
در طول دهه گذشته، علم داده دستخوش تحولات چشمگیری شده است که ناشی از پیشرفتهای سریع در یادگیری ماشین، هوش مصنوعی و فناوریهای کلان داده بوده است. تجزیه و تحلیل تقریباً یک دهه جلسات کنفرانس از سال 2015 تا 2024 تغییرات جالبی را در زمینههای تمرکز، چارچوبهای محبوب و روندهای نوظهور که این حوزه را شکل دادهاند، نشان میدهد.
این بلاگ به بررسی عمیق این تغییرات در روندهای علم داده میپردازد و نشان میدهد که چگونه موضوعات کنفرانس بازتابی از تحولات گستردهتر علم داده است.
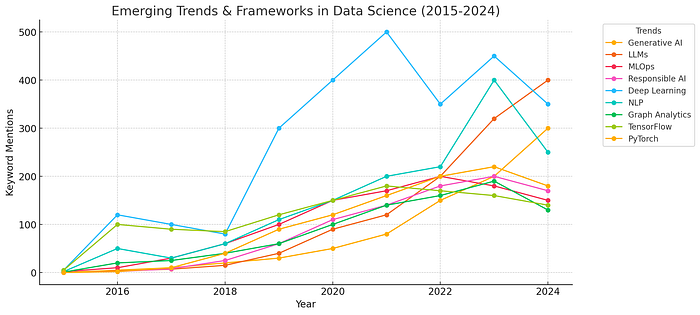
سالهای اولیه: ایجاد پایهها (2015–2017)
در سالهای اولیه، کنفرانسهای علم داده عمدتاً بر موضوعات اساسی مانند تحلیل دادهها، تصویرسازی و ظهور کلان داده متمرکز بودند. ابزارهایی مانند Python، R و SQL از ارکان اصلی بودند و جلسات حول محور دستکاری دادهها، هوش تجاری و نقش رو به رشد دانشمندان داده در تصمیمگیری متمرکز بودند.
تا سال 2017، یادگیری عمیق به دلیل پیشرفت در شبکههای عصبی و انتشار چارچوبهایی مانند TensorFlow شروع به ایجاد موج کرد. جلسات مربوط به شبکههای عصبی کانولوشن (CNN) و شبکههای عصبی بازگشتی (RNN) شروع به کسب محبوبیت کردند که نشاندهنده آغاز تغییر علم داده به سمت روشهای مبتنی بر هوش مصنوعی بود.
رونق یادگیری عمیق (2018–2019)
بین سالهای 2018 و 2019، یادگیری عمیق بر چشمانداز کنفرانس غالب بود. محققان و متخصصان معماریهای پیچیده را از ترانسفورماتورها گرفته تا یادگیری تقویتی بررسی کردند که منجر به افزایش جلسات در زمینه پردازش زبان طبیعی (NLP) و بینایی رایانه شد.
جنگهای چارچوبی در اوج خود بود: در حالی که TensorFlow در ابتدا پیشتاز بود، PyTorch به عنوان یک رقیب قوی به ویژه در جامعه تحقیقاتی ظاهر شد.
تحلیل گراف نیز در این مدت جایگاه ویژهای را به خود اختصاص داد و علاقه به گرافهای دانش و شبکههای عصبی گراف به طور پیوسته در حال رشد بود.
MLOps، هوش مصنوعی اخلاقی و ظهور مدلهای زبانی بزرگ (2020–2022)
تغییر جهانی به کار از راه دور در طول همهگیری، علاقه به MLOps را تسریع کرد - مجموعهای از شیوهها برای استقرار، نظارت و مقیاسبندی مدلهای یادگیری ماشین. جلسات مربوط به خطوط لوله CI/CD، نظارت بر مدل و ابزارهایی مانند Kubeflow و MLflow در محبوبیت افزایش یافت.
به طور همزمان، نگرانیها در مورد هوش مصنوعی اخلاقی، جانبداری و انصاف منجر به گفتگوهای بیشتر در مورد هوش مصنوعی مسئولانه شد. موضوعاتی مانند توضیحپذیری (XAI) و حاکمیت هوش مصنوعی مورد توجه قرار گرفتند که نشاندهنده تأثیر اجتماعی رو به رشد فناوریهای هوش مصنوعی است.
