پرامپتینگ زنجیره تفکر (CoT) به مدلهای زبانی بزرگ (LLM) این امکان را میدهد که استنتاجهای منطقی گامبهگام را به زبان طبیعی انجام دهند. اگرچه این روش مؤثر بوده است، اما زبان طبیعی ممکن است کارآمدترین واسط برای استدلال نباشد. مطالعات نشان میدهند که استدلال ریاضی انسان عمدتاً به پردازش زبان متکی نیست و این نشان میدهد که رویکردهای جایگزین میتوانند عملکرد را بهبود بخشند. پژوهشگران قصد دارند نحوه پردازش استدلال توسط LLMها را اصلاح کنند و تعادلی بین دقت و کارایی محاسباتی ایجاد کنند.
چالش استدلال در LLMها ناشی از اتکای آنها به CoT صریح است که نیازمند تولید توضیحات مفصل قبل از رسیدن به پاسخ نهایی است. این رویکرد سربار محاسباتی را افزایش میدهد و استنتاج را کند میکند. روشهای CoT ضمنی تلاش میکنند تا استدلال را بدون تولید توکنهای استدلال صریح، درونیسازی کنند، اما این روشها در مقایسه با CoT صریح، عملکرد ضعیفتری داشتهاند. یک مانع بزرگ در طراحی مدلهایی نهفته است که بتوانند استدلال را به طور کارآمد در داخل پردازش کنند و در عین حال دقت را حفظ کنند. راه حلی که بار محاسباتی بیش از حد را بدون کاهش عملکرد حذف کند، برای افزایش قابلیتهای استدلال در LLMها حیاتی است.
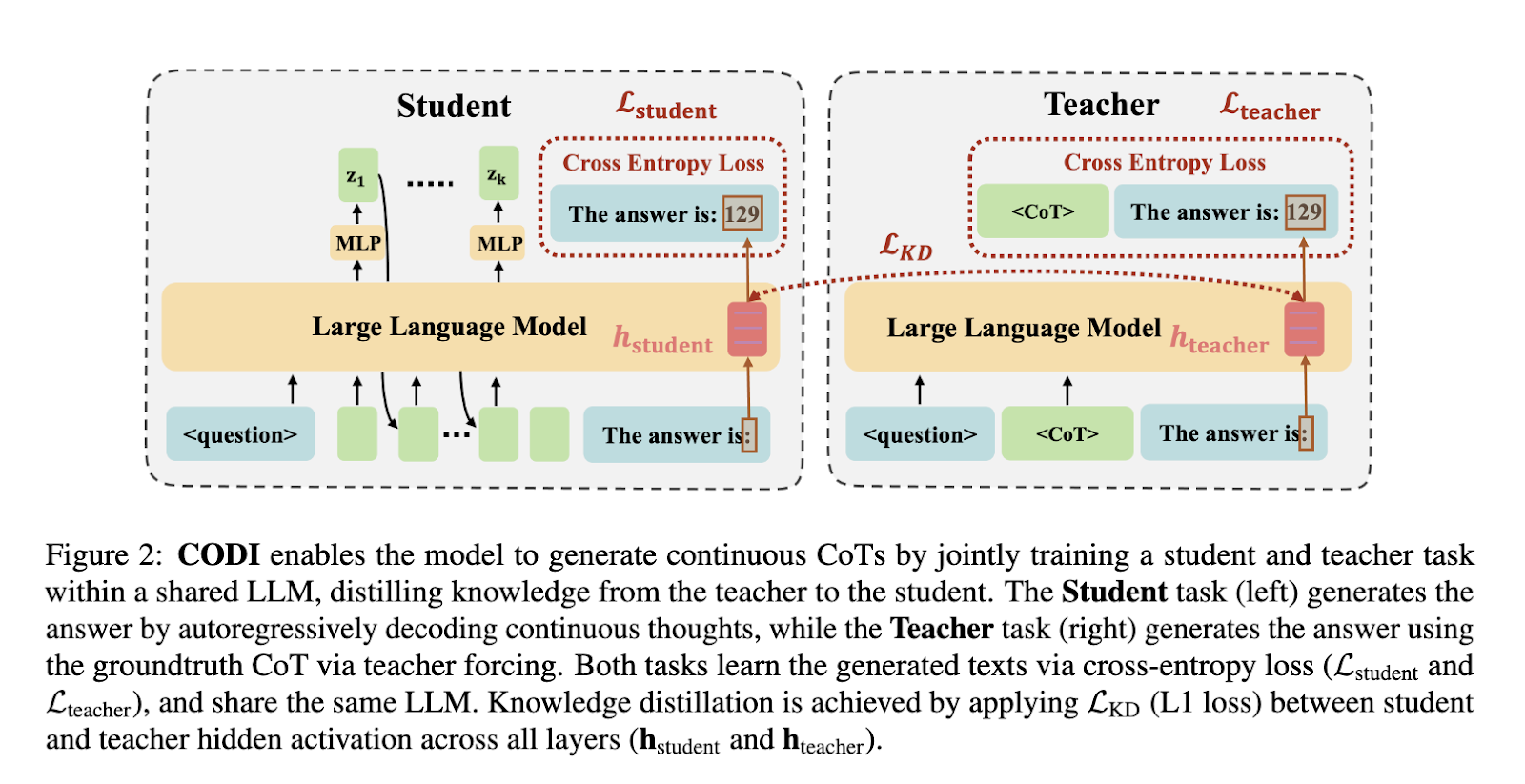
پژوهشگران کالج کینگ لندن و موسسه آلن تورینگ، CODI (زنجیره پیوسته تفکر از طریق خود-تقطیری) را به عنوان یک چارچوب جدید برای رفع این محدودیتها معرفی کردند. CODI استدلال صریح CoT را به یک فضای پیوسته تقطیر میکند و به LLMها اجازه میدهد تا استنتاجهای منطقی را به صورت داخلی و بدون تولید توکنهای صریح CoT انجام دهند. این روش از خود-تقطیری استفاده میکند، جایی که یک مدل واحد هم به عنوان معلم و هم به عنوان دانشآموز عمل میکند و فعالسازیهای پنهان خود را برای رمزگذاری استدلال در یک فضای پنهان فشرده همتراز میکند. CODI با بهرهگیری از این تکنیک، به طور موثر استدلال را بدون کاهش عملکرد فشرده میکند.
