
آندری کارپاتی، پژوهشگر سابق OpenAI، آیندهای را پیشبینی میکند که در آن مدلهای زبانی بزرگ (LLM) به رابط اصلی برای محتوا تبدیل میشوند.
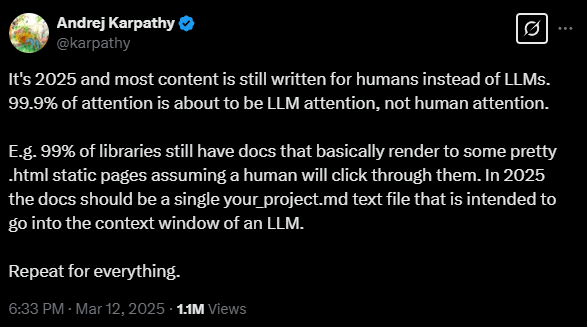
او در پستی در X (توییتر سابق) بیان میکند، در حالی که بیشتر محتوا همچنان برای انسانها نوشته خواهد شد، 99.9 درصد تلاشهای بهینهسازی بر روی قابل هضم کردن محتوا برای LLMها متمرکز خواهد شد، نه خوانندگان انسانی. این تغییر میتواند اساساً نحوه ساختاردهی مستندات و سایر محتواها را تغییر دهد.
کارپاتی به شیوههای مستندسازی فعلی به عنوان مثال اشاره میکند: "99٪ از کتابخانهها هنوز مستنداتی دارند که اساساً به صفحات استاتیک html زیبا تبدیل میشوند، با این فرض که یک انسان روی آنها کلیک میکند." او استدلال میکند که تا سال 2025، مستندات باید به عنوان یک فایل پروژه واحد وجود داشته باشند که برای پنجره زمینه یک LLM بهینه شده باشد.
حرکت به سوی استانداردهای وب سازگار با هوش مصنوعی
کارپاتی اشاره میکند در حالی که ترکیب پایگاههای کد در فایلهای واحد از نظر فنی ساده است، چالش واقعی با محتوای ذخیره شده در قالبهای انسانمحور - وبسایتها، فایلهای PDF، تصاویر، فیلمها و فایلهای صوتی - است.
این قالبهای "دوران قبل از LLM" بهینهسازی هوش مصنوعی را دشوار میکنند. به گفته کارپاتی، صنعت به استانداردهای جدیدی نیاز دارد که برای مصرف انسان و ماشین به یک اندازه خوب عمل کنند.
یک استاندارد وب پیشنهادی جدید به نام "llms.txt" با دیدگاه کارپاتی برای ساختار محتوای بهینهسازی شده با هوش مصنوعی همسو است. این مشخصات که توسط جرمی هاوارد توسعه یافته است، شبیه به index.html برای سیستمهای هوش مصنوعی عمل میکند. در حالی که index.html کاربران را به نسخه HTML یک صفحه هدایت میکند، llms.txt سیستمهای هوش مصنوعی را به یک نسخه Markdown (.md) قابل خواندن توسط ماشین هدایت میکند.
این رویکرد دوگانه به وبسایتها اجازه میدهد تا نسخههای قابل خواندن توسط انسان و بهینهسازی شده با هوش مصنوعی از محتوای خود را حفظ کنند. شرکتهایی مانند Anthropic قبلاً این استاندارد را پیادهسازی کردهاند.
شرکتهای LLM به عنوان نگهبانان جدید
پیامدهای این موضوع بسیار فراتر از تغییرات فنی است. اقتصاد محتوای دیجیتال امروزی بر اساس توجه انسان - از طریق تبلیغات و اشتراکها - اداره میشود. این صنعت اکنون با چالش بازاندیشی کامل زنجیرههای ارزش و مدلهای درآمدی خود با تغییر محتوا به سمت مصرف هوش مصنوعی روبرو است.
شرکتهای هوش مصنوعی شروع به صدور مجوز فیدهای خبری زنده کردهاند و این نیز سوالات جدی را مطرح میکند. هنگامی که شرکتهایی مانند OpenAI تصمیم میگیرند که سیستمهای هوش مصنوعی آنها چه محتوایی را ببینند، اساساً به نگهبانان قدرتمند اطلاعات تبدیل میشوند.
این تغییر تهدید میکند که نحوه کشف و مصرف محتوای آنلاین توسط همگان را تغییر دهد و سوالات جدی را در مورد اینکه چه کسی دسترسی ما به اطلاعات را کنترل میکند، مطرح میکند. با توجه به اینکه LLMها هنوز هم اغلب هنگام پردازش و بازتولید اطلاعات اشتباه میکنند، خطرات حتی بیشتر است.