از زمان انتشار ChatGPT اصلی، حرفهای زیادی در مورد ساخت یک نسخه واقعاً متنباز از آن — با تمام دادهها، کد، وزنها و غیره — زده شده است. نسخههای متنباز شفافیت، دسترسی، پیشرفت بلندمدت، تحقیقات امنیتی و موارد بسیار دیگری را افزایش میدهند. بسیاری از افراد از این ادعا برای ایجاد هیاهو در پروژههای خود استفاده کردهاند، اما محتوای این نسخهها نسبتاً سطحی بوده است (یعنی اغلب بر یک ارزیابی متمرکز بودهاند).
این نقطه عطف آنقدر طول کشید که من به طور کلی آن را به عنوان یک هدف فراموش کردم. در طول سال ۲۰۲۴، و به ویژه قبل از DeepSeek، این تصور وجود داشت که مقیاسبندی قابلیتهای هوش مصنوعی برای بازیکنان کوچکتر که مایل به انجام توسعه واقعاً متنباز هستند، بسیار پرهزینه است.
انتشارهای واقعاً باز، تلاش زیادی را با تولید بیشتر برای انتشار و نگهداری، باز کردن خطرات حقوقی بالقوه که انواع دادههای آموزشی را منع میکند، و به طور کامل تضعیف رقابت، انجام میدهند. معدود سازمانهایی که تحقیقات کاملاً متنباز انجام میدهند، سازمانهای غیرانتفاعی مانند Ai2 یا Eleuther AI؛ دانشگاهیان، مانند LLM360؛ یا شرکتهایی هستند که از رشد اکوسیستم بلندمدت بهرهمند میشوند، مانند HuggingFace.
داشتم نتایج آخرین مدل خود را بررسی میکردم که متوجه شدم بالاخره این کار را انجام دادیم! ما یک مدل کلاس GPT-4 کاملاً متنباز داریم، یعنی با نسخه اصلی OpenAI قابل مقایسه است تا نسخه فعلی.