CODI از دو وظیفه یادگیری کلیدی تشکیل شده است: تولید CoT صریح و استدلال CoT پیوسته. مدل معلم با پردازش گام به گام استدلال زبان طبیعی و تولید دنباله های CoT صریح، از یادگیری استاندارد CoT پیروی می کند. در مقابل، مدل دانش آموز یاد می گیرد که استدلال را در یک بازنمایی نهفته فشرده درونی کند. برای اطمینان از انتقال دانش مناسب، CODI با استفاده از یک تابع زیان فاصله L1، هم ترازی بین این دو فرآیند را اعمال می کند. برخلاف رویکردهای قبلی، CODI مستقیماً نظارت استدلال را به حالتهای پنهان مدل تزریق میکند و امکان آموزش کارآمدتر را فراهم میکند. به جای تکیه بر چندین مرحله آموزشی، CODI از یک رویکرد تقطیر تک مرحلهای استفاده میکند و تضمین میکند که مسائل مربوط به از دست دادن اطلاعات و فراموشی ذاتی در یادگیری برنامهریزی درسی به حداقل میرسد. این فرآیند شامل انتخاب یک توکن پنهان خاص است که اطلاعات استدلالی حیاتی را رمزگذاری میکند و این امکان را فراهم می آورد تا مدل بتواند به طور موثر مراحل استدلال پیوسته را بدون توکن های صریح تولید کند.
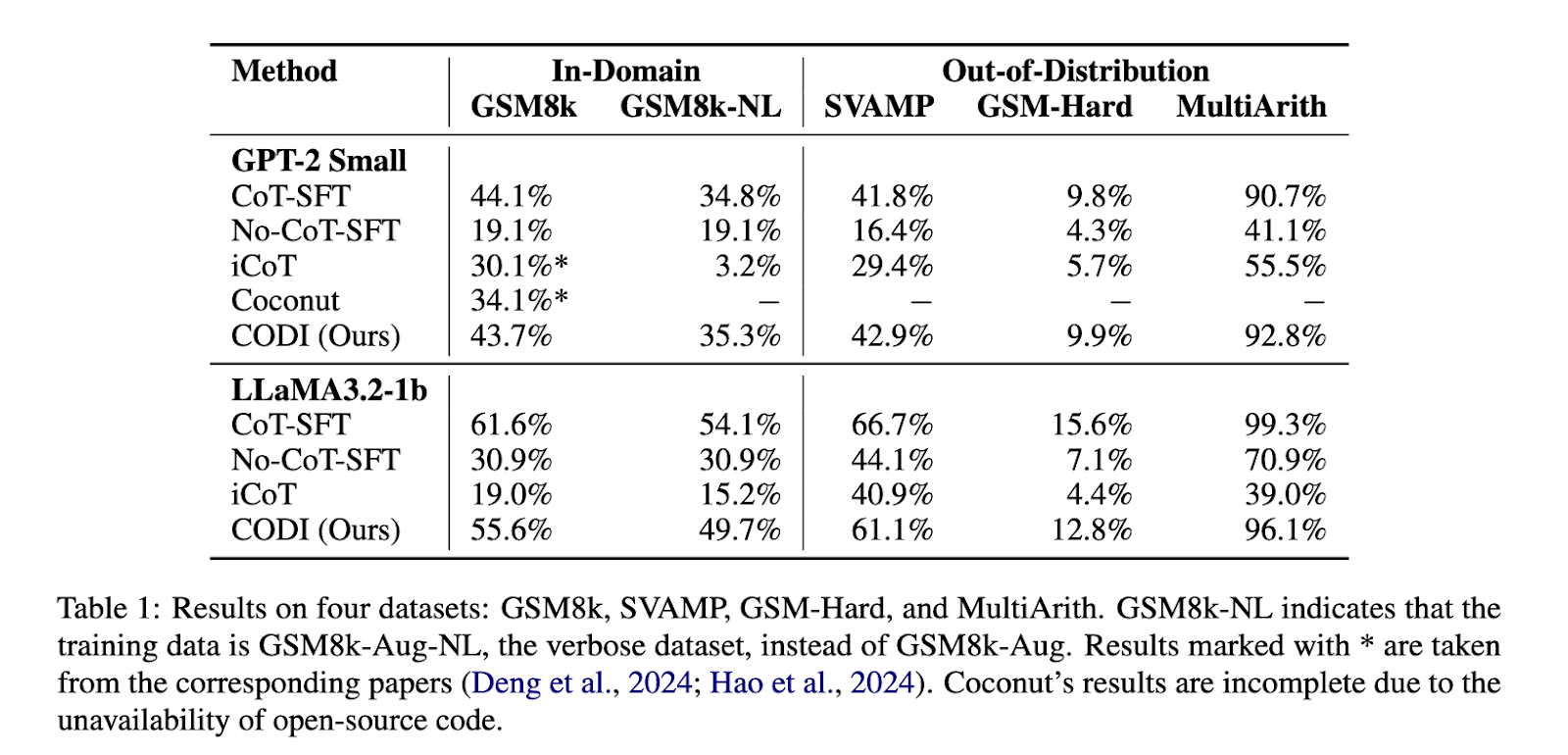
نتایج تجربی نشان میدهد که CODI به طور قابل توجهی از روشهای قبلی CoT ضمنی بهتر عمل میکند و اولین روشی است که با دقت CoT صریح در وظایف استدلال ریاضی مطابقت دارد. در مجموعه داده GSM8k، CODI به نسبت فشردهسازی 3.1 برابری دست مییابد و در عین حال عملکردی قابل مقایسه با CoT صریح را حفظ میکند. این