
یادداشت ویراستار: دیوید فونتهنن سخنرانی در ODSC East 2025 از ۱۳ تا ۱۵ مه خواهد داشت. حتماً سخنرانی او با عنوان "سیستمهای انطباقی RAG با نمودارهای دانش: ساخت برنامههای کاربردی هوش مصنوعی مبتنی بر یادگیری تقویتی" را در آنجا بررسی کنید!
تصور کنید یک دستیار هوش مصنوعی دارید که فقط به سوالات شما پاسخ نمیدهد - بلکه زمینه عمیقتر را درک میکند، در زمان واقعی سازگار میشود و به طور مداوم از تعاملات یاد میگیرد. آینده هوش مصنوعی فقط در مورد مدلهای هوشمندتر نیست، بلکه در مورد سیستمهای هوشمندتری است که به طور یکپارچه زمینه، حافظه و دانش دنیای واقعی را ادغام میکنند. من بسیار هیجانزده هستم که به اشتراک بگذارم که این دیدگاه دقیقاً همان چیزی است که ما در کارگاه آینده خود در ODSC East، "سیستمهای انطباقی RAG با نمودارهای دانش: ساخت برنامههای کاربردی هوش مصنوعی مبتنی بر یادگیری تقویتی" بررسی خواهیم کرد.
تکامل عوامل RAG - مرز جدیدی در هوش مصنوعی
تولید افزوده شده با بازیابی (RAG) نشاندهنده یک تکامل مهم در هوش مصنوعی است که مدلهای زبانی بزرگ (LLM) را با منابع دانش خارجی ترکیب میکند تا پاسخهای دقیق، مرتبط و به موقع تولید کند. مدلهای زبانی سنتی، علیرغم قابلیتهای چشمگیرشان، اغلب پاسخهایی را بر اساس الگوهایی که در طول آموزش آموختهاند، تولید میکنند، که ممکن است منجر به اطلاعات قدیمی یا نادرست شود. سیستمهای انطباقی RAG این محدودیت را با بازیابی پویای دانش خارجی برای اطلاعرسانی به پاسخهای خود برطرف میکنند و آنها را قادر میسازند تا با دقت و ارتباط بیشتری به سؤالات پاسخ دهند.

معرفی بازیابی دانش خارجی اساساً امکانات برنامههای کاربردی هوش مصنوعی مکالمهای را گسترش میدهد. از پشتیبانی مشتری و دستیارهای مجازی گرفته تا تشخیص پزشکی و مشاوره حقوقی، عوامل RAG میتوانند اطلاعات دقیق و قابل اعتماد را در صورت تقاضا ارائه دهند. این ترکیب نوآورانه همچنین مسائل رایجی مانند "توهم" را کاهش میدهد، جایی که مدلها اطلاعات معقول اما نادرست تولید میکنند، با استناد به پاسخها به طور محکم در منابع تأیید شده خارجی.
نمودارهای دانش و پرس و جو - توانمندسازی پاسخهای هوشمند
نمودارهای دانش به دلیل توانایی خود در سازماندهی دادهها در ساختارهای به هم پیوسته، به یک فناوری اساسی در سیستمهای هوش مصنوعی مدرن تبدیل شدهاند. برخلاف پایگاههای داده سنتی، نمودارهای دانش به صراحت روابط بین موجودیتها را نشان میدهند و امکان پرس و جوی دادهها را به طور بسیار کارآمد و شهودی فراهم میکنند. با استفاده از پرس و جوهای ساختاریافته، نمودارهای دانش عوامل RAG را قادر میسازند تا دقیقاً به اطلاعات مورد نیاز دسترسی داشته باشند و پاسخهای عامل را با دقت واقعی و جزئیات حساس به زمینه غنی کنند.