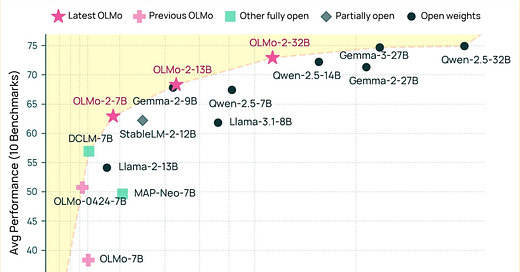
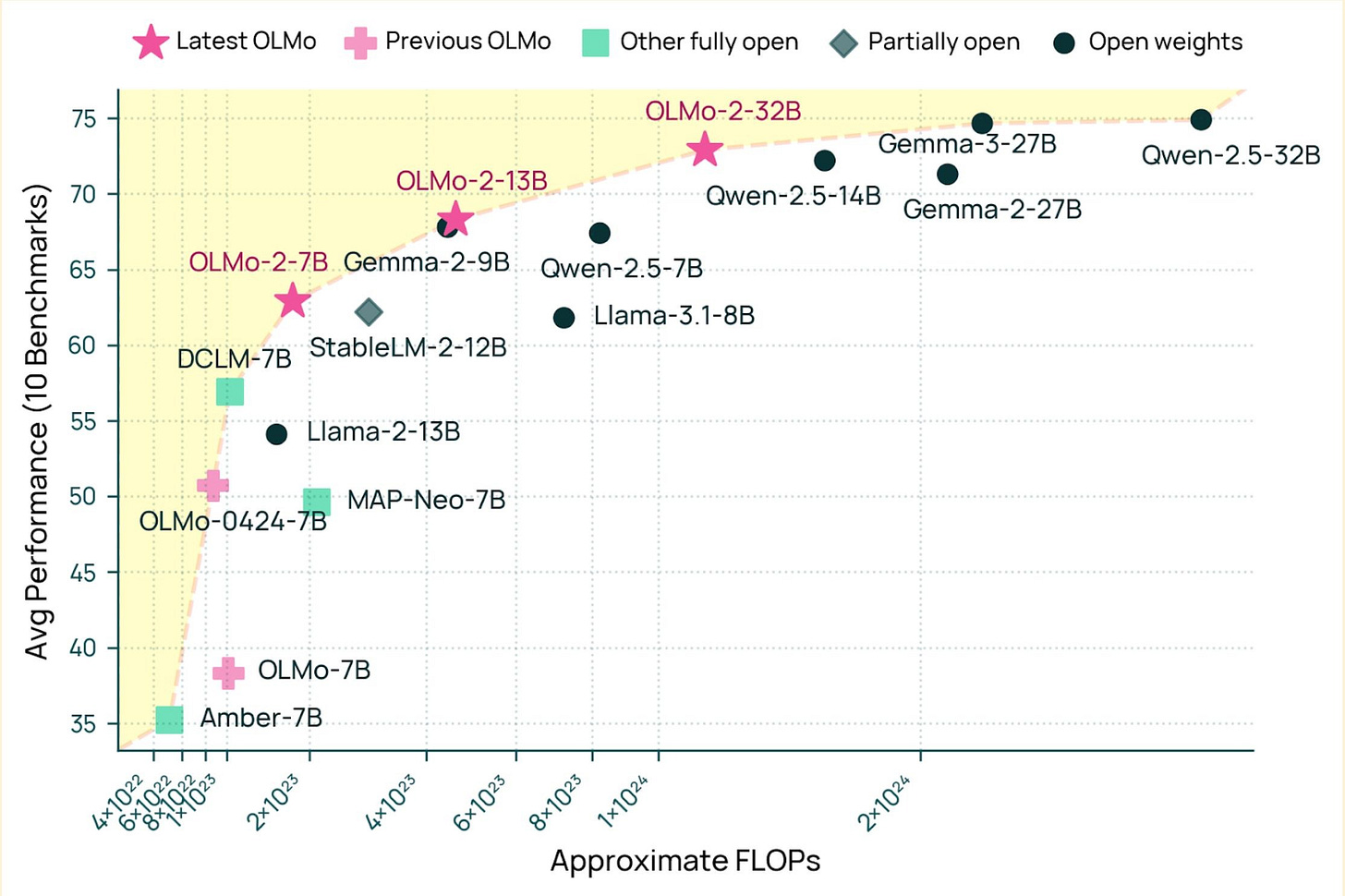
امروز، ما OLMo 2 32B را منتشر میکنیم، بزرگترین مدلی که تاکنون از ابتدا آموزش دادهایم. در اینجا ارزیابیهای پس از آموزش آمده است، جایی که از GPT-3.5، GPT-4o-mini، Qwen 2.5 32B Instruct، Mistral Small 24B اخیر پیشی میگیرد و به مدلهای Qwen و Llama 70B Instruct نزدیک میشود.
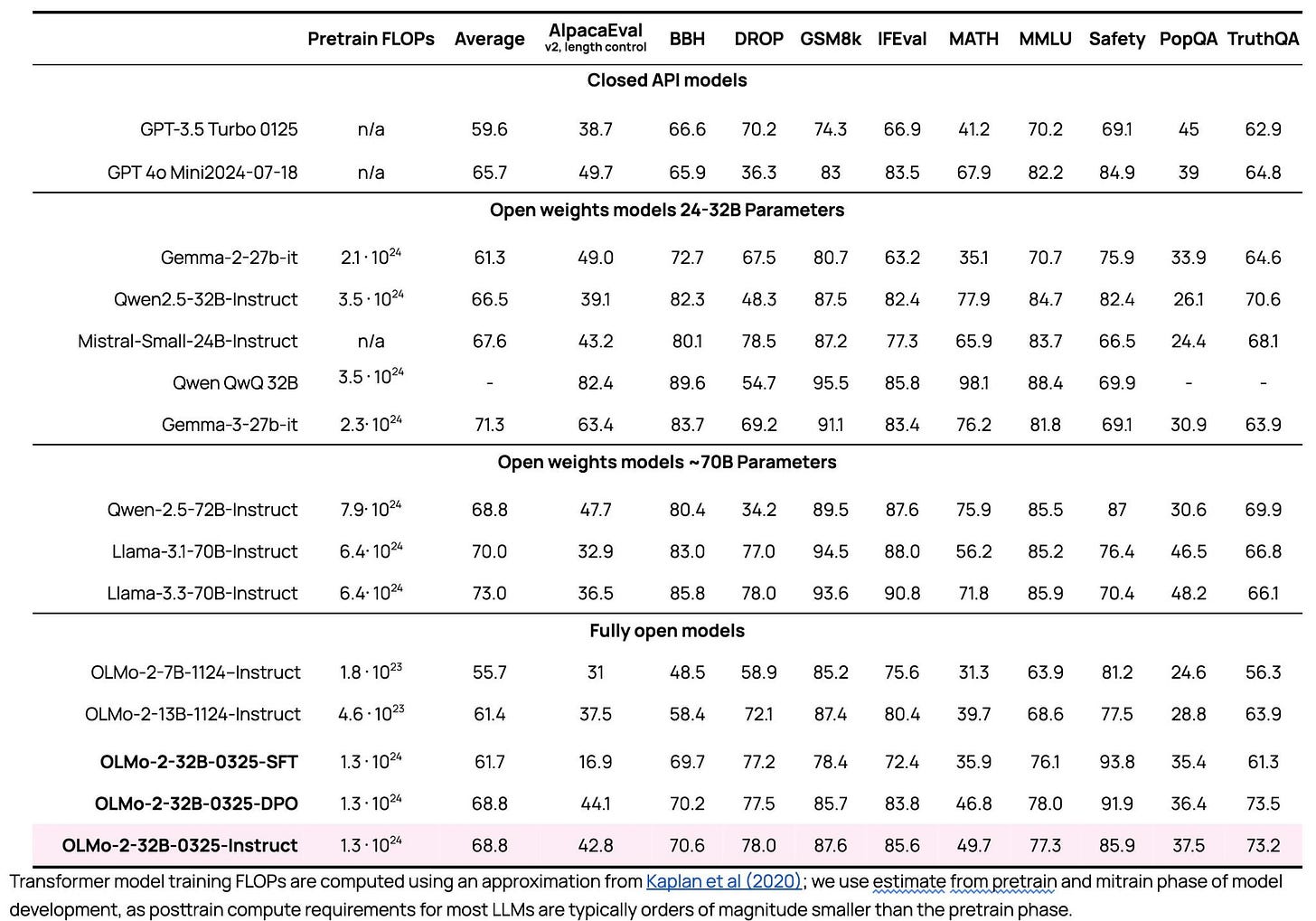
و این دستورالعمل بسیار کارآمد است. در اینجا یک نمودار نشان میدهد مقایسههای FLOP با مدلهای پایه همتا:
بیشتر این انتشار کاملاً جدید نیست. OLMo 2 نتیجه بسیاری از بردهای کوچک در دادهها، معماری، پس از آموزش با دستورالعمل Tülu 3 و غیره است — ما فقط به GPU اجازه دادیم برای مدت طولانیتری وزوز کنند. میتوانید در اعلامیه انتشار اصلی من یا در این پادکست با سرنخها اطلاعات بیشتری در مورد OLMo 2 کسب کنید.
بخش جدید این انتشار یک نقطه عطف بزرگ است که در آن هر شرکتی میتواند پشته آموزشی ما را بردارد و دقیقاً مدلی را که نیاز دارند در سطح GPT 4 بپزد. شکست دادن آخرین مدلهای GPT 3.5 و GPT 4o mini احساس یک بازی جوانمردانه برای این ادعا است. این قابلیت زمان میبرد تا منتشر شود، اما یک لحظه