
وظایف دستکاری رباتیک با افق طولانی، به دلیل پاداشهای پراکنده، فضاهای حالت-کنش با ابعاد بالا و چالش طراحی توابع پاداش مفید، یک چالش جدی برای یادگیری تقویتی هستند. یادگیری تقویتی مرسوم برای مدیریت اکتشاف کارآمد مناسب نیست، زیرا عدم وجود بازخورد مانع از یادگیری سیاستهای بهینه میشود. این مسئله در وظایف کنترل رباتیک استدلال چند مرحلهای اهمیت دارد، جایی که دستیابی به اهداف فرعی متوالی برای موفقیت کلی ضروری است. ساختارهای پاداش ضعیف طراحی شده میتوانند باعث شوند که عوامل در بهینههای محلی گیر کنند یا از میانبرهای جعلی سوء استفاده کنند، که منجر به فرآیندهای یادگیری غیربهینه میشود. علاوه بر این، بیشتر روشهای موجود دارای پیچیدگی نمونه بالایی هستند و برای تعمیم به وظایف دستکاری متنوع، به حجم زیادی از دادههای آموزشی نیاز دارند. چنین محدودیتهایی یادگیری تقویتی را برای وظایف دنیای واقعی غیرممکن میکند، جایی که کارایی داده و سیگنالهای یادگیری ساختاریافته برای موفقیت کلیدی هستند.

تحقیقات قبلی که به این مسائل پرداختهاند، یادگیری تقویتی مبتنی بر مدل، یادگیری مبتنی بر نمایش و یادگیری تقویتی معکوس را بررسی کردهاند. روشهای مبتنی بر مدل، از جمله TD-MPC2، با بهرهگیری از مدلهای دنیای پیشبینیکننده، کارایی نمونه را بهبود میبخشند، اما برای بهینهسازی سیاستها به میزان زیادی اکتشاف نیاز دارند. روشهای مبتنی بر نمایش، از جمله MoDem و CoDER، با بهرهگیری از مسیرهای متخصص، مشکلات اکتشاف را کاهش میدهند، اما به دلیل نیاز به مجموعههای داده بزرگ، مقیاسبندی خوبی برای وظایف با ابعاد بالا و افق طولانی ندارند. روشهای یادگیری تقویتی معکوس تلاش میکنند تا توابع پاداش را از نمایشها یاد بگیرند، اما فاقد توانایی تعمیم خوب و پیچیدگی محاسباتی هستند. علاوه بر این، بیشتر رویکردها در این زمینه از ساختار ذاتی وظایف چند مرحلهای استفاده نمیکنند و از این رو از امکان تجزیه اهداف پیچیده به اهداف فرعی قابل مدیریتتر بهره نمیبرند.
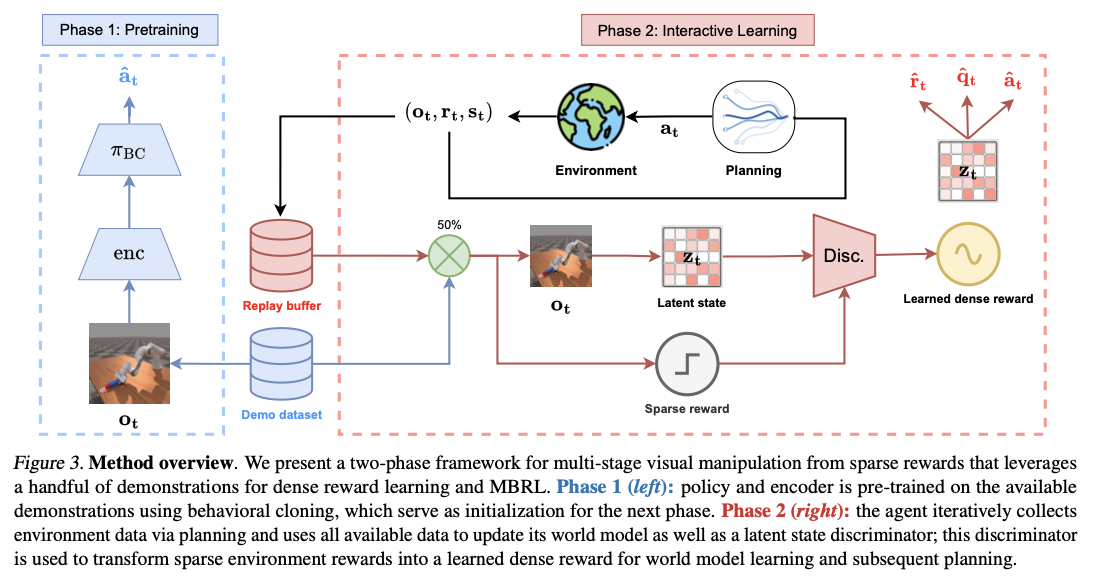
