مدلهای استدلال بزرگ (LRM) قبل از رسیدن به یک راه حل، از یک فرایند فکری گام به گام و سنجیده استفاده میکنند، که آنها را برای وظایف پیچیدهای که نیاز به دقت منطقی دارند، مناسب میسازد. برخلاف تکنیکهای قبلی که متکی به استدلال زنجیرهای کوتاه بودند، LRMها مراحل تأیید میانی را ادغام میکنند و اطمینان حاصل میکنند که هر مرحله به طور معناداری به پاسخ نهایی کمک میکند. این رویکرد استدلال ساختاریافته به طور فزایندهای حیاتی است زیرا سیستمهای هوش مصنوعی مسائل پیچیده را در حوزههای مختلف حل میکنند.
یک چالش اساسی در توسعه چنین مدلهایی، آموزش مدلهای زبان بزرگ (LLM) برای اجرای استدلال منطقی بدون تحمیل سربار محاسباتی قابل توجه است. یادگیری تقویتی (RL) به عنوان یک راه حل مناسب ظاهر شده است که به مدلها اجازه میدهد تا تواناییهای استدلال خود را از طریق آموزش تکراری اصلاح کنند. با این حال، رویکردهای سنتی RL به دادههای حاشیهنویسی شده توسط انسان برای تعریف سیگنالهای پاداش متکی هستند و مقیاسپذیری آنها را محدود میکنند. اتکا به حاشیهنویسی دستی تنگناها را ایجاد میکند و کاربرد RL را در مجموعهدادههای بزرگ محدود میکند. محققان استراتژیهای پاداش جایگزینی را بررسی کردهاند که این وابستگی را دور میزند و از روشهای خود نظارتی برای ارزیابی پاسخهای مدل در برابر مجموعههای مسئله از پیش تعریفشده استفاده میکنند.
یک تیم تحقیقاتی از دانشگاه رنمین چین، با همکاری آکادمی هوش مصنوعی پکن (BAAI) و DataCanvas Alaya NeW، یک چارچوب آموزشی مبتنی بر RL را برای بهبود تواناییهای استدلال ساختاریافته LLMها معرفی کرد. مطالعه آنها به طور سیستماتیک اثرات RL بر عملکرد استدلال را بررسی کرد و بر تکنیکهایی که درک و دقت مدل را افزایش میدهند، تمرکز داشت. محققان استدلال مدل را بدون تکیه بر نظارت گسترده انسانی با پیادهسازی مکانیسمهای پاداش ساختاریافته مبتنی بر تأیید حل مسئله، بهینه کردند. رویکرد آنها خروجیهای مدل را اصلاح کرد و انسجام منطقی را در پاسخهای تولید شده تضمین کرد.
چارچوبهای یادگیری موجود برای آموزش LLMها در درجه اول بر یادگیری تقویتی از بازخورد انسانی (RLHF) متمرکز هستند، که در آن مدلها از طریق سیگنالهای پاداش تولید شده توسط انسان یاد میگیرند. با وجود اثربخشی آن، RLHF چالشهای مربوط به هزینههای حاشیهنویسی و محدودیتهای مجموعه داده را ارائه میدهد. محققان مجموعهدادههای قابل تأیید مانند مسائل ریاضی و چالشهای کدنویسی را برای رفع این نگرانیها وارد کردهاند. این مجموعههای مسئله به مدلها اجازه میدهند تا بازخورد مستقیم بر اساس صحت راه حلهای خود دریافت کنند و نیاز به مداخله انسانی را از بین ببرند. این مکانیسم ارزیابی خودکار، آموزش RL کارآمدتر را امکانپذیر کرده و امکانسنجی آن را برای توسعه هوش مصنوعی در مقیاس بزرگ گسترش داده است.