بزرگ در قوس دلیل کاری است که ما انجام میدهیم. حتی بدون پیشرفت بیشتر در OLMo، که بدیهی است امسال به این کار ادامه خواهیم داد، این کار باعث میشود پیشرفت اساسی هوش مصنوعی در خارج از آزمایشگاههای بزرگ هوش مصنوعی برای چندین سال ادامه یابد. این یک روز خوشبینانه برای متنباز است.
در اینجا پیوندهای شما به اطلاعات بیشتر در مورد OLMo 32B وجود دارد:
-
وبلاگ با جزئیات فنی و نسخه نمایشی
-
مدل پایه: OLMo-2-0325-32B
-
مدل Instruct: OLMo-2-0325-32B-Instruct و SFT میانی، OLMo-2-0325-32B-SFT، و ایستگاههای بازرسی DPO، OLMo-2-0325-32B-DPO
-
مجموعه داده پیش آموزش: OLMo-mix-1124
-
مجموعه داده میان آموزش: Dolmino-Mix-1124
-
مجموعه دادههای پس از آموزش: Tülu 3 SFT Mix (به روز شده)، دادههای اولویت برای OLMo 2 32B و RLVR Mix
Gemma 3 به عنوان نقطه بعدی در یک خط روند شیب دار
دیروز، ۱۲ مارس، گوگل دسته بعدی مدلهای با وزن باز پرچمدار خود، Gemma (گزارش، مدلها، مدل پرچمدار) را منتشر کرد. آنها قابلیتهای زیر را در مستندات خود برجسته میکنند:
ورودی تصویر و متن: قابلیتهای چندوجهی به شما امکان میدهد تصاویر و متن را برای درک و تجزیه و تحلیل دادههای بصری وارد کنید. شروع به ساخت کنید
متن ۱۲۸ هزار توکنی: ۱۶ برابر متن بزرگتر برای تجزیه و تحلیل دادههای بیشتر و حل مسائل پیچیدهتر.
