در ظاهر، مدلهای زبانی بزرگ (LLM) بسیار ساده به نظر میرسند—چیزی را تایپ میکنید و آنها پاسخی تولید میکنند. ورودی ساده، خروجی ساده. اما در زیر این ظاهر، یک
در هسته خود، همه چیز به یک چیز خلاصه میشود:
در این پست، من
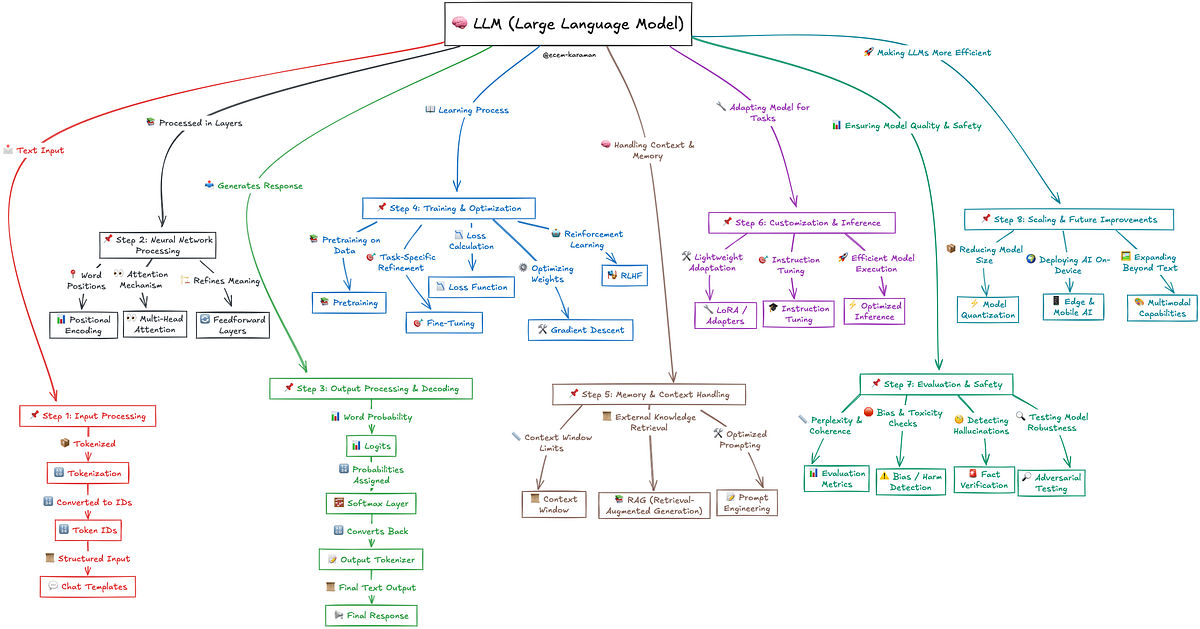
در یک سطح بالا، این خط لوله را میتوان به
- پردازش ورودی—تبدیل متن خام به دادههای ساختاریافته که مدل بتواند با آن کار کند.
- پردازش شبکه عصبی—اعمال لایههای توجه و تبدیلها برای استخراج معنا.
- پردازش و رمزگشایی خروجی—تبدیل محاسبات به متن.
- آموزش و بهینهسازی—چگونه مدل الگوها را از مقادیر زیادی از دادهها یاد میگیرد.
- مدیریت حافظه و زمینه—مدیریت مکالمات طولانی و پیگیری ورودیهای قبلی.
- سفارشیسازی و استنتاج—تنظیم دقیق و انطباق مدلها برای کاربردهای دنیای واقعی.
- ارزیابی و ایمنی—تضمین دقت، کاهش تعصبها و بهبود قابلیت اطمینان.
- مقیاسبندی و بهبودهای آینده—چگونه این مدلها در حال هوشمندتر و کارآمدتر شدن هستند.
این اولین پست در یک سری پستها است که در آن خط لوله LLM را به هشت مرحله تقسیم میکنم. در پستهای آینده، من به بررسی عمیق هر مرحله، مهندسی معکوس مکانیسمهای اساسی، مبانی ریاضی، معماریهای کلیدی مدل و پیادهسازیهای دنیای واقعی خواهم پرداخت.
آیا میخواهید عمیقتر شوید؟ برای دفترچههای یادداشت عملی Jupyter در کنار این راهنما، GitHub من را بررسی کنید.

گام اول: پردازش ورودی (نحوه آمادهسازی متن برای مدل)
مدلهای زبانی بزرگ (LLM) متن را «نمیخوانند»—آنها
هدف: تبدیل متن خام کاربر به قالبی که مدل بتواند آن را درک کند.