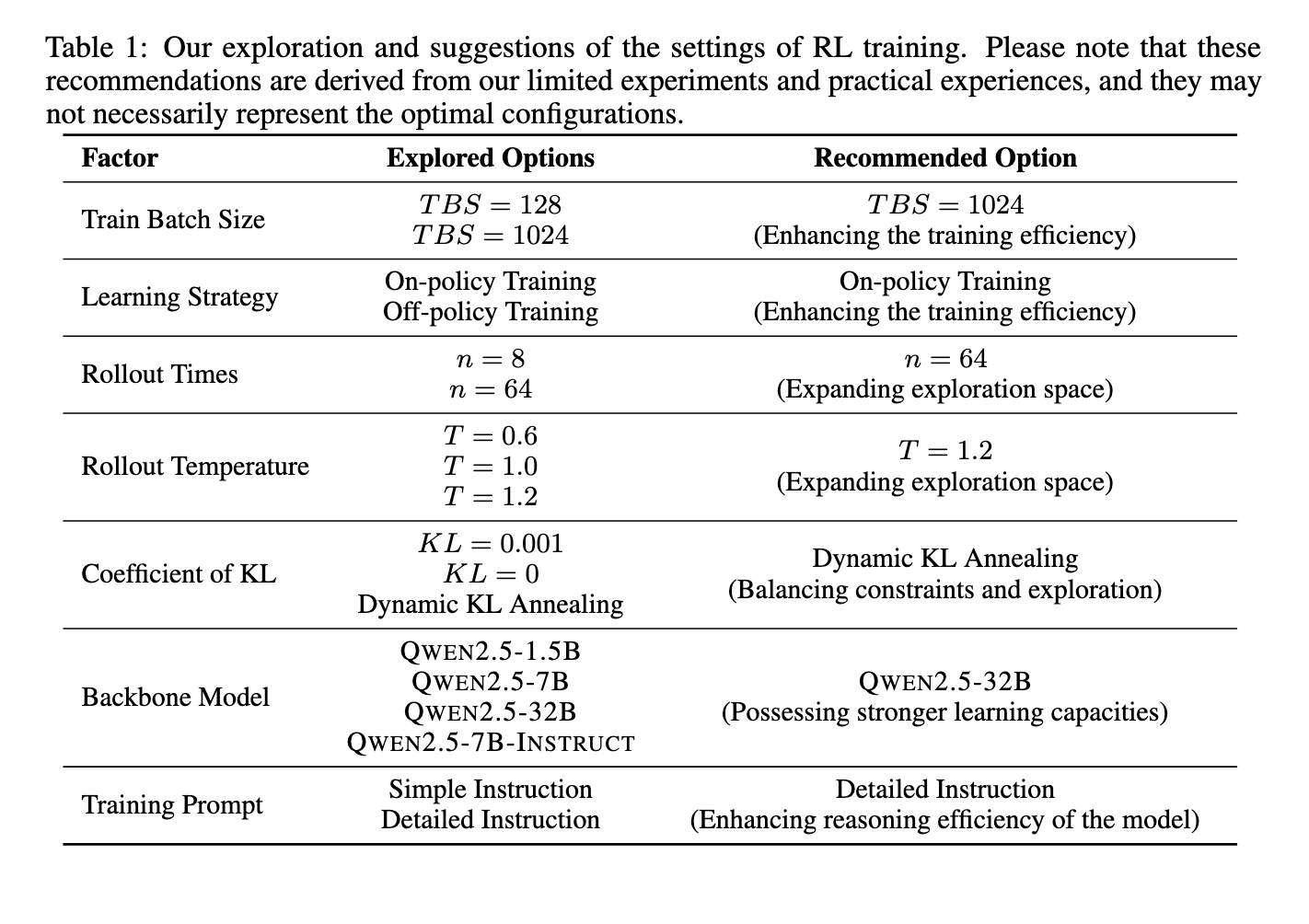
روششناسی شامل تکنیکهای یادگیری تقویتی است که هم برای مدلهای پایه و هم برای مدلهای تنظیمشده اعمال میشود. محققان مدلها را با استفاده از تکنیکهای بهینهسازی سیاست و توابع پاداش ساختاریافته آموزش دادند. پالایش تولید پاسخ از طریق RL مدلها را قادر ساخت تا تواناییهای استدلال پیچیده، از جمله تأیید و خود بازتابی را توسعه دهند. محققان تکنیکهای دستکاری ابزار را برای افزایش بیشتر عملکرد ادغام کردند و به مدلها اجازه دادند تا به طور پویا با سیستمهای خارجی برای حل مسئله تعامل داشته باشند. آزمایشهای آنها نشان داد که RL به طور موثری مدلها را به سمت پاسخهای ساختاریافتهتر هدایت میکند و دقت کلی و کارایی تصمیمگیری را بهبود میبخشد. فرآیند آموزش از مدل QWEN 2.5-32B استفاده کرد که با استفاده از ترکیبی از سیگنالهای پاداش برای بهینهسازی عمق استدلال و کیفیت پاسخ، تنظیم شده بود. محققان همچنین پیکربندیهای مختلف ابرپارامترهای RL را بررسی کردند و تأثیر اندازههای دستهای، زمانهای اجرای آزمایشی و استراتژیهای یادگیری سیاست را بر عملکرد مدل آزمایش کردند. تنظیم این پارامترها از کارایی آموزش بهینه اطمینان حاصل کرد و در عین حال از بهرهبرداری از پاداش، یک چالش رایج در توسعه مدل مبتنی بر RL، جلوگیری کرد.
