
رفتارهای تعمیم به ظاهر غیرعادی شبکههای عصبی عمیق، برازش بیش از حد خوشخیم، نزول مضاعف، و پارامتربندی بیش از حد موفق، نه منحصر به شبکههای عصبی هستند و نه ذاتاً مرموز. این پدیدهها را میتوان از طریق چارچوبهای تثبیتشده مانند PAC-Bayes و محدودیتهای فرضیه قابل شمارش درک کرد. محققی از دانشگاه نیویورک "سوگیریهای استقرایی نرم" را به عنوان یک اصل متحدکننده کلیدی در توضیح این پدیدهها ارائه میدهد: به جای محدود کردن فضای فرضیه، این رویکرد انعطافپذیری را در بر میگیرد در حالی که ترجیحی را برای راهحلهای سادهتر سازگار با دادهها حفظ میکند. این اصل در سراسر کلاسهای مختلف مدل اعمال میشود و نشان میدهد که یادگیری عمیق اساساً با سایر رویکردها متفاوت نیست. با این حال، یادگیری عمیق در جنبههای خاص متمایز باقی میماند.
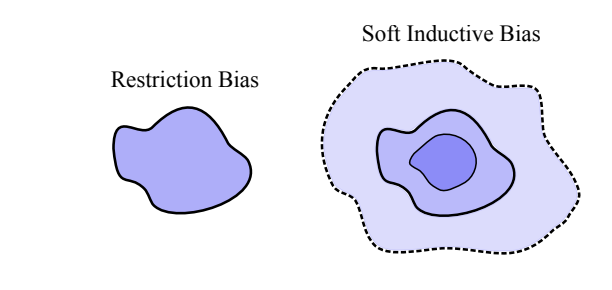
سوگیریهای استقرایی به طور سنتی به عنوان سوگیریهای محدودکننده عمل میکنند که فضای فرضیه را محدود میکنند تا تعمیم را بهبود بخشند و به دادهها اجازه میدهند راهحلهای نامناسب را حذف کنند. شبکههای عصبی کانولوشنال این رویکرد را با اعمال محدودیتهای سخت مانند محلیت و تغییرناپذیری ترجمه بر روی MLPs از طریق حذف و اشتراکگذاری پارامترها نشان میدهند. سوگیریهای استقرایی نرم، اصل گستردهتری را نشان میدهند که در آن راهحلهای خاصی بدون حذف جایگزینهایی که به همان اندازه با دادهها مطابقت دارند، ترجیح داده میشوند. برخلاف سوگیریهای محدودکننده با محدودیتهای سخت خود، سوگیریهای نرم به جای محدود کردن، فضای فرضیه را هدایت میکنند. این سوگیریها از طریق مکانیسمهایی مانند منظمسازی (regularization) و توزیعهای بیزی قبلی بر روی پارامترها بر فرآیند آموزش تأثیر میگذارند.
پذیرش فضاهای فرضیه انعطافپذیر، ساختارهای داده پیچیده دنیای واقعی را دارد، اما برای اطمینان از تعمیم خوب، به سوگیری قبلی نسبت به راهحلهای خاصی نیاز دارد. علیرغم به چالش کشیدن خرد متعارف پیرامون برازش بیش از حد و معیارهایی مانند پیچیدگی رادماخر، پدیدههایی مانند پارامتربندی بیش از حد با درک شهودی از تعمیم همسو هستند. این پدیدهها را میتوان از طریق چارچوبهای دیرینه، از جمله PAC-Bayes و محدودیتهای فرضیه قابل شمارش، توصیف کرد. مفهوم ابعاد موثر، بینش بیشتری را برای درک رفتارها ارائه میدهد. چارچوبهایی که خرد متعارف تعمیم را شکل دادهاند، اغلب نمیتوانند این پدیدهها را توضیح دهند، و ارزش روشهای جایگزین تثبیتشده را برای درک ویژگیهای تعمیم یادگیری ماشین مدرن برجسته میکنند.
برازش بیش از حد خوشخیم، توانایی مدلها را برای برازش کامل نویز در حالی که هنوز به خوبی روی دادههای ساختاریافته تعمیم مییابند، توصیف میکند، و نشان میدهد که ظرفیت برازش بیش از حد لزوماً منجر به تعمیم ضعیف در مسائل معنیدار نمیشود. شبکههای عصبی کانولوشنال میتوانند برچسبهای تصویر تصادفی را برازش کنند در حالی که عملکرد قوی خود را در وظایف تشخیص تصویر ساختاریافته حفظ میکنند. این رفتار با چارچوبهای تعمیم تثبیتشده مانند بعد VC و پیچیدگی رادماخر در تضاد است، و نویسندگان ادعا میکنند که هیچ معیار رسمی موجودی نمیتواند سادگی این مدلها را علیرغم اندازه بسیار زیادشان توضیح دهد. تعریف دیگری برای برازش بیش از حد خوشخیم به عنوان "یکی از رمز و رازهای کلیدی کشف شده توسط یادگیری عمیق" توصیف شده است. با این حال، این منحصر به شبکههای عصبی نیست، زیرا میتوان آن را در کلاسهای مختلف مدل بازتولید کرد.