متن خام ← نشانهگذاری ← شناسههای نشانه ← ورودی ساختاریافته برای مدل
مراحل کلیدی:
- متن خام ← متن پیشپردازششده:ورودی را تمیز میکند (فضاهای غیرضروری را حذف میکند، حروف را نرمال میکند، کاراکترهای خاص را قالببندی میکند).
- متن ← نشانهها:ورودی را با استفاده از یک نشانهگذار (BPE، WordPiece، Unigram) به کلمات/زیرکلمات تقسیم میکند.
- نشانهها ← شناسههای نشانه:هر نشانه را بر اساس واژگان مدل به یک شناسه عددی منحصر به فرد نگاشت میکند.
- شناسههای نشانه ← الگوهای چت (در صورت وجود):ورودی را به نقشهای سیستم، کاربر و دستیار برای هوش مصنوعی مکالمهای ساختار میدهد.
- شناسههای نشانه ← ورودی مدل:نشانهها را در قالبی با padding، truncation و ماسکهای توجه بستهبندی میکند.
- ارسال به شبکه عصبی:ورودی کدگذاریشده برای پردازش بیشتر به لایه embedding مدل ارسال میشود.
import tiktoken tokenizer = tiktoken.encoding_for_model("gpt-4") text = "I want to learn about LLMs" tokens = tokenizer.encode(text) print("Token IDs:", tokens) # [40, 1390, 311, 4048, 922, 445, 11237, 82] print("Decoded Tokens:", [tokenizer.decode([t]) for t in tokens]) #['I', ' want', ' to', ' learn', ' about', ' L', 'LM', 's']
گام دوم: پردازش شبکه عصبی (مدلهای زبانی بزرگ چگونه فکر میکنند)
اینجاست که مدل معنا، زمینه و روابط بین کلمات را یاد میگیرد.
هدف: تبدیل embeddingهای نشانه با استفاده از لایههای خود-توجه و محاسبات عصبی.
شناسههای نشانه ← embeddingها ← کدگذاری موقعیتی ← خود-توجه ← نمایشهای تبدیلشده
مراحل کلیدی:
- شناسههای نشانه ← Embeddingها: شناسههای نشانه را از طریق یک ماتریس embedding به نمایشهای برداری متراکم نگاشت میکند.
- Embeddingها ← کدگذاری موقعیتی: اطلاعات ترتیب را با استفاده از کدگذاریهای سینوسی یا یادگرفتهشده اضافه میکند.
- کدگذاریهای موقعیتی ← مکانیزم خود-توجه: روابط بین همه نشانهها را از طریق ماتریسهای پرسش-کلید-مقدار (QKV) محاسبه میکند.
- خروجی خود-توجه ← توجه چندگانه: از چندین سر توجه برای ثبت روابط مختلف کلمات استفاده میکند.
- توجه چندگانه ← لایههای پیشخور: تبدیلهای غیرخطی را برای اصلاح نمایشهای یادگرفتهشده اعمال میکند.
- نمایشهای نهایی ← مرحله پردازش بعدی: embeddingهای پردازششده را برای رمزگشایی و پیشبینی نشانه خروجی میدهد.
گام سوم: پردازش و رمزگشایی خروجی (تولید نشانه بعدی)
هنگامی که مدل ورودی را پردازش میکند، با تبدیل نمایشهای داخلی به یک توزیع احتمال روی کلمات ممکن، نشانه بعدی را پیشبینی میکند.
هدف: تبدیل نمایشهای عددی به متن قابل خواندن توسط انسان.
حالت پنهان نهایی ← logits ← softmax ← انتخاب نشانه بعدی ← متن detokenized
مراحل کلیدی:
- حالت پنهان نهایی ← Logits: embeddingهای پردازششده را به نمرات خام (غیرنرمال) برای هر نشانه بعدی ممکن تبدیل میکند.
- Logits ← احتمالات: تابع softmax را برای تبدیل نمرات خام به یک توزیع احتمال اعمال میکند.
- انتخاب نشانه بعدی (استراتژیهای رمزگشایی): نشانه بعدی را با استفاده از روشهایی مانند رمزگشایی حریصانه، جستجوی پرتو یا نمونهبرداری انتخاب میکند.
- اضافه کردن نشانه به خروجی: نشانه انتخابشده را به دنباله رو به رشد اضافه میکند.
- شناسه نشانه ← متن (Detokenization): شناسه نشانه تولیدشده را دوباره به متن قابل خواندن توسط انسان تبدیل میکند.
