به روز رسانی ۱۴ مارس ۲۰۲۵:
شرکت هوش مصنوعی Sesame مدل پایه خود CSM-1B را به عنوان متن باز منتشر کرده است. کد اکنون در Github در دسترس است.
مدل یک میلیارد پارامتری تحت مجوز Apache 2.0 عمل می کند و استفاده تجاری گسترده را با حداقل محدودیت ها امکان پذیر می کند. هر کسی می تواند قابلیت های تولید صدا را مستقیماً آزمایش کند. یک نسخه تنظیم شده از CSM-1B همچنین سیستم صدای هوش مصنوعی مایا را هدایت می کند (به زیر مراجعه کنید).
رویکرد ایمنی Sesame شامل دستورالعمل هایی است که از توسعه دهندگان و کاربران می خواهد از شبیه سازی صدای غیرمجاز، ایجاد محتوای گمراه کننده یا سایر فعالیت های "مضر" خودداری کنند. همین. این مدل می تواند صداها را تنها با یک دقیقه صوتی منبع شبیه سازی کند، که می تواند اشکال مختلف کلاهبرداری مبتنی بر صدا را فعال کند.
این انتشار متن باز نمونه دیگری از این است که چگونه شرکت های هوش مصنوعی اختصاصی برای حفظ مزایای رقابتی تلاش می کنند و پیامدهای قابل توجهی برای ایمنی هوش مصنوعی دارد. در حالی که OpenAI قبلاً به دلیل نگرانی های ایمنی تصمیم گرفت فناوری مشابهی را منتشر نکند، سرعت سریع توسعه متن باز، چنین اقدامات محافظتی را تا حد زیادی بی اثر کرده است.
مقاله اصلی از ۶ مارس ۲۰۲۵:
Sesame AI دستیار صوتی چشمگیر را به نمایش می گذارد، برنامه های متن باز دارد
Sesame AI، یک استارت آپ مستقر در کالیفرنیا، با گنجاندن عمدی نقصها در خروجی گفتار خود، رویکردی غیرمتعارف را در هوش مصنوعی صدا در پیش گرفته است. مدل جدید آنها نشان دهنده یک گام اولیه به سوی گفتگوهای معتبرتر و چیزی است که آنها آن را "حضور صوتی" در سیستم های هوش مصنوعی می نامند.
بر اساس آزمایشهای اولیه، چشمگیرترین ویژگیهای Sesame عناصر ظریفی مانند مکثهای کوچک، تغییرات تاکید و خنده در طول مکالمات است. در یکی از تعاملات، آواتار Sesame، مایا، در زمان واقعی به خنده ناگهانی کاربر پاسخ داد و آگاهی عاطفی را نشان داد.
این سیستم عمداً رفتارهای انسانی مانند اصلاحات خود در اواسط جمله، عذرخواهی برای قطع کردن و کلمات پرکننده را در خود جای میدهد. Techradar به طور خاص از این نقصهای عمدی تمجید کرد و اشاره کرد که چگونه با لحن شرکتی صیقلی ChatGPT یا Gemini متفاوت است.
در سناریوهای شبیه سازی شده، مانند بحث در مورد استرس کاری یا برنامه ریزی مهمانی، سیستم به جای تکیه بر عبارات کلی، پاسخ ها و سوالات متناسب با زمینه ارائه می دهد.
Sesame AI از نشانه های معنایی و صوتی استفاده می کند
در حالی که هنوز مقاله رسمی منتشر نشده است، پست وبلاگ Sesame بینش هایی را در مورد معماری آنها ارائه می دهد. CSM آنها از یک ساختار ترانسفورماتور دو قسمتی استفاده می کند، که یک ترانسفورماتور ستون فقرات (1-8 میلیارد پارامتر) را برای پردازش اساسی با یک رمزگشای کوچکتر (100-300 میلیون پارامتر) برای تولید صدا ترکیب می کند.
این سیستم گفتار را با استفاده از نشانه های معنایی برای خواص زبانی و آوایی، همراه با نشانه های صوتی برای ویژگی های صوتی مانند زیر و بم و تاکید پردازش می کند. برای بهینه سازی آموزش، رمزگشای صدا فقط بر روی یک شانزدهم فریم های صوتی آموزش می بیند، در حالی که پردازش معنایی از مجموعه داده کامل استفاده می کند.
این مدل بر روی یک میلیون ساعت داده صوتی انگلیسی در پنج دوره آموزش دید. این می تواند توالی هایی تا 2048 نشانه (حدود دو دقیقه صدا) را در یک معماری end-to-end پردازش کند. این رویکرد از سیستمهای سنتی متن به گفتار از طریق پردازش یکپارچه متن و صدا متفاوت است.