پشتیبانی گسترده از زبان: با پشتیبانی از بیش از ۱۴۰ زبان، به زبان خود کار کنید یا قابلیتهای زبان برنامه هوش مصنوعی خود را گسترش دهید. شروع به ساخت کنید
اندازههای مدل دوستانه توسعه دهنده: اندازه مدل (1B، 4B، 12B، 27B) و سطح دقت را انتخاب کنید که بهترین کار را برای وظیفه و منابع محاسباتی شما انجام دهد.
برخی از جزئیات فنی قابل توجه:
-
در مدلهای باز، مدلهای متراکم 32B مناسب هستند زیرا میتوانند روی یک گره از 8 H100 (به آرامی) تنظیم شوند. اندازه گوگل در 27B احتمالاً در پایین دست ملاحظات TPU است که مستقیماً نگاشت نمیشوند، مانند نحوه عملکرد تقطیر دانش در پیش آموزش.
-
مدلهای Gemma به طور گسترده با دانشآموز-معلم تقطیر دانش (KD) آموزش داده میشوند. این KD با تعریف محاورهای تقطیر در مدلهای هوش مصنوعی پیشرو متفاوت است. استفاده رایج از تقطیر آموزش مدلها بر روی هر خروجی یک مدل بسیار قویتر است. این کار معمولاً در پس از آموزش برای یادگیری از تکمیلهای تولید شده مدل قویتر انجام میشود.
KD زیرمجموعهای از ایده کلی تقطیر است، جایی که مدلی که در حال آموزش است یاد میگیرد که با توزیع مدل معلم مطابقت داشته باشد. آزمایشگاههای دیگری غیر از DeepMind این تکنیک KD را ذکر کردهاند، اما گوگل آن را بسیار بیشتر پیش برده است. این موضوع در پست تابستان گذشته در مورد دادههای مصنوعی بیشتر مورد بحث قرار گرفت.
در غیر این صورت، مقاله اطلاعات جالبی دارد اما هیچ چیز فوق العادهای نیست. این برای اکثر گزارشهای فنی این روزها معمول است.
به ارزیابیها، و در نتیجه، تأثیر Gemma 3 میرسیم.
بهترین راه برای فکر کردن در مورد این مدل، یک "مدل چت عمومی" مانند GPT-4o و Claude 3.7 است تا یک مدل استدلال مانند R1. ظهور مدلهای استدلال، مقایسه مدلها را دشوار کرده است زیرا مجموعههای ارزیابی متعددی وجود دارد که مردم به آنها اهمیت میدهند — که به طور کلی به عنوان مجموعه استدلال و مجموعه دستورالعمل مشخص میشوند. آنها همپوشانی دارند، اما قابلیتهای قوی در هر دو نادر است.
