
گوگل قابلیتهای تولید تصویر بومی را در مدل زبانی جمینی 2.0 فلش (Gemini 2.0 Flash) خود برای توسعهدهندگان فعال کرده است. براساس یک پست وبلاگی این شرکت، توسعهدهندگان اکنون میتوانند این ویژگی را از طریق Google AI Studio و Gemini API در تمام مناطق پشتیبانیشده آزمایش کنند. فرآیند ادغام به حداقل کد نیاز دارد و گوگل یک نسخه آزمایشی از جمینی 2.0 فلش (gemini-2.0-flash-exp) را برای آزمایش ارائه میدهد.
پردازش چندوجهی داخلی، دقت را افزایش میدهد
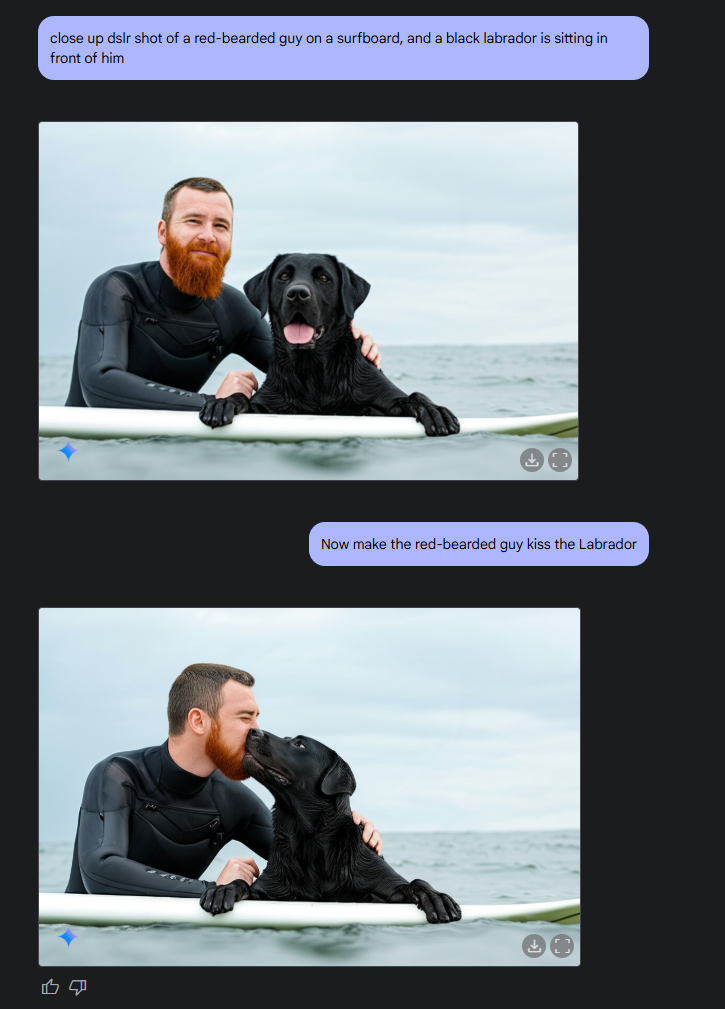
آنچه تولید تصویر جمینی را متمایز میکند، پایه چندوجهی آن است. مدل چندوجهی بزرگ (LML) (Large Multimodal Model) درک متن، استدلال پیشرفته و پردازش ورودی چندوجهی را برای تولید تصاویر دقیقتر از مدلهای تولید تصویر سنتی ترکیب میکند.
به گفته گوگل، این مدل میتواند با ترکیب متن و تصاویر، روایتهای بصری سازگاری ایجاد کند و سازگاری شخصیت و تنظیمات را در چندین تصویر حفظ کند. همچنین ویرایش تصویر محاورهای را از طریق چندین مرحله دیالوگ امکانپذیر میکند و آن را بهویژه برای بهبودهای تکراری در حین حفظ زمینه در طول مکالمه مفید میسازد.
شایعه شده است که OpenAI ویژگیهای تصویر چندوجهی را در ماه مارس عرضه میکند
OpenAI قبلاً نشان داده است که چه چیزی در این فضا با مدل GPT-4o خود در ماه مه 2024 امکانپذیر است. GPT-4o مانند جمینی به عنوان یک سیستم هوش مصنوعی چندوجهی بومی ساخته شده است که میتواند ورودیهای متن، صدا، تصویر و ویدیو را پردازش کند و در عین حال خروجیهای مختلفی از جمله متن، صدا و تصاویر تولید کند.
این شرکت طیف وسیعی از قابلیتها، از داستانسرایی بصری و طراحیهای دقیق کاراکتر گرفته تا تایپوگرافی خلاقانه و رندر سه بعدی واقعگرایانه را به نمایش گذاشت. در حالی که این ویژگیها هنوز به طور عمومی منتشر نشدهاند، منابع صنعتی نشان میدهند که OpenAI آنها را در مارس 2025 عرضه خواهد کرد - زمانی که به دنبال اعلامیه گوگل محتملتر به نظر میرسد. کارمندان OpenAI نیز به ویژگیهای تولید تصویر آینده اشاره کردهاند.
ویدیو: از طریق Oriol Vinyals
دانش جهانی داخلی مدل به ایجاد تصاویر واقعگرایانه و دقیق کمک میکند، اگرچه گوگل خاطرنشان میکند که این دانش، اگرچه گسترده است، اما مطلق نیست. این سیستم همچنین در ادغام متن در تصاویر برتری دارد و بنچمارکهای داخلی ادغام متن برتر را در مقایسه با مدلهای رقیب پیشرو نشان میدهند.
- گوگل یک نسخه آزمایشی از مدل هوش مصنوعی جمینی 2.0 فلش را برای توسعهدهندگان منتشر کرده است که میتواند متن را درک کرده و تصاویر را مستقیماً بر اساس ورودی تولید کند.
- قابلیت منحصربهفرد جمینی در توانایی آن در پردازش همزمان متن، تجزیه و تحلیل منطقی محتوا و تفسیر تصاویر نهفته است که آن را قادر میسازد تصاویر دقیقتر و واقعگرایانهتری را در مقایسه با مدلهای تصویر خالص ایجاد کند.
- گوگل بر نقاط قوت جمینی در حفظ ثبات در چندین تصویر هنگام به تصویر کشیدن چهرهها و صحنهها، و همچنین توانایی آن در ادغام دقیق عناصر متنی در تصاویر تولید شده تأکید میکند.
منابع: Google