برای غلبه بر این چالشها، محققان یادگیری پاداش، سیاست و مدل جهانی تقویتشده با نمایش (DEMO3) را معرفی کردهاند، یک چارچوب یادگیری تقویتی که دستیابی به پاداش ساختاریافته، بهینهسازی سیاست و تصمیمگیری مبتنی بر مدل را یکپارچه میکند. این چارچوب سه نوآوری اصلی را معرفی میکند: تبدیل شاخصهای مرحله پراکنده به پاداشهای پیوسته و ساختاریافته که بازخورد مطمئنتری را ارائه میدهند؛ یک برنامه آموزشی دو فازی که در ابتدا از شبیهسازی رفتاری و به دنبال آن یک فرآیند یادگیری تقویتی تعاملی استفاده میکند؛ و یکپارچهسازی یادگیری مدل جهانی آنلاین، که امکان انطباق پویای جریمه در طول آموزش را فراهم میکند. برخلاف رویکردهای فعلی، این روش امکان دستیابی به پاداش ساختاریافته در زمان واقعی را از طریق متمایزکنندههای خاص مرحلهای فراهم میکند که احتمال پیشرفت به سمت اهداف فرعی را ارزیابی میکنند. در نتیجه، این چارچوب بر دستیابی به اهداف وظیفه تمرکز دارد تا تقلید نمایش، که به طور قابل توجهی کارایی نمونه و تعمیم در وظایف دستکاری رباتیک را بهبود میبخشد.
DEMO3 از پایه رویکرد TD-MPC2 ساخته شده است، که یک مدل جهانی فضای نهفته را برای افزایش مراحل برنامهریزی و کنترل یاد میگیرد. این استراتژی مبتنی بر متمایزکنندههای خاص مرحلهای متعددی است که هر کدام یاد میگیرند شانس انتقال موفقیتآمیز به مرحله وظیفه بعدی را پیشبینی کنند. این متمایزکنندهها با استفاده از معیار تلفات آنتروپی متقابل باینری تنظیم دقیق میشوند و به شکلدهی پاداش آنلاین کمک میکنند و سیگنالهای یادگیری غنیتری را در مقایسه با پاداشهای متعارف پراکنده تولید میکنند. آموزش از یک فرآیند سیستماتیک دو فازی پیروی میکند. ابتدا، در مرحله پیشآموزش، یک سیاست و یک رمزگذار با استفاده از شبیهسازی رفتاری از یک مجموعه جزئی از نمایشهای متخصص آموخته میشوند. ثانیاً، عاملی که در فرآیندهای یادگیری تقویتی مداوم شرکت میکند، یاد میگیرد که سیاست را از طریق فرآیند تعاملات محیطی تنظیم و اصلاح کند در حالی که به پاداشهای متراکم مشتق شده وابسته است. یک فرآیند بازپخت معرفی میشود تا کارایی عملیات از طریق انتقال تدریجی وابستگی از شبیهسازی رفتاری به یادگیری مستقل بهبود یابد. این انتقال هموار، انتقال پیشرونده رفتار از تقلید ناشی از نمایش به بهبود سیاست را به طور مستقل امکانپذیر میکند. این رویکرد بر روی شانزده وظیفه دستکاری رباتیک دشوار، شامل Meta-World، Robosuite و ManiSkill3 آزمایش شده است و در مقایسه با جایگزینهای پیشرفته موجود، پیشرفتهای قابل توجهی در کارایی یادگیری و همچنین استحکام به دست میآورد.