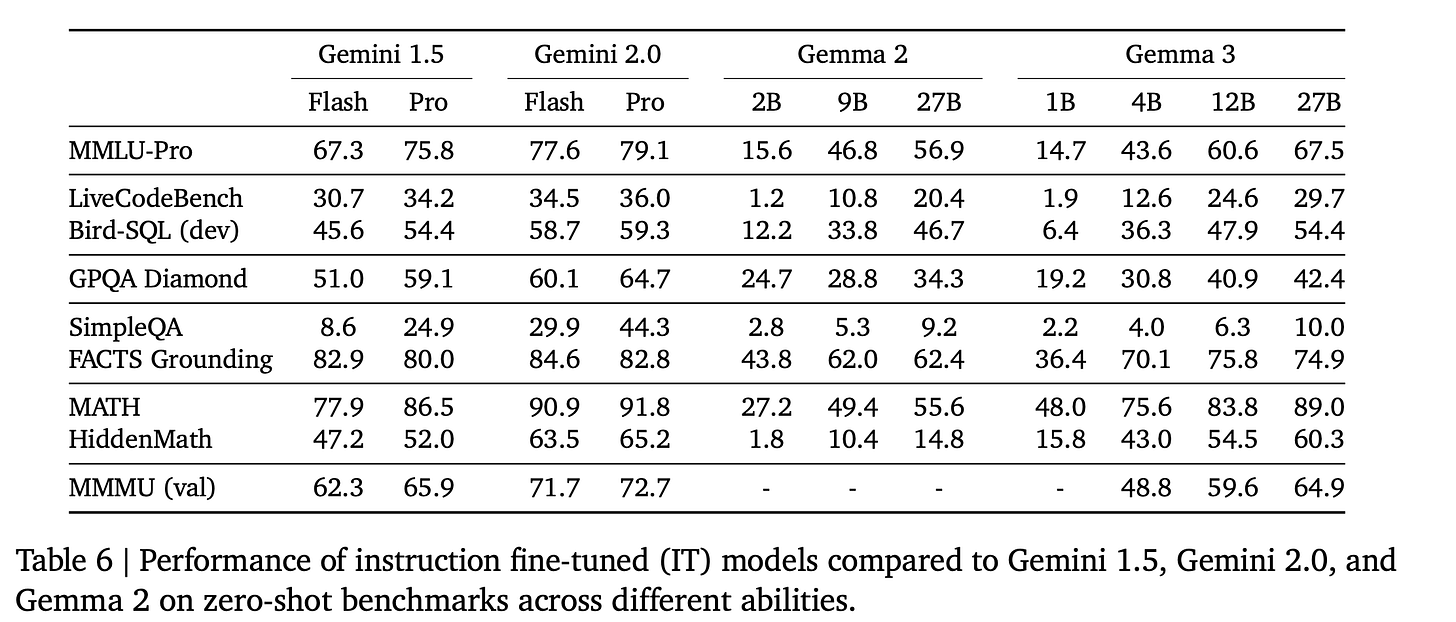
عملکرد Gemma 3 27B در برخی از وظایف مانند MATH و Bird-SQL (کدنویسی) با مدل Gemini 1.5 Pro از چند ماه پیش مطابقت دارد! پیشرفت در مدلهای کوچک با وزن باز به سادگی دیوانهوار است. مدلهای کوچک میتوانند به طور عالی در وظایف باریک مانند ریاضی و برخی کدنویسی عمل کنند، اما فاقد عمق و دانش جهانی هستند، همانطور که در GPQA یا SimpleQA در بالا دیده میشود.
بله، تقطیرهای DeepSeek در اندازههای کوچکتر در MATH بهتر هستند، اما افراد کافی این تقطیرها را در تمام قابلیتها مانند ChatBotArena ارزیابی نمیکنند. داشتن همه چیز در یک مدل بسیار راحت است و هنوز هم نحوه انجام بیشتر جریانهای کاری است.
اکثر مردم همچنین نسبتاً نسبت به نمرات ارزیابی مانند MATH که توسط Gemma، تقطیرهای DeepSeek و امثال آن بیان شده است، تردید دارند و ادعا میکنند که به سودمندی دنیای واقعی ترجمه نمیشوند. به همین دلیل است که نتایج ChatBotArena چشمگیرترین نتایج انتشار Gemma 3 بود. Gemma 3 در 15 رتبه برتر هر دسته قرار میگیرد. DeepSeek V3 را با بیش از 600B پارامتر کل خود شکست میدهد. مدلهای همتای آن در رتبهبندی کلی در دستههای خاص مانند ریاضی یا کدنویسی عملکرد بهتری دارند، که نشان دهنده سطح کوچکی از همسویی سطحی است، اما انجام این کار برای ورود به 10 رتبه برتر ChatBotArena در این دوره هوش مصنوعی با رقابت بسیار زیاد یک دستاورد بزرگ است.