با این حال، تغییر دهنده واقعی بازی، ظهور مدلهای زبانی بزرگ (LLM) بود. با شروع از BERT و تسریع با راهاندازی GPT-3، جلسات کنفرانس در مورد LLM و ترانسفورماتورها به شدت افزایش یافت. Hugging Face به لطف کتابخانههای در دسترس و مدلهای از پیش آموزشدیده خود، به نامی آشنا در جامعه NLP تبدیل شد.
انفجار هوش مصنوعی مولد و ظهور عوامل هوش مصنوعی (2023–2024)
اگر یک روند وجود داشته باشد که دو سال گذشته را تعریف کرده است، آن هوش مصنوعی مولد است. با ظهور شهابوار مدلهایی مانند ChatGPT، DALL·E و Stable Diffusion، جلسات مربوط به مدلهای مولد منفجر شد. از تولید متن و ترکیب تصویر گرفته تا تولید کد و برنامههای کاربردی خلاقانه هوش مصنوعی، تمرکز به سمت چگونگی ایجاد انقلاب در صنایع توسط این فناوریها تغییر کرد.
مدلهای زبانی بزرگ (LLM)، که زمانی خاص بودند، به مرکز تقریباً هر گفتگوی هوش مصنوعی تبدیل شدند. انتشار GPT-4 و سایر LLMهای پیشرفته، موجی از تحقیقات را در مورد تنظیم دقیق، مهندسی سریع و استفاده از LLMها در برنامههای کاربردی دنیای واقعی برانگیخت. Hugging Face به تسلط بر اکوسیستم NLP ادامه داد و نوآوری مبتنی بر جامعه را تقویت کرد.
دو سال گذشته همچنین شاهد ظهور عوامل هوش مصنوعی به عنوان تغییر دهندگان بازی در روندهای علم داده بود - سیستمهای خودمختار قادر به برنامهریزی، تصمیمگیری و تعامل با محیطها. این عوامل که توسط LLMها و ابزارهایی مانند LangChain و AutoGPT پشتیبانی میشوند، به طور فزایندهای برای گردشهای کاری پیچیده، از رباتهای پشتیبانی مشتری گرفته تا دستیارهای تحقیقاتی مبتنی بر هوش مصنوعی استفاده میشوند. جلسات کنفرانس معماری، نگرانیهای ایمنی و پتانسیل آنها برای اتوماسیون کسبوکار را بررسی کردند.
در همان زمان، نگرانیهای اخلاقی در مورد دیپفیکها، توهمات هوش مصنوعی و مالکیت معنوی منجر به بحثهای موازی در مورد تنظیم هوش مصنوعی و استفاده مسئولانه شد.
ترجیحات چارچوبی نیز تغییر کرد: در حالی که TensorFlow حضور ثابتی را حفظ کرد، PyTorch در سالهای اخیر به دلیل انعطافپذیری و اکوسیستم توسعهدهنده پسند خود، پیشتاز شد.
تکامل چارچوب: از TensorFlow تا LangChain
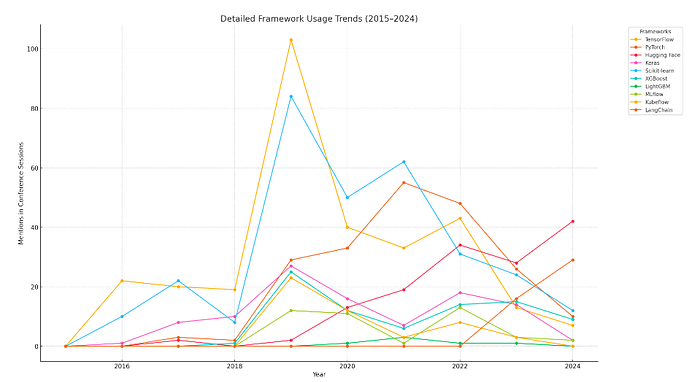
بررسی عمیقتر دادهها تغییرات جالبی را در ترجیحات چارچوبی در طول سالها نشان میدهد:
- TensorFlow بر دوران اولیه یادگیری عمیق (2016–2019) تسلط داشت، اما با گرایش توسعهدهندگان به سمت چارچوبهای انعطافپذیرتر، کاهش تدریجی را شاهد بود.