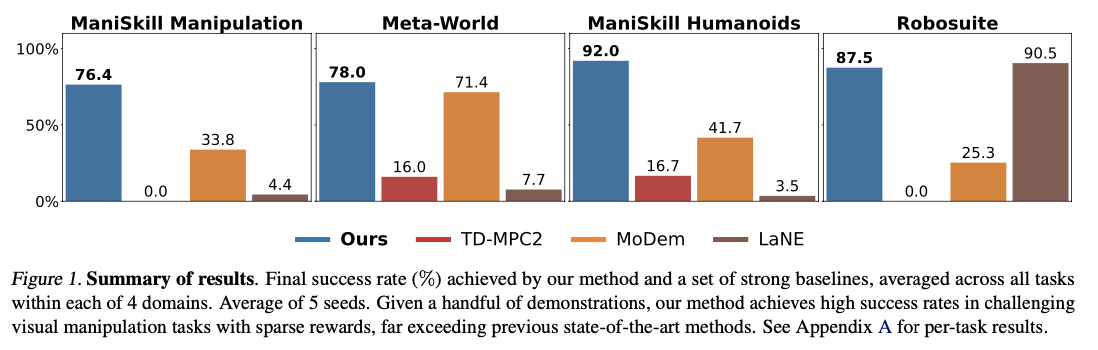
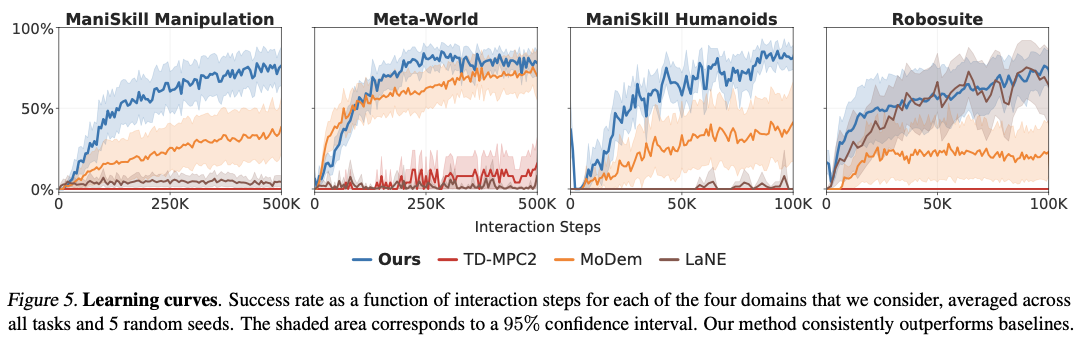
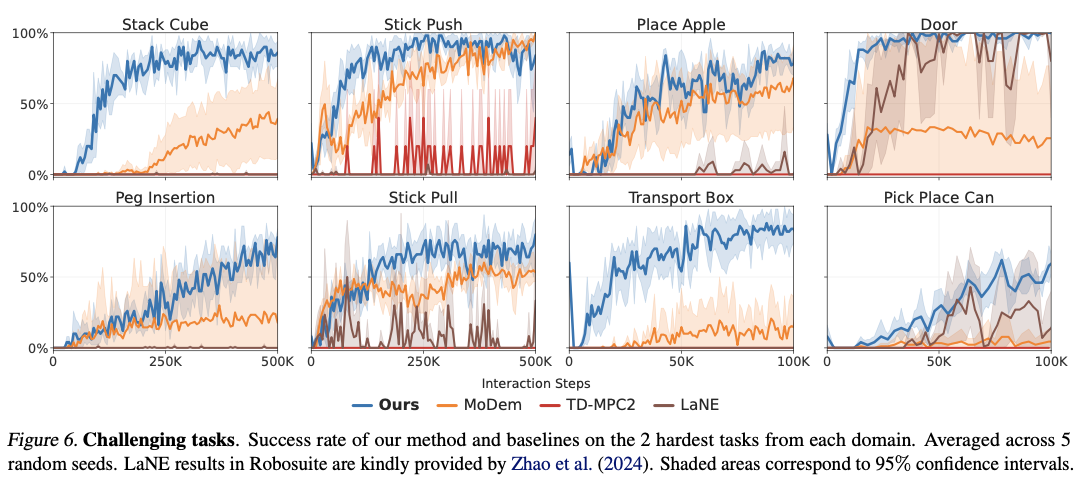
DEMO3 با کسب پیشرفتهای قابل توجه در کارایی نمونه، زمان یادگیری و نرخ موفقیت کلی تکمیل وظیفه، از الگوریتمهای یادگیری تقویتی پیشرفته بسیار بهتر عمل میکند. این روش به طور متوسط 40٪ بهبود در کارایی داده نسبت به روشهای رقیب ثبت میکند، با 70٪ بهبود گزارش شده برای چالشهای بسیار دشوار و با افق طولانی. این سیستم همیشه با تعداد کمی به اندازه پنج نمایش، نرخ موفقیت بالایی را گزارش میکند، در مقایسه با روشهای رقیب که برای دستیابی به موفقیت قابل مقایسه به مجموعههای داده بسیار بزرگتری نیاز دارند. با توانایی پردازش مناسب نمونههای پاداش پراکنده چند مرحلهای، این سیستم از وظایف دستکاری رباتیک دقیق مانند قرار دادن میخ و چیدن مکعب با نرخ موفقیت بهبود یافته در بودجههای تعاملی محدود بهتر عمل میکند. هزینههای محاسباتی نیز قابل مقایسه است و به طور متوسط حدود 5.19 ساعت برای هر 100000 مرحله تعامل است، از این رو کارآمدتر از مدلهای یادگیری تقویتی رقیب است در حالی که نتایج برتری در یادگیری مهارتهای رباتیک پیچیده به دست میآورد.
