

درک ویدیوها با استفاده از هوش مصنوعی نیازمند مدیریت کارآمد توالی تصاویر است. یک چالش بزرگ در مدلهای هوش مصنوعی مبتنی بر ویدیو، ناتوانی آنها در پردازش ویدیوها به عنوان یک جریان پیوسته است که باعث از دست رفتن جزئیات مهم حرکتی و اختلال در پیوستگی میشود. این کمبود مدلسازی زمانی مانع از ردیابی تغییرات میشود؛ بنابراین، رویدادها و تعاملات به طور جزئی ناشناخته میمانند. ویدیوهای طولانی نیز این فرآیند را دشوار میکنند، با هزینههای محاسباتی بالا و نیاز به تکنیکهایی مانند رد کردن فریم، که اطلاعات ارزشمند را از دست میدهد و دقت را کاهش میدهد. همپوشانی بین دادهها در فریمها نیز به خوبی فشرده نمیشود، که منجر به افزونگی و هدر رفتن منابع میشود.
در حال حاضر، مدلهای زبان و تصویر، ویدیوها را به عنوان توالی فریمهای ثابت با رمزگذارهای تصویر و پروژکتورهای زبان و تصویر در نظر میگیرند، که نمایش حرکت و پیوستگی را با چالش مواجه میکند. مدلهای زبانی باید روابط زمانی را به طور مستقل استنباط کنند، که منجر به درک ناقص میشود. نمونهبرداری فرعی از فریمها بار محاسباتی را به قیمت حذف جزئیات مفید کاهش میدهد و بر دقت تأثیر میگذارد. روشهای کاهش توکن مانند فشردهسازی حافظه پنهان KV بازگشتی و انتخاب فریم، پیچیدگی را افزایش میدهند بدون اینکه بهبود زیادی حاصل شود. اگرچه رمزگذارهای ویدیویی پیشرفته و روشهای ادغام به کمک میکنند، اما همچنان ناکارآمد و غیرقابل مقیاس هستند و پردازش ویدیوهای طولانی را از نظر محاسباتی فشرده میکنند.
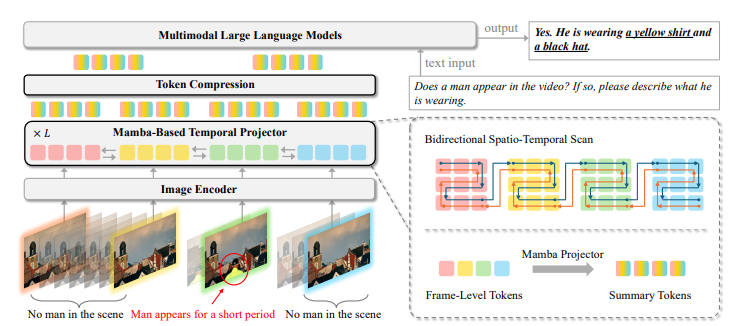
برای رفع این چالشها، محققان NVIDIA، دانشگاه راتگرز، UC Berkeley، MIT، دانشگاه نانجینگ و KAIST، STORM (کاهش توکن فضازمان برای مدلهای زبانی بزرگ چندوجهی) را پیشنهاد کردند، یک معماری پروژکتور زمانی مبتنی بر مامبا (Mamba) برای پردازش کارآمد ویدیوهای طولانی. برخلاف روشهای سنتی، که در آن روابط زمانی به طور جداگانه بر روی هر فریم ویدیویی استنباط میشوند و مدلهای زبانی برای استنباط روابط زمانی مورد استفاده قرار میگیرند، STORM اطلاعات زمانی را در سطح توکنهای ویدیو اضافه میکند تا افزونگی محاسباتی را از بین ببرد و کارایی را افزایش دهد. این مدل نمایشهای ویدیویی را با یک مکانیسم اسکن فضازمان دوطرفه بهبود میبخشد و در عین حال بار استدلال زمانی را از مدل زبانی بزرگ کاهش میدهد.
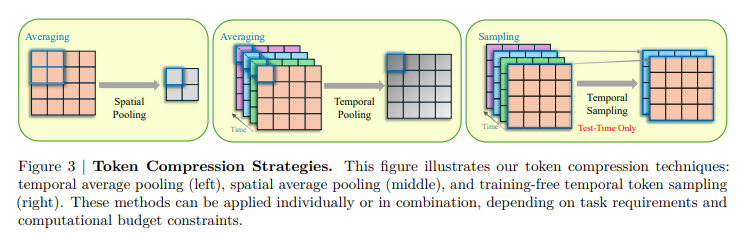
این چارچوب از لایههای مامبا برای تقویت مدلسازی زمانی استفاده میکند، و یک ماژول اسکن دوطرفه را برای گرفتن وابستگیها در ابعاد فضایی و زمانی ترکیب میکند. رمزگذار زمانی ورودیهای تصویر و ویدیو را به طور متفاوتی پردازش میکند، به عنوان یک اسکنر فضایی برای تصاویر برای ادغام زمینه فضایی جهانی و به عنوان یک اسکنر فضازمان برای ویدیوها برای گرفتن پویایی زمانی عمل میکند. در طول آموزش، تکنیکهای فشردهسازی توکن، کارایی محاسباتی را بهبود بخشید و در عین حال اطلاعات ضروری را حفظ کرد، که امکان استنتاج بر روی یک GPU واحد را فراهم کرد. نمونهبرداری فرعی توکن بدون آموزش در زمان آزمایش، بارهای محاسباتی را بیشتر کاهش داد و در عین حال جزئیات زمانی مهم را حفظ کرد. این تکنیک پردازش کارآمد ویدیوهای طولانی را بدون نیاز به تجهیزات تخصصی یا اقتباسهای عمیق تسهیل کرد.