نزول مضاعف به خطای تعمیم اشاره دارد که با افزایش پارامترهای مدل، کاهش، افزایش و سپس دوباره کاهش مییابد. الگوی اولیه از "رژیم کلاسیک" پیروی میکند که در آن مدلها ساختار مفیدی را به دست میآورند اما در نهایت دچار برازش بیش از حد میشوند. نزول دوم در "رژیم درونیابی مدرن" پس از نزدیک شدن تلفات آموزش به صفر رخ میدهد. نزول مضاعف برای ResNet-18 و یک مدل خطی نشان داده شده است. برای ResNet، تلفات آنتروپی متقاطع در CIFAR-100 با افزایش عرض هر لایه مشاهده میشود. با افزایش عرض لایه در ResNet یا افزایش پارامترها در مدل خطی، هر دو الگوهای مشابهی را دنبال میکنند: ابعاد موثر تا رسیدن به آستانه درونیابی افزایش مییابد، سپس با بهبود تعمیم کاهش مییابد. این پدیده را میتوان به طور رسمی با استفاده از محدودیتهای PAC-Bayes ردیابی کرد.
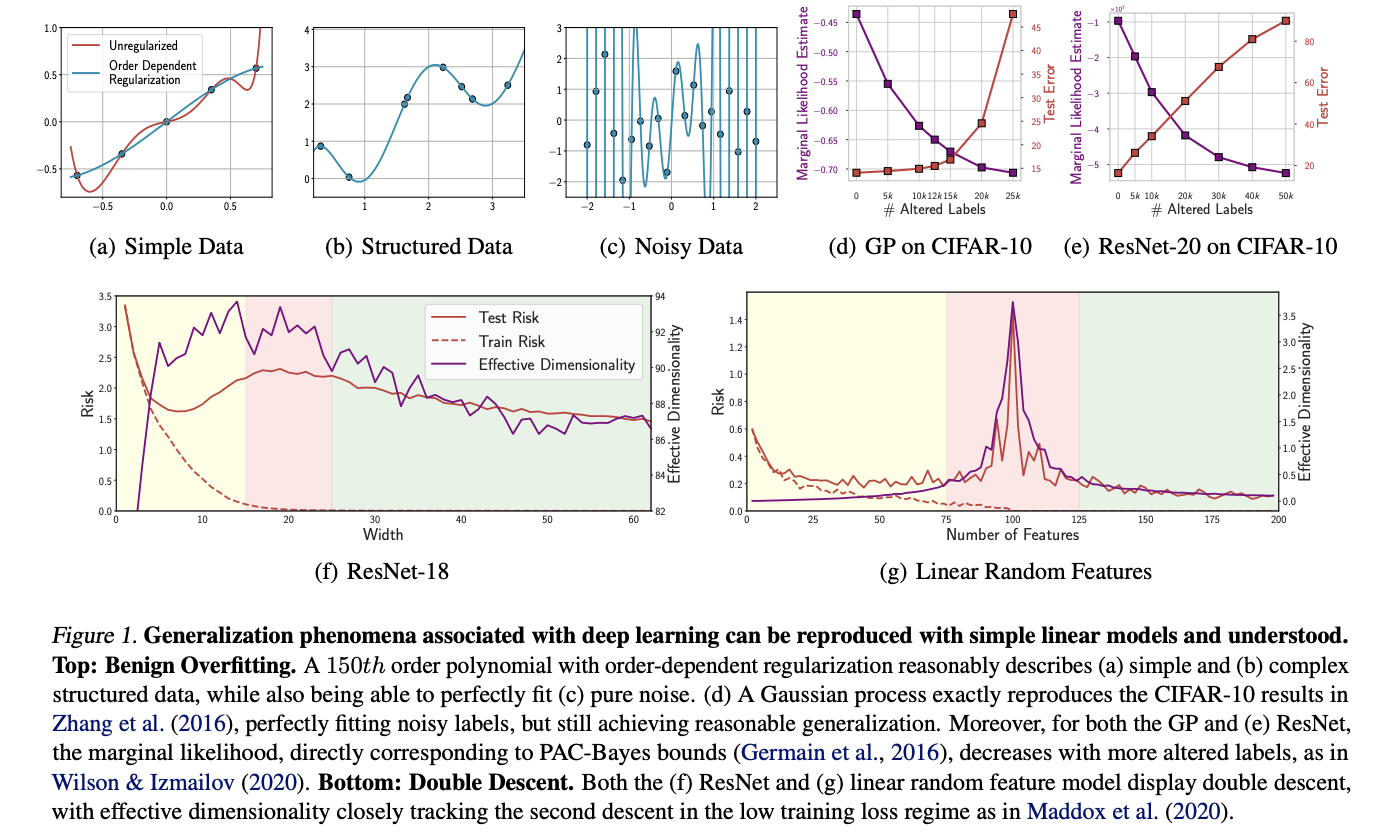
در نتیجه، پارامتربندی بیش از حد، برازش بیش از حد خوشخیم، و نزول مضاعف نشاندهنده پدیدههای جالب توجهی هستند که شایسته مطالعه مداوم هستند. با این حال، برخلاف باورهای گسترده، این رفتارها با چارچوبهای تعمیم تثبیتشده همسو هستند، میتوانند در مدلهای غیرعصبی بازتولید شوند و میتوانند به طور شهودی درک شوند. این درک باید جوامع تحقیقاتی متنوع را به هم متصل کند و از نادیده گرفته شدن دیدگاهها و چارچوبهای ارزشمند جلوگیری کند. سایر پدیدهها مانند گروکینگ (grokking) و قوانین مقیاسبندی به عنوان شواهدی برای تجدید نظر در چارچوبهای تعمیم یا به عنوان پدیدههای خاص شبکههای عصبی ارائه نمیشوند. تحقیقات اخیر تأیید میکند که این پدیدهها در مورد مدلهای خطی نیز صدق میکنند.
مقاله را بررسی کنید: مقاله. تمام اعتبار این تحقیق به محققان این پروژه میرسد. همچنین، با خیال راحت ما را در توییتر دنبال کنید و فراموش نکنید که به SubReddit 80k+ ML ما بپیوندید.