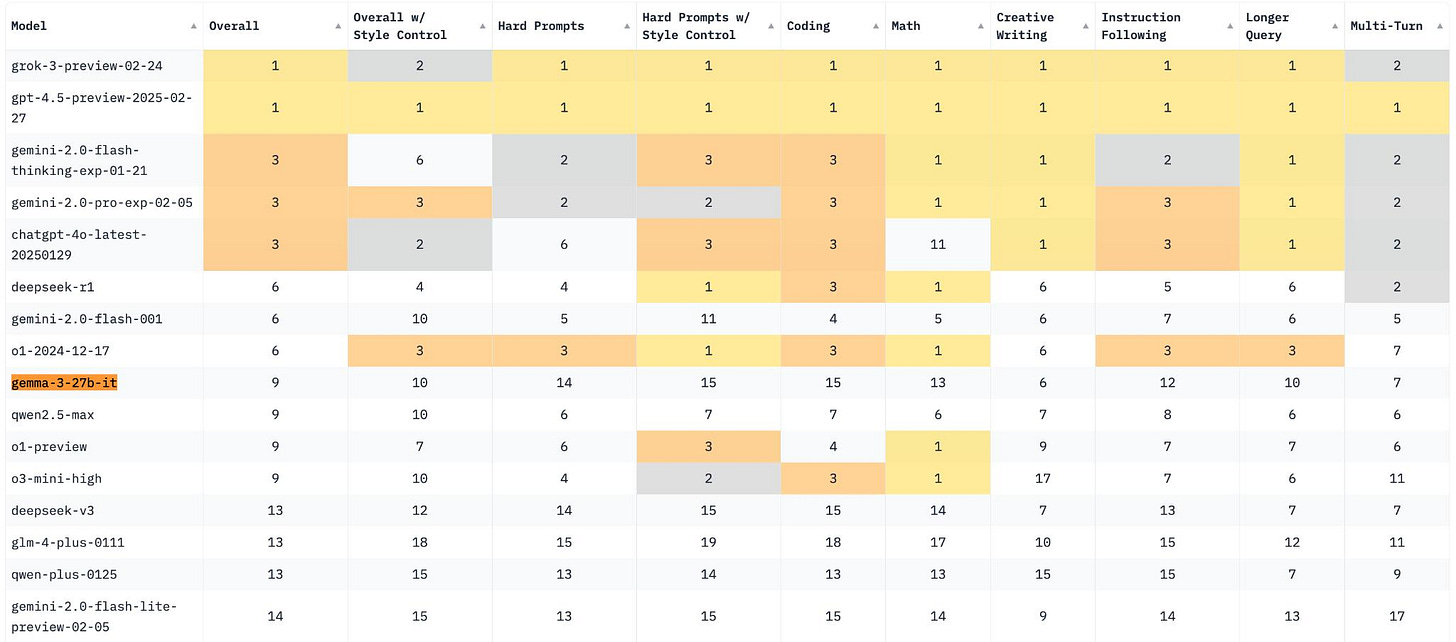
این یک سوال باز همیشه در حال تحول است که ارزیابیهای چت مانند ChatBotArena چقدر قابل اعتماد هستند. این روزها، با رواج روشهای آموزشی RL برای به حداکثر رساندن ارزیابیهای MATH، ارزش دوباره بالاتر است. آیا این نشان دهنده زیرمجموعهای از استفاده در دنیای واقعی است، که نشان میدهد قابلیتهای خاصی که مدلهای کوچک میتوانند در آن برتری داشته باشند — ریاضی، چت عمومی و غیره — میتوانند مستقیماً به ارزش واقعی ترجمه شوند.
این بدان معناست که وظایفی مانند SimpleQA و GPQA نشان دهنده عملکرد در وظایف خاصتری هستند که افراد زیادی با آن مواجه نمیشوند، اما ما به عنوان یک رشته در اینجا چیزهای زیادی برای یادگیری داریم.
با استفاده من از مدلهای پیشرو، باور این برایم سخت است — جابجایی به چیزی مانند GPT-4.5 احساس یک بهبود فوری در وظایف چت است. نتیجه گیری من این است که پاسخ جایی در وسط است — مدلهای باز کوچک میتوانند در وظایف روزمره بسیار خوب عمل کنند، اما ما دقیقاً نمیدانیم چگونه آن را اندازهگیری کنیم. ChatBotArena و SimpleQA دقیقاً به ما نمیگویند که از مدلها چه انتظاری داشته باشیم.
این واقعیت که هیچ پرتگاهی در عملکرد با مدلهای به این کوچکی وجود ندارد، باعث ایجاد ارزش تجاری قابل توجهی میشود — یافتن دقیقاً حداقل اندازه مدل مورد نیاز برای توزیع وظایف شما آسانتر خواهد بود.
