
تولید کد با بازخورد اجرا دشوار است، زیرا خطاها اغلب به اصلاحات متعددی نیاز دارند و رفع آنها به روشی ساختاریافته ساده نیست. آموزش مدلها برای یادگیری از بازخورد اجرا ضروری است، اما رویکردها با چالشهایی روبرو هستند. برخی از روشها سعی میکنند خطاها را در یک مرحله اصلاح کنند، اما در صورت نیاز به اصلاحات متعدد، با شکست مواجه میشوند. برخی دیگر از تکنیکهای یادگیری پیچیده برای بهینهسازی بهبودهای بلندمدت استفاده میکنند. با این حال، این روشها با سیگنالهای یادگیری ضعیف دست و پنجه نرم میکنند و آموزش را کند و ناکارآمد میکنند—نبود یک روش موثر برای رسیدگی به اصلاحات تکراری منجر به یادگیری ناپایدار و عملکرد ضعیف میشود.
در حال حاضر، سیستمهای مبتنی بر درخواست (prompting-based systems) سعی میکنند وظایف چند مرحلهای را با استفاده از خود اشکالزدایی، تولید آزمون و بازتاب حل کنند، اما فقط کمی بهبود مییابند. برخی از روشها مدلهای پاداش مانند CodeRL را برای رفع خطاها و ARCHER را برای تصمیمگیری ساختاریافته آموزش میدهند، در حالی که برخی دیگر از جستجوی درخت مونت کارلو (MCTS) استفاده میکنند، اما به محاسبات بسیار زیادی نیاز دارند. رویکردهای مبتنی بر تأییدکننده، مانند "بیایید گام به گام بررسی کنیم" و AlphaCode، به یافتن اشتباهات یا ایجاد موارد آزمایشی کمک میکنند، اما برخی از مدلها فقط به بررسیهای نحوی تکیه میکنند که برای آموزش مناسب کافی نیستند. محدودیت امتیاز، مراحل آموزش را محدود میکند و RISE از اصلاحات پیچیده استفاده میکند که باعث ناکارآمدی یادگیری میشود. عوامل تنظیمشده دقیق مانند FireAct، LEAP و مدلهای مبتنی بر بازخورد مانند RL4VLM و GLAM سعی در بهبود عملکرد دارند. با این حال، تکنیکهای فعلی یا نمیتوانند کد را به درستی در طول مراحل متعدد اصلاح کنند یا بیش از حد ناپایدار و ناکارآمد هستند.
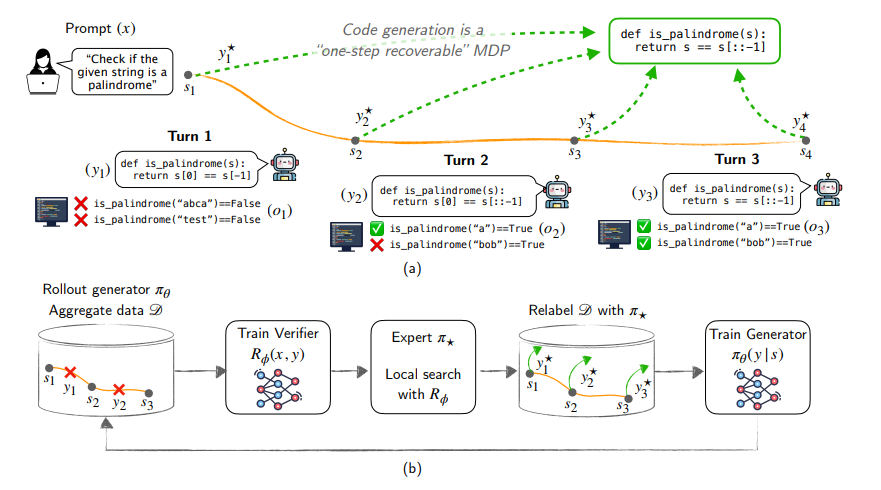
برای کاهش این مشکلات، محققان µCODE را پیشنهاد کردند، یک روش تولید کد چند نوبتی که با استفاده از بازخورد اجرا بهبود مییابد. رویکردهای موجود با چالشهایی در زمینه خطاهای اجرا و پیچیدگی یادگیری تقویتی روبرو هستند، اما µCODE با پیروی از یک چارچوب تکرار خبره با یک خبره جستجوی محلی، بر این مشکلات غلبه میکند. یک تأییدکننده کیفیت کد را ارزیابی میکند، در حالی که یک تولیدکننده از بهترین راه حلها یاد میگیرد و خروجی خود را در طول تکرارهای متعدد اصلاح میکند. در طول استنتاج، یک استراتژی جستجوی بهترین N به تولید و بهبود کد بر اساس نتایج اجرا کمک میکند و عملکرد بهتری را تضمین میکند.
این چارچوب ابتدا یک تأییدکننده را از طریق یادگیری نظارتشده آموزش میدهد تا قطعههای کد را امتیازدهی کند و ارزیابیها را قابل اعتمادتر کند. آنتروپی متقابل باینری صحت را پیشبینی میکند، در حالی که Bradley-Terry راه حلها را برای انتخاب بهتر رتبهبندی میکند. سپس تولیدکننده به طور تکراری با برچسبگذاری مجدد خروجیهای گذشته با راه حلهای انتخابشده توسط خبره، یاد میگیرد و دقت را بهبود میبخشد. راه حلهای متعددی در استنتاج تولید میشوند و تأییدکننده بهترین را انتخاب میکند و خروجیها را تا زمانی که همه آزمایشها قبول شوند، اصلاح میکند. µCODE با در نظر گرفتن تولید کد به عنوان یک مسئله یادگیری تقلیدی، اکتشاف پیچیده را حذف میکند و بهینهسازی کارآمد را ممکن میسازد.
