
پیشرفتهای اخیر در یادگیری تقویتی (RL) برای مدلهای زبانی بزرگ (LLM)، مانند DeepSeek R1، نشان دادهاند که حتی وظایف ساده پرسش و پاسخ میتوانند به طور قابل توجهی قابلیتهای استدلال را افزایش دهند. رویکردهای سنتی RL برای LLMها اغلب به وظایف تک نوبتی متکی هستند، جایی که یک مدل بر اساس صحت یک پاسخ پاداش میگیرد. با این حال، این روشها از پاداشهای پراکنده رنج میبرند و نمیتوانند مدلها را برای اصلاح پاسخهای خود بر اساس بازخورد کاربر آموزش دهند. برای رفع این محدودیتها، رویکردهای RL چند نوبتی مورد بررسی قرار گرفتهاند که به LLMها اجازه میدهند تلاشهای متعددی برای حل یک مسئله انجام دهند، در نتیجه تواناییهای استدلال و خود اصلاحی آنها بهبود مییابد.
مطالعات متعددی مکانیسمهای برنامهریزی و خود اصلاحی را در RL برای LLMها بررسی کردهاند. برخی از رویکردها با الهام از الگوریتم Thinker، که به عاملها امکان میدهد قبل از اقدام به بررسی گزینهها بپردازند، استدلال LLM را با دادن اجازه به تلاشهای متعدد به جای یادگیری یک مدل جهانی افزایش میدهند. روشهایی مانند SCoRe، مدلهای LLM را در وظایف چند تلاشی آموزش میدهند، اما فاقد تأیید پاسخهای قبلی با استفاده از پاداشهای مبتنی بر واقعیت هستند که نیاز به کالیبراسیون پیچیده دارد. سایر آثار بر خود اصلاحی با استفاده از ابزارهای خارجی، مانند Reflexion برای خود بازتابی و CRITIC برای بازخورد بیدرنگ، تمرکز دارند. برخلاف این رویکردها، روش پیشنهادی وظیفه پرسش و پاسخ تک نوبتی DeepSeek R1 را به یک چارچوب چند تلاشی گسترش میدهد و از خطاهای تاریخی برای اصلاح پاسخها و افزایش استدلال استفاده میکند.
محققان DualityRL و آزمایشگاه هوش مصنوعی شانگهای، یک رویکرد RL چند تلاشی را برای افزایش استدلال در LLMها معرفی میکنند. برخلاف وظایف تک نوبتی، این روش به مدلها اجازه میدهد تا از طریق تلاشهای متعدد با بازخورد، پاسخها را اصلاح کنند. نتایج تجربی نشان میدهد که با دو تلاش در محکهای ریاضی، دقت 45.6٪ به 52.5٪ افزایش مییابد، در مقایسه با سود اندک در مدلهای تک نوبتی. این مدل خود اصلاحی را با استفاده از بهینهسازی سیاست پروگزیمال (PPO) یاد میگیرد، که منجر به قابلیتهای استدلال نوظهور میشود. این تنظیمات چند تلاشی، اصلاح تکراری را تسهیل میکند، یادگیری عمیقتر و مهارتهای حل مسئله را ترویج میدهد و آن را به یک جایگزین امیدوارکننده برای تکنیکهای متداول RLHF و تنظیم دقیق نظارت شده تبدیل میکند.