در حالی که به طور مستقیم در پست وبلاگ ذکر نشده است، صدای نمایشی نشان می دهد که از نسخه 27 میلیارد پارامتری LLM متن باز Google به نام Gemma استفاده می کند.
آزمایشات عملکرد نزدیک به انسان را نشان می دهد
در آزمایشهای کور با Sesame، شرکتکنندگان نتوانستند در طول قطعههای کوتاه مکالمه بین CSM و انسانهای واقعی تمایز قائل شوند. با این حال، گفتگوهای طولانیتر هنوز محدودیتهایی مانند مکثهای غیرطبیعی گاه به گاه و مصنوعات صوتی را نشان میدهند.
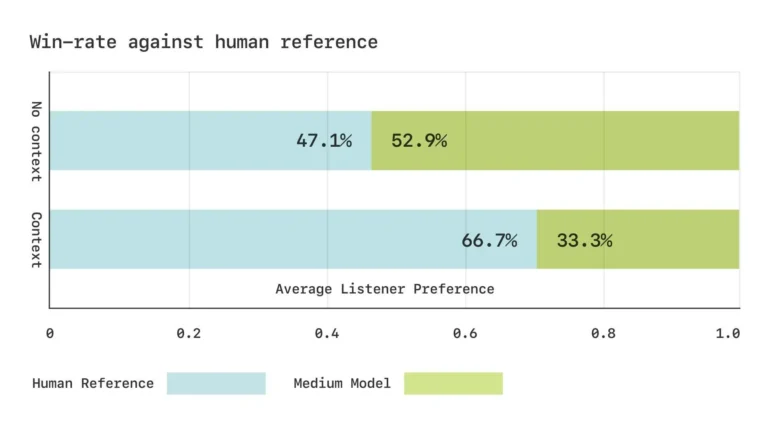
Sesame معیارهای آوایی سفارشی را برای اندازه گیری عملکرد مدل توسعه داد. در تستهای شنیداری، شرکتکنندگان گفتار تولید شده را معادل ضبطهای واقعی ارزیابی کردند، زمانی که بدون زمینه شنیده میشد، اگرچه هنوز در صورت ارائه زمینه، نسخه اصلی را ترجیح میدادند.
تحولات آینده و برنامه های متن باز
Sesame قصد دارد اجزای کلیدی تحقیقات خود را به عنوان منبع باز تحت مجوز Apache 2.0 منتشر کند. در ماههای آینده، آنها قصد دارند هم اندازه مدل و هم دامنه آموزشی را افزایش دهند و قصد دارند به بیش از 20 زبان گسترش یابند.
این شرکت به ویژه بر ادغام مدل های زبان از پیش آموزش دیده و توسعه سیستم های کاملاً دوبلکس که می توانند پویایی مکالمه مانند انتقال بلندگو، مکث ها و سرعت را مستقیماً از داده ها بیاموزند، تمرکز دارد. این توسعه مستلزم تغییرات اساسی در کل خط لوله پردازش، از تنظیم داده ها تا روش های پس از آموزش است.
توسعه دهندگان خاطرنشان می کنند: "ایجاد یک همراه دیجیتالی با حضور صوتی آسان نیست، اما ما در چندین جبهه، از جمله شخصیت، حافظه، بیان و تناسب، پیشرفت ثابتی داریم."
Sesame AI که توسط برندان ایریب، مدیر ارشد فناوری سابق Oculus و تیمش تأسیس شده است، بودجه قابل توجهی از سری A را به رهبری Andreessen Horowitz تامین کرد. یک نسخه آزمایشی در دسترس است.
تأثیر صداهای طبیعی هوش مصنوعی بر پذیرش دستیار با هیجان پیرامون حالت صدای پیشرفته ChatGPT نشان داده شد. دستیارهای صوتی که توسط LLM ها پشتیبانی می شوند، احتمالاً به طور فزاینده ای رایج می شوند، همانطور که انتشار Alexa+ توسط آمازون نشان می دهد.
خلاصه
- استارت آپ کالیفرنیایی Sesame AI در حال توسعه یک مدل گفتاری است که از نقص های عمدی مانند مکث های کوچک، آهنگ صدا و خنده برای ایجاد گفتگوی معتبرتر استفاده می کند.
- این سیستم مبتنی بر یک معماری ترانسفورماتور دو قسمتی با نشانه های معنایی و صوتی است. در آزمایش های کور، افراد مورد آزمایش نتوانستند تفاوت بین مدل هوش مصنوعی و افراد واقعی را در مکالمات کوتاه تشخیص دهند.
- Sesame قصد دارد اجزای کلیدی تحقیقات خود را به عنوان منبع باز در دسترس قرار دهد و مدل را از نظر اندازه، دامنه آموزشی و پشتیبانی زبان گسترش دهد.