- PyTorch در حدود سال 2019 به عنوان انتخاب ترجیحی برای محققان ظاهر شد و از آن زمان به چارچوب پیشرو در تحقیق و تولید تبدیل شده است.
- Hugging Face توسعه NLP را با کتابخانه Transformers کاربرپسند خود متحول کرد و به یک عنصر اصلی پس از سال 2020 تبدیل شد.
- چارچوبهای کلاسیک یادگیری ماشین مانند Scikit-learn، XGBoost و LightGBM محبوبیت ثابتی را برای وظایف ML سنتی حفظ کردند.
- رونق MLOps (2020–2021) ابزارهایی مانند MLflow و Kubeflow را معرفی کرد که در این دوره به عناصر اصلی کنفرانس تبدیل شدند.
- LangChain، یک تازهوارد، شاهد پذیرش سریع در عصر عوامل هوش مصنوعی و LLMها بوده است و خطوط لوله پیچیدهای را فعال میکند که LLMها را با دادهها و اقدامات دنیای واقعی مرتبط میکند.
این روندهای علم داده نه تنها منعکس کننده تغییرات در فناوری است، بلکه منعکس کننده نیازهای در حال تحول در جامعه علم داده نیز هست - از تحقیق و نمونهسازی گرفته تا استقرار و اتوماسیون.
آینده علم داده چیست؟
دهه گذشته در علم داده چیزی کمتر از دگرگون کننده نبوده است. روندهای نوظهور در علم داده مانند هوش مصنوعی چندوجهی، محتوای تولید شده توسط هوش مصنوعی، LLMهای شخصیسازی شده و عوامل هوش مصنوعی به این اشاره دارند که این حوزه به کجا میرود.
از آنجایی که هوش مصنوعی در دسترستر میشود و در ابزارهای روزمره ادغام میشود، کنفرانسها احتمالاً به بررسی تعادل بین نوآوری و مسئولیت ادامه خواهند داد. موضوعاتی مانند ایمنی هوش مصنوعی، توضیحپذیری و همکاری انسان و هوش مصنوعی قرار است نقشهای بزرگتری ایفا کنند.
برای دانشمندان داده، پیشتاز ماندن به معنای تسلط بر ابزارهای جدید نیست، بلکه درک اثرات اخلاقی، اجتماعی و اقتصادی فناوریهایی است که میسازند.
سخنان پایانی
کنفرانسها به عنوان بازتابی از ضربان قلب صنعت عمل میکنند و تغییرات در طول دهه گذشته ماهیت پویای علم داده را برجسته میکند. از روزهای اساسی تحلیل دادهها تا دنیای پیچیده هوش مصنوعی مولد و عوامل مستقل، این سفر هم سریع و هم دگرگون کننده بوده است.
همانطور که به آینده نگاه میکنیم، یک چیز واضح است: علم داده به تکامل خود ادامه خواهد داد، که توسط جامعهای که بر اساس کنجکاوی، نوآوری و پیگیری بیامان دانش رشد میکند، هدایت میشود.
بعدی - ODSC East 2025!
ما در حال برنامهریزی برای دهمین سالگرد ODSC East هستیم تا بزرگترین رویداد تا به امروز باشد. ODSC East که در 13 تا 15 می در بوستون و به صورت مجازی برگزار میشود، در حال شکلگیری است تا زمان خوبی باشد. ما در مکان جدیدی در بندر بوستون هستیم، یک مسیر سخنرانی اصلی کامل خواهیم داشت و در حال برنامهریزی جشنهای سرگرمکننده هستیم. شما میتوانید برای ODSC East در اینجا ثبتنام کنید در حالی که بلیطها هنوز تخفیف زیادی دارند و در خبرنامه ما ثبتنام کنید تا تمام بهروزرسانیها را دریافت کنید.