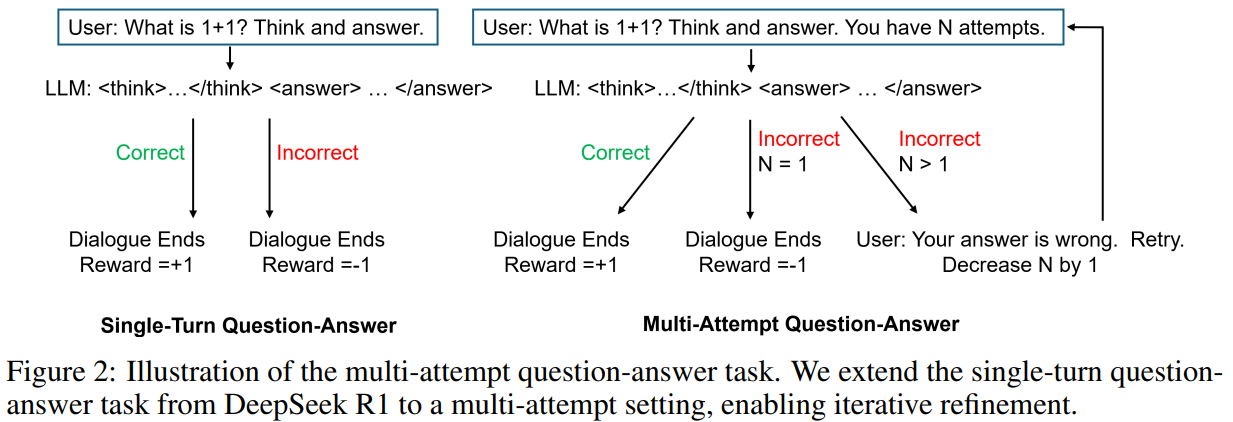
در یک وظیفه تک نوبتی، یک LLM پاسخی را به یک سوال نمونهبرداری شده از یک مجموعه داده تولید میکند و سیاست خود را برای به حداکثر رساندن پاداشها بر اساس صحت پاسخ بهینه میکند. در مقابل، رویکرد چند نوبتی امکان اصلاح تکراری را فراهم میکند، جایی که پاسخها بر اعلانهای بعدی تأثیر میگذارند. وظیفه چند تلاشی پیشنهادی، تعداد ثابتی از تلاشها را معرفی میکند و در صورت نادرست بودن پاسخ اولیه، درخواست بازگشت مجدد میدهد. این مدل برای پاسخهای صحیح +1، برای پاسخهای نادرست اما خوشساختار -0.5 و در غیر این صورت -1 پاداش میگیرد. این رویکرد، کاوش در تلاشهای اولیه را بدون جریمه تشویق میکند و از PPO برای بهینهسازی استفاده میکند و استدلال را از طریق یادگیری تقویتی افزایش میدهد.
این مطالعه، مدل Qwen 2.5 Math 1.5B را بر روی 8 هزار سوال ریاضی با استفاده از PPO با ? = 1، ? = 0.99 و ضریب واگرایی KL 0.01 تنظیم دقیق میکند. آموزش به مدت 160 قسمت ادامه دارد و 1.28 میلیون نمونه تولید میکند. در تنظیمات چند تلاشی، تلاشها از {1، …، 5} نمونهبرداری میشوند، در حالی که خط پایه از یک رویکرد تک نوبتی پیروی میکند. نتایج نشان میدهد که مدل چند تلاشی به پاداشهای بالاتری و دقت ارزیابی کمی بهتری دست مییابد. به ویژه، پاسخها را به طور موثر اصلاح میکند و دقت را از 45.58٪ به 53.82٪ در طول تلاشهای متعدد بهبود میبخشد. این قابلیت استدلال تطبیقی میتواند عملکرد را در زمینههای تولید کد و حل مسئله بهبود بخشد.
در نتیجه، این مطالعه با معرفی یک مکانیسم چند تلاشی، بر وظیفه پرسش و پاسخ DeepSeek R1 بنا شده است. در حالی که دستاوردهای عملکردی در محکهای ریاضی متوسط است، این رویکرد به طور قابل توجهی توانایی مدل را در اصلاح پاسخها بر اساس بازخورد بهبود میبخشد. این مدل که برای تکرار پاسخهای نادرست آموزش داده شده است، کارایی جستجو و خود اصلاحی را افزایش میدهد. نتایج تجربی نشان میدهد که دقت از 45.6٪ به 52.5٪ با دو تلاش بهبود مییابد، در حالی که یک مدل تک نوبتی فقط کمی افزایش مییابد. کار آینده میتواند بیشتر به بررسی گنجاندن بازخورد دقیق یا وظایف کمکی برای افزایش قابلیتهای LLM بپردازد و این رویکرد را برای استدلال تطبیقی و وظایف پیچیده حل مسئله ارزشمند کند.
مقاله را بررسی کنید: مقاله