- تکرار تا اتمام: این فرآیند تا رسیدن به یک نشانه پایان دنباله یا حداکثر طول حلقه میزند.
گام چهارم: آموزش و بهینهسازی (مدلهای زبانی بزرگ چگونه یاد میگیرند)
آموزش جایی است که یک LLM درک زبان را یاد میگیرد و الگوها را تشخیص میدهد—هرچه مجموعه داده بزرگتر باشد، مدل هوشمندتر است.
هدف: آموزش مدل با استفاده از مجموعههای داده عظیم و تکنیکهای بهینهسازی.
پیشآموزش (بدون نظارت) ← تنظیم دقیق (با نظارت) ← RLHF ← محاسبه loss ← بهروزرسانی وزنها
مراحل کلیدی:
- پیشآموزش (بدون نظارت): پیشبینی کلمات از دست رفته در متن در مقیاس بزرگ (پیشبینی کلمه بعدی، نشانههای پوشاندهشده).
- تنظیم دقیق (با نظارت): آموزش بر روی دادههای برچسبگذاریشده برای بهبودهای خاص وظیفه (به عنوان مثال، خلاصهسازی، پرسش و پاسخ).
- RLHF (یادگیری تقویتی): بهینهسازی پاسخها بر اساس بازخورد انسانی با استفاده از مدلهای پاداش.
- تابع Loss: اندازهگیری خطاهای پیشبینی (cross-entropy loss, KL divergence).
- Backpropagation: محاسبه گرادیانها و تنظیم وزنهای مدل بر اساس خطاها.
- بهینهسازی (Gradient Descent): وزنها را به صورت تکراری برای به حداقل رساندن loss (Adam, SGD) بهروزرسانی میکند.
گام پنجم: مدیریت حافظه و زمینه (مدلهای زبانی بزرگ چگونه چیزها را "به خاطر میآورند")
این مرحله به LLMها کمک میکند تا مکالمات را پیگیری کنند، جزئیات مربوطه را به یاد بیاورند و پاسخهای طولانیتر را بهبود بخشند!
هدف: حفظ زمینه در چندین نوبت در یک مکالمه.
محدودیتهای پنجره زمینه ← بهینهسازیهای توجه ← بازیابی (RAG) ← ساختاردهی prompt
مراحل کلیدی:
- پنجره زمینه: تعداد نشانههایی را که مدل میتواند به طور همزمان پردازش کند محدود میکند (به عنوان مثال، 4K، 8K، 100K نشانه).
- توجه پنجره کشویی: با انتقال پنجره به جلو با اضافه شدن نشانههای جدید، نشانههای اخیر را حفظ میکند.
- مدیریت زمینه طولانی: از مکانیزمهای توجه مانند ALiBi، RoPE یا ترانسفورماتورهای با کارایی حافظه استفاده میکند.
- تولید تقویتشده با بازیابی (RAG): اسناد خارجی مربوطه را برای تکمیل پاسخهای مدل واکشی میکند.
- مهندسی Prompt: ورودیها را برای هدایت یادآوری مدل و حفظ انسجام ساختار میدهد.
- ماندگاری حافظه (تنظیم دقیق در مقابل ابزارهای خارجی): وزنها را تنظیم میکند (تنظیم دقیق) یا از حافظه خارجی (پایگاه دادههای برداری) استفاده میکند.
گام ششم: سفارشیسازی و استنتاج (مدلهای زبانی بزرگ چگونه مستقر و استفاده میشوند)
اینجاست که LLMها در برنامههای دنیای واقعی مانند چتباتهای هوش مصنوعی، دستیارهای کدنویسی و موتورهای جستجو تنظیم، بهینهسازی و مستقر میشوند.
هدف: انطباق مدلهای از پیش آموزشدیده با موارد استفاده خاص.
تنظیم دقیق ← تنظیم دستورالعمل ← تنظیم prompt ← LoRA ← پاسخهای بهینه شده در زمان واقعی
مراحل کلیدی:
- مدل از پیش آموزشدیده ← مدل تنظیم دقیقشده: یک LLM عمومی را برای وظایف تخصصی (به عنوان مثال، کدنویسی، هوش مصنوعی پزشکی) تطبیق میدهد.
- تنظیم Prompt (Prompts نرم): embeddingها را به جای وزنها برای تطبیق سبک وزن تنظیم میکند.
- LoRA و لایههای آداپتور: فقط لایههای مدل خاص را به طور موثر تنظیم میکند و هزینههای محاسباتی را کاهش میدهد.
- تنظیم دستورالعمل: مدلها را آموزش میدهد تا دستورالعملهای ساختاریافته را با دقت بیشتری دنبال کنند.