در مورد خاص Gemma و بیشتر مدلهای با وزن باز پیشرو در حال حاضر (با DeepSeek R1 به عنوان یک استثنای فوق العاده)، مجوزهای مدلهایی که اغلب استفاده پایین دستی را محدود میکنند، ترمزی بر پذیرش مدل با وزن باز هستند. بدون ورود زیاد به جزئیات، آنها شرکتهایی را که به دنبال استفاده از مدلها هستند، در معرض مقداری خطر قانونی قرار میدهند و شرایط و ضوابطی را به مدلهای تنظیم شده اضافه میکنند.
به طور کلی، تا زمانی که حلقههای بازخورد و موارد استفاده برای مدلهای باز ایجاد نشود، تیمهایی که این مدلها را منتشر میکنند، موارد قوی دیگری غیر از پتانسیل رشد آینده برای مقابله با گزینه ایمن ناشی از توصیههای تیمهای حقوقی ندارند. امیدوارم که تکامل در پذیرش مدلهای با وزن باز برای برنامههای ارزشمند، فشاری وارد کند تا صدور مجوز دردسر کمتری داشته باشد.
Interconnects یک نشریه با پشتیبانی خوانندگان است. مشترک شدن را در نظر بگیرید.
وضعیت شکاف مدل باز-بسته
3 از 15 مدل برتر در ChatBotArena وزن باز هستند. در دنیایی که آزمایشگاههای مرزی نسخههای مدل جزئی زیادی دارند که تابلو امتیازات را شلوغ میکنند، این یک پلتفرم باورنکردنی برای تسریع پیشرفت در پذیرش مدل باز است. حتی فقط شکاف از Gemma 3 تا مدلهای پرچمدار Gemini گوگل بسیار کوچک است! کل بازار هوش مصنوعی پویاترین و رقابتیترین بازاری است که در مدتی پیش بوده است — شاید همیشه.
وقتی صحبت از "واقعاً باز" میشود، یعنی مدلهای منبع باز واقعی، شکاف بین مدلهای بسته تا حدودی ثابت باقی مانده است — من آن را حدود 18 ماه عقبتر از آزمایشگاههای بسته تخمین میزنم. با افزایش کلی مدلهای باز، دسترسی منبع باز به کد، داده و غیره احتمالاً با آن همراه خواهد بود. مواردی مانند Llama، DeepSeek و غیره برخی از مهمترین قطعات در اکوسیستم باز کامل هستند و رویکردهایی مانند Ai2 بدون آنها با مشکل مواجه میشوند.
مرتبط با این موضوع، در پوشش DeepSeek R1، اشاره کردم:
این به اولین بار از زمان انتشار Stable Diffusion اشاره دارد که مرتبطترین و مورد بحثترین مدل هوش مصنوعی با یک مجوز بسیار دوستانه منتشر میشود. با نگاهی به سفر هوش مصنوعی "منبع باز" در 2.5 سال گذشته، این یک لحظه شگفتانگیز در زمان است که در کتابهای تاریخ ثبت شده است.
یک ماه بعد، این هنوز هم مورد است.
برای درک پیشرفت شکاف مدل باز-بسته، با یک سادهسازی بیش از حد، دو روش ساده وجود دارد که مدلها تمایل به بهتر شدن دارند:
- مقیاسبندی اندازه مدل، و
- بهبودهای مختلف داده، معماری و الگوریتم که یک مدل با عملکرد معادل را کوچکتر میکنند.
پیشرفت در مدلهای منبع باز واقعی همیشه به دومی از اینها به دلیل بودجههای نسبتاً کوچکتر بازیکنان در فضای منبع باز متکی بوده است. با مجبور شدن به تمرکز بر کارایی به جای مقیاسبندی، اغلب به نظر میرسید که مدلهای منبع باز واقعی بیشتر از آنچه که احتمالاً واقعاً بودند، عقب ماندهاند. با پتانسیل مشابه برای مقیاسبندی، شکاف بین منبع باز واقعی و بسته در معیارهای استاندارد آکادمیک که "پتانسیل مدل خام" معمولاً در آن ارزیابی میشود، بسیار کوچک خواهد بود.