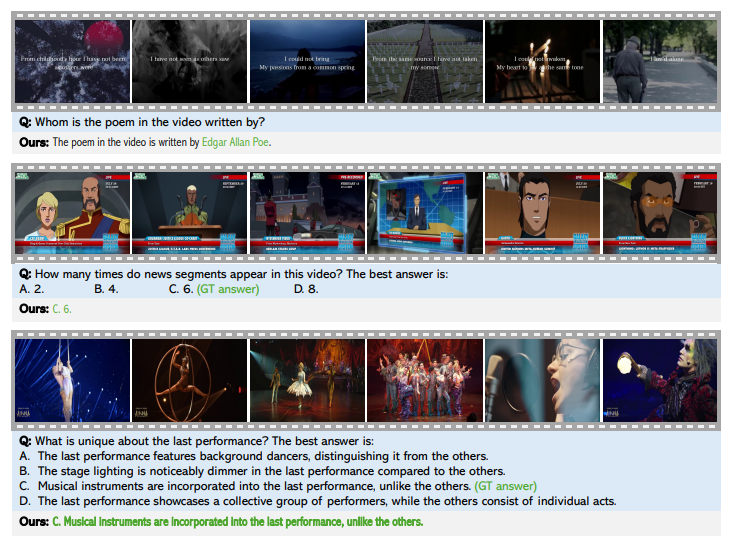
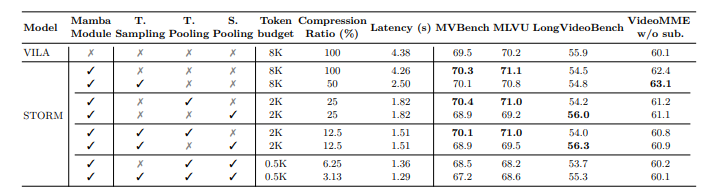
آزمایشهایی برای ارزیابی مدل STORM برای درک ویدیو انجام شد. آموزش با استفاده از مدلهای SigLIP از پیش آموزشدیده انجام شد، با یک پروژکتور زمانی که از طریق مقداردهی اولیه تصادفی معرفی شد. این فرآیند شامل دو مرحله بود: یک مرحله همترازی، که در آن رمزگذار تصویر و مدل زبانی بزرگ ثابت بودند در حالی که فقط پروژکتور زمانی با استفاده از جفتهای تصویر-متن آموزش داده میشد، و یک مرحله تنظیم دقیق نظارتشده (SFT) با یک مجموعه داده متنوع از 12.5 میلیون نمونه، از جمله دادههای متن، تصویر-متن و ویدیو-متن. روشهای فشردهسازی توکن، از جمله ادغام زمانی و فضایی، بار محاسباتی را کاهش داد. آخرین مدل بر روی بنچمارکهای ویدیویی طولانی مانند EgoSchema، MVBench، MLVU، LongVideoBench و VideoMME ارزیابی شد، و عملکرد با سایر مدلهای زبانی بزرگ ویدیویی مقایسه شد.
پس از ارزیابی، STORM از مدلهای موجود بهتر عمل کرد و به نتایج پیشرفتهای در بنچمارکها دست یافت. ماژول مامبا کارایی را با فشردهسازی توکنهای بصری و در عین حال حفظ اطلاعات کلیدی، بهبود بخشید و زمان استنتاج را تا 65.5٪ کاهش داد. ادغام زمانی بهترین عملکرد را در ویدیوهای طولانی داشت و عملکرد را با تعداد کمی توکن بهینه کرد. STORM همچنین عملکرد بسیار بهتری نسبت به مدل پایه VILA، به ویژه در وظایفی که شامل درک زمینه جهانی بود، داشت. نتایج اهمیت مامبا را برای فشردهسازی بهینه توکن تأیید کرد، با افزایش عملکرد همراه با افزایش طول ویدیو از 8 به 128 فریم.
به طور خلاصه، مدل STORM پیشنهادی، درک ویدیوهای طولانی را با استفاده از یک رمزگذار زمانی مبتنی بر مامبا و کاهش کارآمد توکن بهبود بخشید. این مدل فشردهسازی قوی را بدون از دست دادن اطلاعات زمانی کلیدی امکانپذیر کرد، عملکرد پیشرفتهای را در بنچمارکهای ویدیویی طولانی ثبت کرد و در عین حال محاسبات را پایین نگه داشت. این روش میتواند به عنوان یک خط پایه برای تحقیقات آینده عمل کند و نوآوری را در فشردهسازی توکن، همترازی چندوجهی و استقرار در دنیای واقعی برای بهبود دقت و کارایی مدل زبان و تصویر تسهیل کند.