، پاراگراف…) و شماره آن نشان داده میشود. به عنوان مثال:
{'content': "Ni le propriétaire, ni l'usufruitier, ne sont tenus de rebâtir ce qui est tombé de vétusté, ou ce qui a été détruit par cas fortuit.",
'num': '607',
'livre': 'Des biens et des différentes modifications de la propriété',
'titre': "De l'usufruit, de l'usage et de l'habitation",
'chapitre': "De l'usufruit",
'section': "Des obligations de l'usufruitier"}و در اینجا ترجمه انگلیسی آمده است:
{
"content": "Neither the owner nor the usufructuary are required to rebuild what has fallen into disrepair or what has been destroyed by an act of chance.",
"num": "607",
"book": "Of Property and the Various Modifications of Ownership",
"title": "Of Usufruct, Use and Habitation",
"chapter": "Of Usufruct",
"section": "The Obligations of the Usufructuary"
}یک مقاله به عنوان واحد اساسی داده عمل میکند و در چیزی که ما آن را node مینامیم کپسوله میشود. اطلاعات بیشتر در
مورد این موضوع در بخش بعدی.
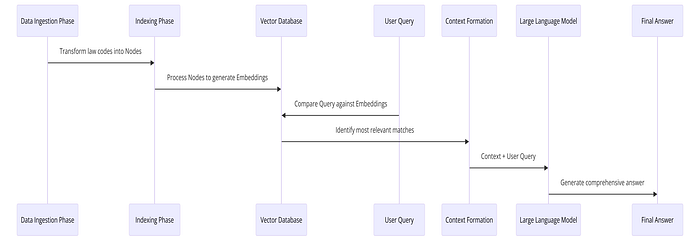
سیستم RAG پایه
یک سیستم RAG پایه حاوی چهار مرحله مهم است. ما هر یک از این مراحل را بررسی خواهیم کرد و کاربرد آنها را در پروژه خود نشان خواهیم داد.
1- دریافت داده
این مرحله شامل جمعآوری و پیش پردازش دادههای مرتبط از منابع مختلف مانند فایلهای PDF، پایگاههای داده، APIها، وبسایتها و موارد دیگر است. این مرحله ارتباط نزدیکی با دو مفهوم کلیدی دارد: اسناد و گرهها.
در اصطلاح LlamaIndex، یک Document به یک ظرف اشاره دارد که هر منبع دادهای مانند یک PDF، یک خروجی API یا
دادههای بازیابی شده از یک پایگاه داده را کپسوله میکند. از طرف دیگر، یک Node واحد اساسی داده در LlamaIndex است که
نشان دهنده یک «تکه» از یک سند منبع است. گرهها فرادادههایی را حمل میکنند که آنها را به سندی که به آن تعلق دارند و به سایر
گرهها مرتبط میکند.
در پروژه ما، یک سند متن کامل قانون مدنی و یک گره یک ماده از این قانون خواهد بود. با این حال، از آنجایی که دادهها را از قبل به صورت مقالههای مختلف از API تجزیه شده دریافت میکنیم، نیازی به تکهتکه کردن اسناد نخواهیم داشت و بنابراین از تمام خطاهای ناشی از این فرآیند جلوگیری میکنیم.