- خط لوله استنتاج: ورودی کاربر ← نشانهگذاری ← پردازش مدل ← تولید پاسخ را تبدیل میکند.
- بهینهسازی تأخیر: از کوانتیزاسیون، distillation و batching برای پاسخهای سریعتر در زمان واقعی استفاده میکند.
گام هفتم: ارزیابی و ایمنی (چگونه LLMها را اندازهگیری و بهبود میبخشیم)
LLMها میتوانند توهم ایجاد کنند، تعصبها را تقویت کنند یا خروجیهای غیرقابل اعتماد تولید کنند، بنابراین ارزیابی بسیار مهم است.
هدف: اندازهگیری عملکرد، تشخیص تعصبها و اطمینان از خروجیهای هوش مصنوعی قابل اعتماد و اخلاقی.
Perplexity ← معیارهای انسجام ← بررسیهای تعصب/سمیت ← تشخیص توهم ← آزمایش استحکام
معیارهای ارزیابی کلیدی:
- Perplexity و دقت: Perplexity پایینتر = پیشبینیهای بهتر؛ دقت، صحت را در وظایف ساختاریافته اندازهگیری میکند.
- BLEU، ROUGE، METEOR (کیفیت متن): روان بودن و انسجام را در متن تولیدشده ارزیابی میکند.
- بررسیهای تعصب و انصاف: تعصبهای مضر را با استفاده از مجموعههای داده تخصصی شناسایی و کاهش میدهد.
- فیلترهای سمیت و ایمنی: طبقهبندها را برای جلوگیری از خروجیهای مضر یا توهینآمیز اعمال میکند.
- تشخیص توهم: اطلاعات نادرست یا ساختگی را با استفاده از مدلهای سازگاری واقعی شناسایی میکند.
- Red-Teaming و آزمایش خصمانه: مدلها را در برابر prompts دستکاریکننده یا مخرب آزمایش استرس میکند.
گام هشتم: مقیاسبندی و بهبودهای آینده (بعدی برای LLMها چیست؟)
این مرحله بر سریعتر، مقیاسپذیرتر و سازگارتر کردن LLMها برای کاربردهای هوش مصنوعی آینده متمرکز است!
هدف: افزایش کارایی، افزایش طول زمینه و گسترش قابلیتها (به عنوان مثال، هوش مصنوعی چندوجهی)
مقیاسبندی مدل ← بهینهسازیهای کارایی ← زمینه طولانیتر ← هوش مصنوعی چندوجهی ← استقرار edge
- مقیاسبندی مدل (شبکههای بزرگتر): پارامترها را (GPT-3 → GPT-4) برای عملکرد بهتر افزایش میدهد.
- معماریهای کارآمد: از مدلهای پراکنده (Mixture of Experts, Transformer-XL) برای کاهش هزینههای محاسباتی استفاده میکند.
- پنجرههای زمینه طولانیتر: محدودیتهای نشانه را با استفاده از مکانیزمهای توجه با کارایی حافظه (ALiBi, RoPE) گسترش میدهد.
- Quantization و Pruning: اندازه مدل را در حالی که دقت را حفظ میکند کاهش میدهد تا استنتاج سریعتر شود.
- On-Device و Edge AI: مدلهای کوچکتر را (GPT-4 Turbo, LLaMA) برای استقرار محلی بهینه میکند.
- قابلیتهای چندوجهی: فراتر از متن گسترش مییابد (مدلهای دیداری-زبانی، یکپارچهسازی گفتار).
در نگاه اول، LLMها ممکن است مانند یک جعبه سیاه به نظر برسند، اما وقتی به این 8 مرحله اصلی تقسیم میشوند، مشخص میشود که چگونه آنها پاسخهای هوشمند را پردازش، یاد میگیرند و تولید میکنند. از تبدیل متن خام به ورودیهای ساختاریافته تا پیشبینی نشانه بعدی و بهبود مستمر از طریق آموزش و بهینهسازی، هر مرحله نقش مهمی در عملکرد این مدلها ایفا میکند.
این پست یک مرور کلی سطح بالا ارائه داد، اما در مقالات بعدی، من به بررسی عمیق هر مرحله، باز کردن جزئیات فنی، ریاضیات پشت آن و پیادهسازیهای دنیای واقعی خواهم پرداخت.
اگر از این مقاله لذت بردید:
برای پروژههایی در مورد AI/ML، امنیت سایبری و پایتون GitHub من را بررسی کنید.
برای گپ زدن درباره همه چیز در مورد هوش مصنوعی با من در LinkedIn ارتباط برقرار کنید.