روش از نظر دقت، 28.2 درصد از Coconut بهتر عمل میکند. علاوه بر این، CODI مقیاسپذیر است و با مجموعه دادههای مختلف CoT سازگار است و آن را برای مسائل استدلالی پیچیدهتر مناسب میسازد. معیارهای عملکرد نشان میدهند که CODI با یک مدل GPT-2 به دقت استدلال 43.7% در GSM8k دست مییابد، در حالی که این رقم برای Coconut 34.1% است. هنگامی که CODI بر روی مدلهای بزرگتر مانند LLaMA3.2-1b آزمایش شد، به دقت 55.6% دست یافت که توانایی آن را برای مقیاسپذیری موثر نشان میدهد. از نظر کارایی، CODI مراحل استدلال را 2.7 برابر سریعتر از CoT سنتی و 5.9 برابر سریعتر در هنگام اعمال بر روی مجموعه دادههای استدلالی پرمحتواتر پردازش میکند. طراحی قوی آن به آن اجازه میدهد تا به معیارهای خارج از دامنه تعمیم یابد و از CoT-SFT در مجموعه دادههایی مانند SVAMP و MultiArith بهتر عمل کند.

CODI یک پیشرفت چشمگیر در استدلال LLM محسوب میشود و به طور موثر شکاف بین CoT صریح و کارایی محاسباتی را پر میکند. بهرهگیری از خود-تقطیری و بازنماییهای پیوسته، رویکردی مقیاسپذیر برای استدلال هوش مصنوعی معرفی میکند. این مدل قابلیت تفسیر را حفظ میکند، زیرا تفکرات پیوسته آن را میتوان به الگوهای استدلالی ساختاریافته رمزگشایی کرد و شفافیت را در فرآیند تصمیمگیری فراهم کرد. تحقیقات آتی میتواند کاربرد CODI را در وظایف استدلالی چندوجهی پیچیدهتر بررسی کند و مزایای آن را فراتر از حل مسئله ریاضی گسترش دهد. این چارچوب، CoT ضمنی را به عنوان یک جایگزین کارآمد از نظر محاسباتی و یک راه حل مناسب برای چالشهای استدلال در سیستمهای پیشرفته هوش مصنوعی معرفی میکند.
مقاله را بررسی کنید. تمام اعتبار این تحقیق متعلق به محققان این پروژه است.