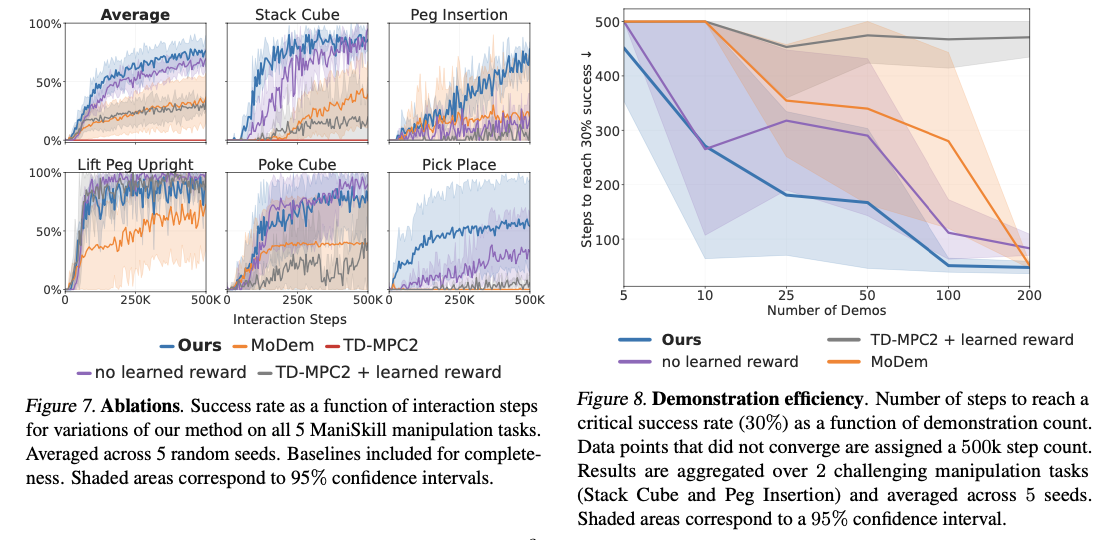
DEMO3 یک پیشرفت قابل توجه در یادگیری تقویتی است که برای کنترل رباتیک طراحی شده است و در رسیدگی به چالشهای مقابله با وظایف با افق طولانی با پاداشهای پراکنده موثر است. این چارچوب با استفاده از یادگیری پاداش متراکم آنلاین، بهینهسازی سیاست ساختاریافته و تصمیمگیری مبتنی بر مدل، میتواند به عملکرد و کارایی بالایی دست یابد. گنجاندن یک روش آموزشی دو فازی و انطباق پاداش پویا به دستیابی به پیشرفتهای کارایی داده تماشایی کمک میکند و نرخ موفقیت در مقایسه با روشهای موجود در انواع وظایف دستکاری 40-70٪ بالاتر است. با بهبود شکلدهی پاداش، بهینهسازی یادگیری سیاست و کاهش وابستگی به مجموعههای داده نمایش بزرگ، این روش پایهای برای روشهای یادگیری رباتیک کارآمدتر و مقیاسپذیرتر فراهم میکند. تحقیقات آینده میتواند به سمت رویکردهای نمونهبرداری نمایش پیشرفتهتر و تکنیکهای شکلدهی پاداش تطبیقی برای افزایش بیشتر کارایی داده و تسریع یادگیری تقویتی در وظایف رباتیک دنیای واقعی هدایت شود.
مقاله و صفحه GitHub را بررسی کنید. تمام اعتبار این تحقیق به محققان این پروژه میرسد. همچنین، در توییتر ما را دنبال کنید و فراموش نکنید که به SubReddit 80k+ ML ما بپیوندید.