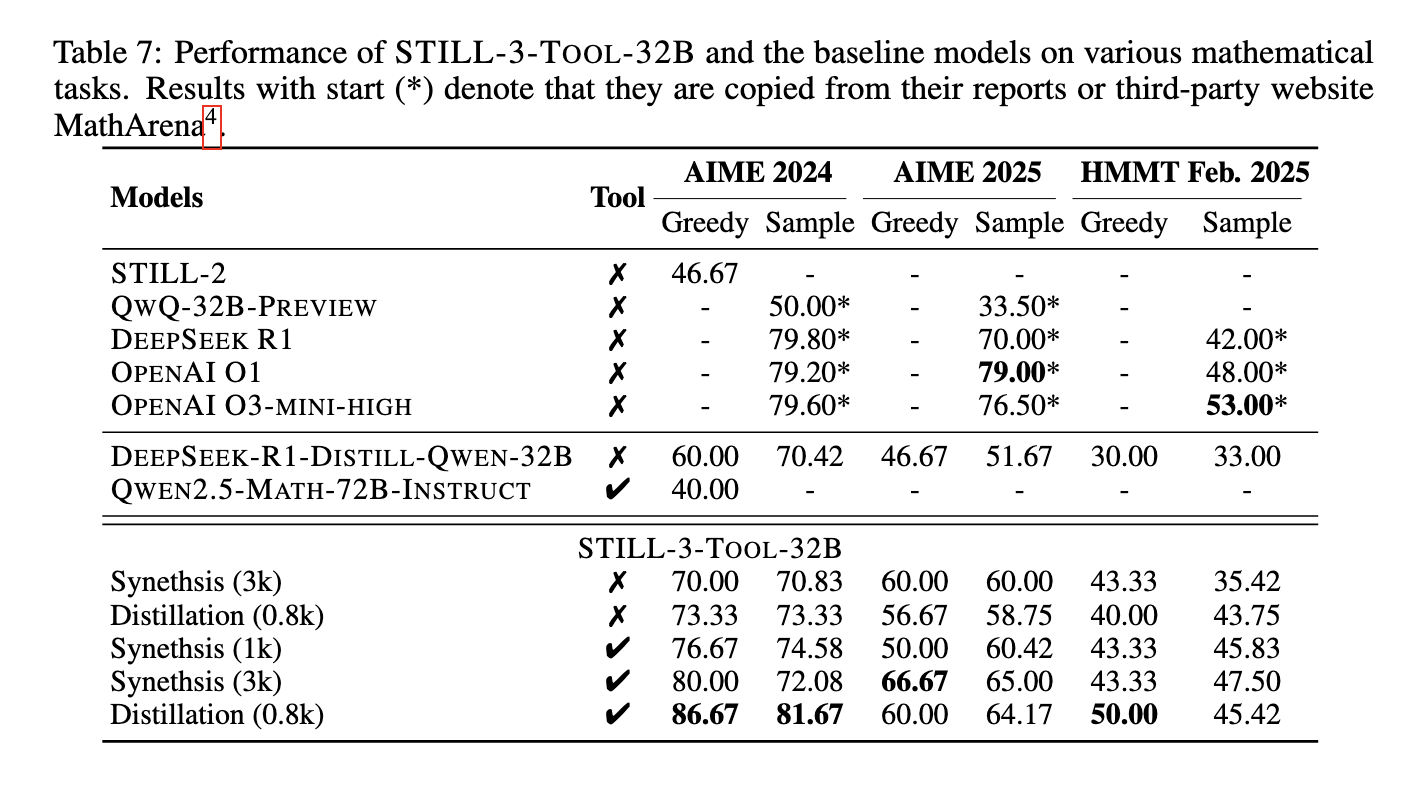
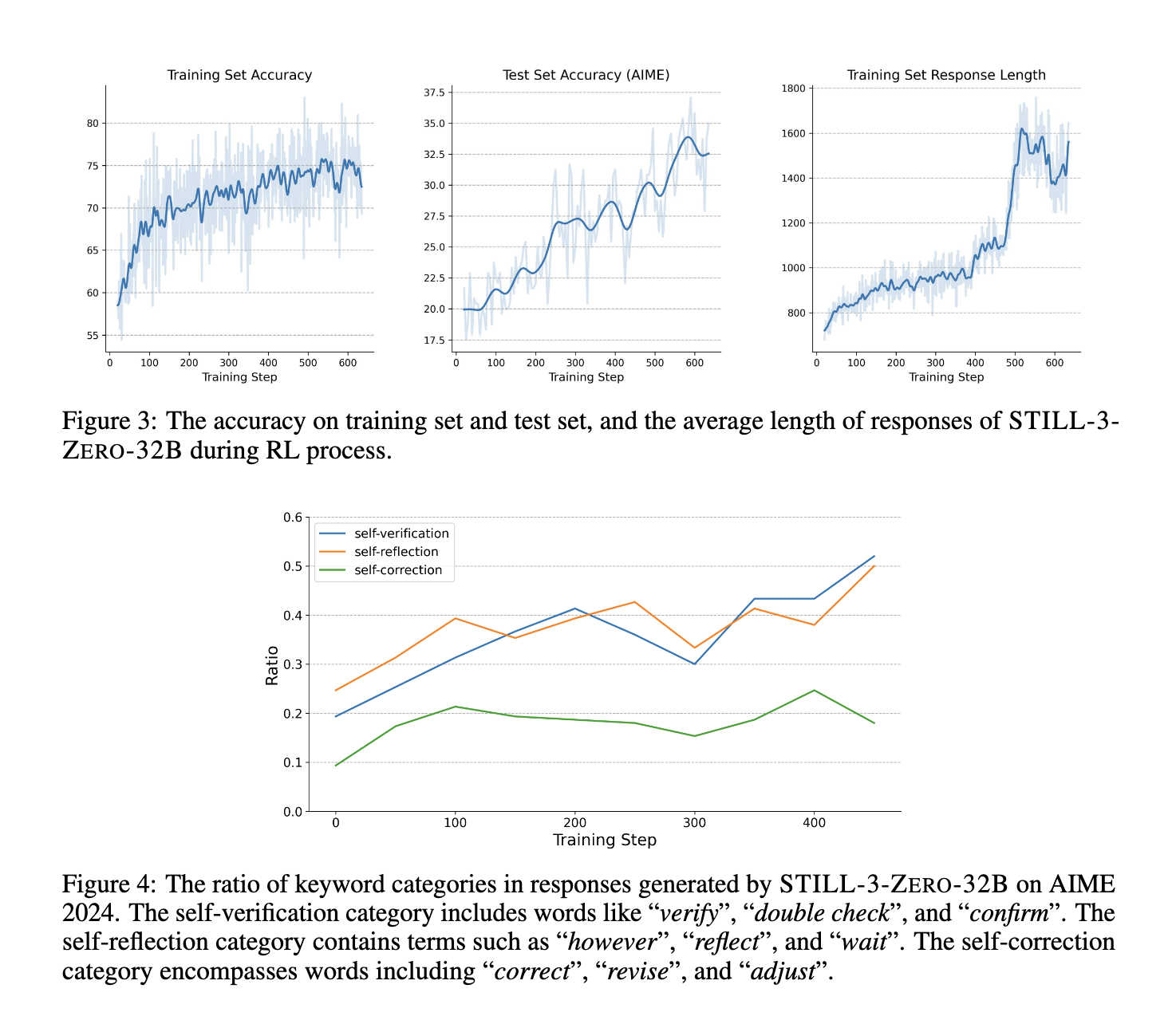
ارزیابیهای عملکرد، بهبودهای قابل توجهی را که از طریق آموزش مبتنی بر RL به دست آمده است، برجسته کرد. مدل QWEN 2.5-32B پس از گذراندن یادگیری تقویتی، تواناییهای استدلال پیشرفتهای را با افزایش طول پاسخ و دقت آزمون بالاتر نشان داد. به طور خاص، این مدل به نرخ دقت 39.33٪ در مجموعه داده AIME 2024 دست یافت و عملکرد پایه خود را به طور قابل توجهی بهبود بخشید. در آزمایشهای بیشتر، تکنیکهای دستکاری ابزار گنجانده شد و منجر به دقت بالاتری حتی 86.67٪ هنگام استفاده از استراتژی جستجوی حریصانه شد. این نتایج بر اثربخشی RL در پالایش قابلیتهای استدلال LLM تأکید میکند و پتانسیل آن را برای کاربرد در وظایف پیچیده حل مسئله برجسته میکند. توانایی مدل در پردازش مراحل استدلال گسترده قبل از رسیدن به یک پاسخ نهایی در دستیابی به این دستاوردهای عملکردی بسیار مهم بود. علاوه بر این، محققان مشاهده کردند که افزایش طول پاسخ به تنهایی لزوماً به عملکرد استدلال بهتر منجر نمیشود. در عوض، ساختاربندی مراحل استدلال میانی در آموزش RL منجر به بهبودهای معناداری در دقت منطقی شد.
این تحقیق نقش مهم یادگیری تقویتی در پیشبرد مدلهای استدلال ساختاریافته را نشان میدهد. محققان با موفقیت توانایی LLMها را برای شرکت در استدلال عمیق و منطقی با ادغام تکنیکهای آموزش RL افزایش دادند. این مطالعه به چالشهای کلیدی در کارایی محاسباتی و مقیاسپذیری آموزش میپردازد و زمینه را برای پیشرفتهای بیشتر در حل مسئله مبتنی بر هوش مصنوعی فراهم میکند. پالایش روشهای RL و بررسی مکانیسمهای پاداش اضافی برای بهینهسازی بیشتر قابلیتهای استدلال LLMها حیاتی خواهد بود.
مقاله را بررسی کنید: مقاله. تمام اعتبار این تحقیق به محققان این پروژه میرسد.