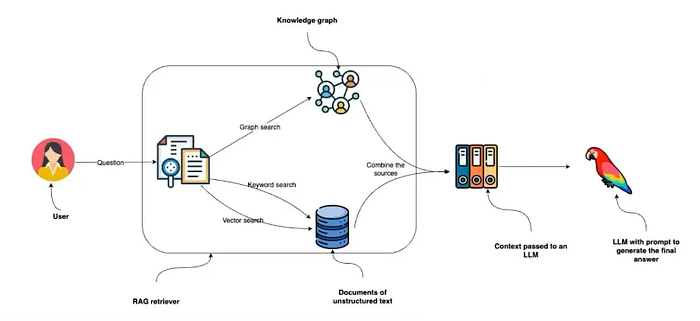
در عمل، پرس و جو از یک نمودار دانش شامل پیمایش روابط بین موجودیتها برای یافتن بینشهای مرتبط است. به عنوان مثال، سوال در مورد یک فیلم میتواند منجر به بازیابی جزئیات مربوط به کارگردان، بازیگران، سال انتشار و حتی فیلمهای مرتبط شود. این رویکرد ساختاریافته و مبتنی بر رابطه، قابلیتهای استدلال قدرتمندی را تسهیل میکند و به عوامل RAG اجازه میدهد تا سوالات پیچیده و چند مرحلهای را که جستجوهای سنتی مبتنی بر کلمات کلیدی با آن دست و پنجه نرم میکنند، مدیریت کنند. در کارگاه ما، شرکتکنندگان از نزدیک تجربه خواهند کرد که چگونه ادغام نمودارهای دانش میتواند تعاملات هوش مصنوعی را افزایش دهد و در نتیجه پاسخهایی نه تنها دقیق، بلکه به طور پویا متناسب با سوالات کاربر باشد.
آغازگر کارگاه: ایجاد یک عامل RAG نمودار دانش
در زیر یک راهنمای سریع برای ساخت یک عامل تولید افزوده شده با بازیابی (RAG) ساده که توسط Neo4j پشتیبانی میشود، و پس از آن نحوه پرس و جو از آن آمده است. اسکریپت اول دادههای متنی را دریافت میکند، آنها را به قطعات تقسیم میکند، جاسازی ایجاد میکند و آنها را در Neo4j مینویسد. اسکریپت دوم نشان میدهد که چگونه این جاسازیها را با یک LLM برای پرسش و پاسخ مبتنی بر RAG پرس و جو کنید.
نکته مهم: کد زیر حاوی یک رویکرد ساده و سادهلوحانه است! شما باید اطلاعات بیشتری در مورد مجموعه داده خود داشته باشید تا بتوانید آن را به درستی دریافت کنید! این فقط برای اهداف نمایشی است!
دریافت و جاسازی دادهها در یک پایگاه داده گراف
از کد زیر برای بارگیری فایلهای txt، تقسیم آنها به قطعات، ایجاد جاسازی و ذخیره نتایج در Neo4j استفاده کنید:
import os
import glob
from typing import List
# Neo4j driver
from neo4j import GraphDatabase
# LangChain imports
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings # or another embedding class
from langchain.vectorstores import Neo4jVector
# ----------------------------------
# Configuration
# ----------------------------------
# Feel free to replace these with environment variables or config files
NEO4J_URI = os.getenv("NEO4J_URI", "neo4j://localhost:7687")
NEO4J_USER = os.getenv("NEO4J_USER", "neo4j")
NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD", "password")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
# The local folder containing your text files (subset of 20 Newsgroups)
DATA_FOLDER = "path/to/20newsgroups_subset"
# Name of the vector index in Neo4j
INDEX_NAME = "my_rag_index"
def load_text_files(folder_path: str) -> List[Document]:
"""
Loads all .txt files in the given folder, splitting them into smaller chunks.
Returns a list of LangChain Document objects.