محققان اثربخشی µCODE را با مقایسه آن با روشهای پیشرفته، تجزیه و تحلیل تأثیر تأییدکننده آموختهشده در طول آموزش و استنتاج، و ارزیابی توابع زیان مختلف برای آموزش تأییدکننده، ارزیابی کردند. تولیدکننده با استفاده از مدلهای Llama مقداردهی اولیه شد و آزمایشها روی مجموعههای داده MBPP و HumanEval انجام شد. آموزش بر روی مجموعه آموزش MBPP انجام شد و ارزیابیها بر روی مجموعه آزمون آن و HumanEval انجام شد. مقایسهها شامل خطوط پایه تک نوبتی و چند نوبتی مانند STaR و Multi-STaR بود که در آن تنظیم دقیق بر اساس راه حلهای تولیدشده صحیح بود. عملکرد با استفاده از دقت بهترین N (BoN) اندازهگیری شد و تأییدکننده راه حلهای نامزد را در هر نوبت رتبهبندی میکرد.
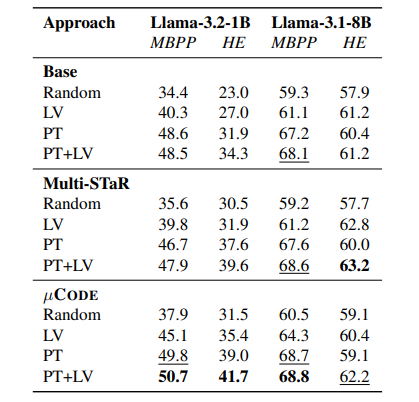
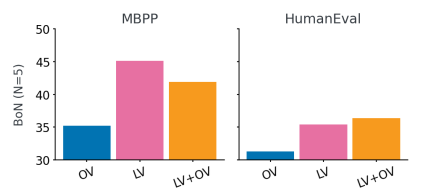
نتایج نشان داد که رویکردهای چند نوبتی عملکرد بهتری نسبت به روشهای تک نوبتی دارند و مزایای بازخورد اجرا را برجسته میکنند. µCODE از Multi-STaR بهتر عمل کرد و با یک مدل 1B، 1.9% بهبود در HumanEval به دست آورد. جستجوی Bon عملکرد را بیشتر افزایش داد و µCODE 12.8% افزایش نسبت به رمزگشایی حریصانه نشان داد. تأییدکننده آموختهشده (LV) نتایج آموزش را بهبود بخشید و به تنهایی از تأییدکنندههای اوراکل (OV) پیشی گرفت. تجزیه و تحلیل بیشتر نشان داد که تأییدکننده آموختهشده به انتخاب راه حلهای بهتر در طول استنتاج، به ویژه در غیاب آزمایشهای عمومی، کمک میکند. مقیاسبندی زمان استنتاج نشان داد که فراتر از تعداد معینی از راه حلهای نامزد، دستاوردهای عملکرد کاهش مییابد. یک استراتژی تأیید سلسله مراتبی (PT+LV) که نتایج آزمون عمومی را با امتیازات تأییدکننده آموختهشده ادغام میکند، بالاترین عملکرد را ارائه داد و اثربخشی تأییدکننده را در حذف راه حلهای نادرست و ایجاد پیشبینیهای تکراری نشان داد.
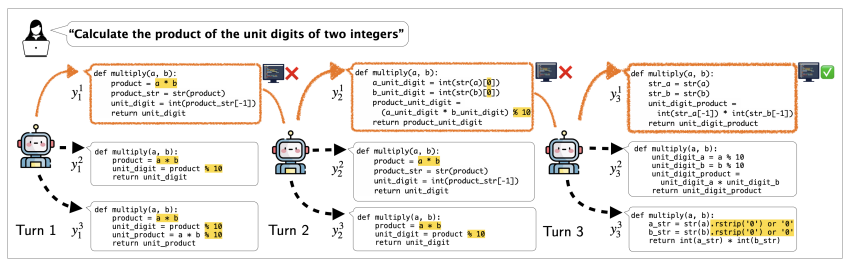
در نتیجه، چارچوب پیشنهادی µCODE یک رویکرد مقیاسپذیر برای تولید کد چند نوبتی با استفاده از پاداشهای تک مرحلهای و یک تأییدکننده آموختهشده برای بهبود تکراری ارائه میدهد. نتایج نشان میدهد که µCODE بهتر از رویکردهای مبتنی بر اوراکل عمل میکند و کد دقیقتری تولید میکند. اگرچه محدود به اندازه مدل، اندازه مجموعه داده و تمرکز پایتون است، اما میتواند یک خط پایه قوی برای کارهای آینده باشد. گسترش دادههای آموزشی، مقیاسبندی به مدلهای بزرگتر و اعمال آن به زبانهای برنامهنویسی متعدد میتواند اثربخشی آن را بیشتر افزایش دهد.
مقاله مقاله و صفحه GitHub را بررسی کنید. تمام اعتبار این تحقیق به محققان این پروژه میرسد. همچنین، در توییتر ما را دنبال کنید و فراموش نکنید که به 80k+ ML SubReddit ما بپیوندید.