هنگامی که مدلهایی مانند Llama 3.1 405B، DeepSeek V3 و R1 و غیره منتشر میشوند، مدلهای با وزن باز که مقیاسبندی شدهاند در مرز بودهاند. با منابع بیشتر برای آموزش منبع باز واقعی، من دلایل زیادی نمیبینم که چرا این برای مدلهایی مانند OLMo نیز اینطور نباشد. از برخی جهات، بزرگترین خندق برای آموزش فقط دسترسی به منابع است. به عنوان مثال، گزارش شده است که DeepSeek حداقل 10 برابر بیشتر از Ai2 محاسبه دارد.
این تفسیر از شکاف قابل حلتر از سایر انتقاداتی است که من در گذشته به جامعه هوش مصنوعی منبع باز تحمیل کردهام، مانند نیاز به دادههای ترجیحی بهتر/خطوط لوله RLHF.
با مقایسه Gemma 3 27B با OLMo 32B، ارزیابیهای پیش آموزش برای هر دو بسیار مشابه هستند، اما نمرات Gemma 3 پس از پس از آموزش بسیار بهتر هستند. سقف انتظارات پس از آموزش به سرعت در بین مدلهای باز تغییر کرده است. به طور کلی، دستورالعملهای باز با مطابقت با اثباتهای وجودی مانند Gemma 3 یا DeepSeek R1 انگیزه میگیرند. در طول سال 2025، انتظار داشته باشید که منابع پس از آموزش باز دوباره بهتر شوند، که با نیاز به عملکرد بهتر و گردشهای کاری دقیقتر در آموزش استدلال انگیزه میگیرد.
همه این ظرافتها زمینه را برای یک پلتفرم بهتر برای ایجاد ارزش با مدلهای باز هموار میکنند. شکاف بین مدلهای بسته و همتایان باز آنها کوچکترین است، به این معنی که فرصت بهترین چیزی است که تا به حال بوده است.
رقابت برای ارائه دهندگان استنتاج برای میزبانی مدلهایی مانند DeepSeek R1 یک پلتفرم عالی برای پیشرفت و مثال است. حتی اگر چرا مدلهای باز در درجه اول برای بازاریابی و استخدام خوب باشند، این میتواند به مزایای بزرگتر تبدیل شود.
مدلهای با وزن باز به احتمال زیاد در کوتاه مدت با حاشیههای بسیار کمتری برای استنتاج ارائه میشوند، به دلیل رقابت شدید در فضای استنتاج، که قیمتها را حتی برای کسانی که به دنبال راههایی برای پذیرش آنها هستند، کاهش میدهد. در اینجا یک مثال از برخی از پلتفرمهای پیشرو که استنتاج R1 را ارائه میدهند، آورده شده است:
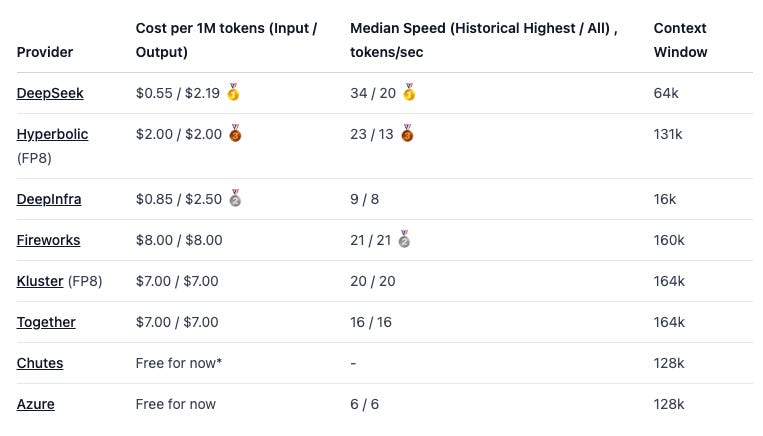
حتی مدلهایی که به روشهای دیگر در بازار عرضه میشوند، از رقابت برخوردارند، مانند ارائهدهندگان خط لوله RLHF، حاشیه خود را تحت فشار قرار میدهند و مشتریان را بیشتر از همیشه در اولویت قرار میدهند.
به طور کلی، چشم انداز فعلی برای مدلهای با وزن باز بسیار خوشبینانه است.
با تشکر ویژه از رادریگو آلوارز برای خواندن پیش نویس این پست!
Disclaimer: I work at Hugging Face.