"""
txt_files = glob.glob(os.path.join(folder_path, "*.txt"))
documents = []
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100
)
for file_path in txt_files:
with open(file_path, "r", encoding="utf-8", errors="ignore") as f:
raw_text = f.read()
# Split into smaller chunks
splits = text_splitter.split_text(raw_text)
# Create Document objects (with optional metadata)
for chunk in splits:
doc = Document(
page_content=chunk,
metadata={"source": file_path} # e.g., store the file name
)
documents.append(doc)
return documents
def store_embeddings_in_neo4j(documents: List[Document]):
"""
Takes a list of Documents, generates embeddings via LangChain,
and stores them in Neo4j using Neo4jVector.
"""
# Initialize embeddings
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# Build the vector store directly from the documents
# This will create the necessary nodes and relationships in Neo4j
# and store the vector embeddings.
vectorstore = Neo4jVector.from_documents(
documents,
embedding=embeddings,
url=NEO4J_URI,
username=NEO4J_USER,
password=NEO4J_PASSWORD,
index_name=INDEX_NAME
)
print(f"Embeddings stored in Neo4j under index name: {INDEX_NAME}")
def main():
# 1. Connect to Neo4j (just as a test—optional if you only rely on from_documents())
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))
print("Testing Neo4j connection...")
with driver.session() as session:
result = session.run("RETURN 1 AS test")
print("Neo4j connection OK? ", bool(result.single()))
# 2. Load and chunk text data
print("Loading text files from folder:", DATA_FOLDER)
documents = load_text_files(DATA_FOLDER)
print(f"Loaded {len(documents)} chunks from the text files.")
# 3. Store embeddings in Neo4j
print("Storing embeddings to Neo4j...")
store_embeddings_in_neo4j(documents)
# Cleanup
driver.close()
print("Done.")
if __name__ == "__main__":
main()
پرس و جو از عامل RAG
پس از جاسازی و ذخیره دادههای خود در Neo4j، از این اسکریپت دوم برای پرس و جو از پایگاه داده از طریق زنجیره RetrievalQA استفاده کنید:
import os
from neo4j import GraphDatabase
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Neo4jVector
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# --------------------------------------
# Configuration
# --------------------------------------
NEO4J_URI = os.getenv("NEO4J_URI", "neo4j://localhost:7687")
NEO4J_USER = os.getenv("NEO4J_USER", "neo4j")
NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD", "password")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY") # or your chosen LLM provider
def main():
# 1) Connect to Neo4j
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))
print("Connected to Neo4j.")
# 2) Initialize Embeddings & LLM
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
llm = OpenAI(openai_api_key=OPENAI_API_KEY, temperature=0)
# 3) Load Vector Store
vectorstore = Neo4jVector(
url=NEO4J_URI,
username=NEO4J_USER,
password=NEO4J_PASSWORD,
embedding=embeddings,
index_name="my_rag_index", # The name of your index in Neo4j
)
# 4) Create a RetrievalQA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 3})
)
# 5) Query the RAG Agent
user_query = "How do I troubleshoot a Python package installation error?"
response = qa_chain.run(user_query)
# 6) Print the Answer
print("User query:", user_query)
print("RAG agent response:", response)
# Cleanup
driver.close()
if __name__ == "__main__":
main()
تمام اینها - فقط محتوای خود را جاسازی کنید، آن را در Neo4j ذخیره کنید و از طریق فروشگاه برداری با استفاده از LangChain پرس و جو کنید. این گردش کار سریع به شما امکان میدهد یک پایگاه دانش قدرتمند و مقیاسپذیر برای هر برنامه کاربردی مبتنی بر LLM حفظ کنید.
تیزر در مورد تقویت و حافظه کوتاه مدت
ساخت یک سیستم واقعاً انطباقی نیاز به چیزی بیش از بازیابی دانش دارد. در کارگاه ما، بررسی خواهیم کرد که چگونه گنجاندن بازخورد انسانی (یادگیری تقویتی) به پالایش پاسخها در زمان واقعی کمک میکند و اطمینان میدهد که عامل RAG شما هم دقیق و هم در حال تکامل باقی میماند. علاوه بر این، ما نشان خواهیم داد که چگونه میتوان به طرز هوشمندانهای از حافظه کوتاه مدت برای تصمیمگیری در مورد اینکه آیا اطلاعات جدید باید دور ریخته شوند یا در دانش بلندمدت جاسازی شوند - و در نتیجه سیستمی ایجاد میشود که با هر تعامل هوشمندتر میشود.
به ما بپیوندید تا تکنیکهای عملی برای مهار حافظه کوتاه مدت، استفاده از تقویت و جمع کردن بینشهای کلیدی در جاسازیهای عامل خود را بیاموزید. نتیجه: تجربیات قویتر و آگاهانهتر از زمینه.
تجربه کارگاه و پیش نیازها
کارگاه آینده ما عملی است و به منظور ارائه تجربه دنیای واقعی به شرکتکنندگان در ساخت عوامل RAG انطباقی با استفاده از پایگاههای داده گراف و LLM های متنباز طراحی شده است. شرکتکنندگان همچنین با یادگیری تقویتی از طریق بازخورد انسانی آزمایش خواهند کرد و مستقیماً مشاهده میکنند که چگونه بازخورد میتواند عملکرد هوش مصنوعی را در زمان واقعی افزایش دهد.
برای استفاده حداکثری از این جلسه تعاملی، شرکتکنندگان باید اطمینان حاصل کنند که:
- یک لپتاپ توسعهدهنده مبتنی بر لینوکس یا مک دارند
- کاربران ویندوز باید از یک ماشین مجازی یا نمونه ابری استفاده کنند
- پایتون نصب شده: نسخه 3.10 یا بالاتر
- (توصیه میشود) استفاده از یک محیط مجازی miniconda یا venv
- Docker (لینوکس یا MacOS) نصب شده: برای اجرای یک نمونه محلی Neo4j
- آشنایی اولیه با عملیات پوسته
چه یک مهندس نرمافزار متوسط باشید و چه یک دانشمند داده با پیشینه عمومی هوش مصنوعی/ML، این کارگاه به گونهای ساختار یافته است که مهارتهای شما را تقویت کرده و دانش عملی شما را عمیقتر کند.
با عوامل RAG عمیقتر کاوش کنید - در این کارگاه شرکت کنید
این فرصت را از دست ندهید تا لبه برش هوش مصنوعی انطباقی را بررسی کنید. شما نه تنها در مورد ادغام هیجانانگیز نمودارهای دانش، حافظه کوتاه مدت و یادگیری تقویتی اطلاعات کسب خواهید کرد، بلکه به طور فعال یک عامل RAG انطباقی را خودتان میسازید و اصلاح میکنید.

تقویمهای خود را (به طور آزمایشی) برای چهارشنبه، ۱۴ مه به عنوان تاریخ کارگاه علامتگذاری کنید و در انقلابی کردن نحوه یادگیری، تعامل و انطباق هوش مصنوعی به ما بپیوندید. شما را آنجا میبینیم!
درباره نویسنده سیستمهای انطباقی RAG: دیوید فونتهنن

دیوید مهندس ارشد هوش مصنوعی/ML در DigitalOcean است، جایی که او به توانمندسازی توسعهدهندگان برای ساخت، مقیاسبندی و استقرار مدلهای هوش مصنوعی/ML در تولید اختصاص دارد. او تخصص عمیقی در ساخت و آموزش مدلها برای برنامههای کاربردی مانند NLP، تجسم دادهها و تجزیه و تحلیل بلادرنگ دارد. او قصد دارد به کاربران کمک کند تا مدلهای هوش مصنوعی را به طور کارآمد بسازند، آموزش دهند و مستقر کنند و یادگیری ماشین پیشرفته را برای افراد در تمام سطوح در دسترس قرار دهند.
لینکدین: https://www.linkedin.com/in/davidvonthenen
گیتهاب: https://github.com/davidvonthenen
یوتیوب: https://www.youtube.com/@davidvonthenen
وبلاگ: https://davidvonthenen.com/