هوش مصنوعی مولد با چالشی اساسی در ایجاد تعادل بین استقلال و کنترلپذیری مواجه است. در حالی که استقلال از طریق مدلهای مولد قدرتمند به طور قابل توجهی پیشرفت کرده است، کنترلپذیری به نقطه کانونی برای محققان یادگیری ماشین تبدیل شده است. کنترل مبتنی بر متن به ویژه اهمیت پیدا کرده است زیرا زبان طبیعی رابطی شهودی بین انسان و ماشین ارائه میدهد. این رویکرد کاربردهای قابل توجهی را در ویرایش تصویر، سنتز صدا و تولید ویدئو امکانپذیر کرده است. مدلهای مولد اخیر تبدیل متن به داده، به ویژه آنهایی که از تکنیکهای انتشار استفاده میکنند، با استفاده از بینشهای معنایی از مجموعه دادههای گسترده جفت داده-متن، نتایج چشمگیری را نشان دادهاند. با این حال، موانع قابل توجهی در موقعیتهای کممنابع به وجود میآیند که در آن به دست آوردن دادههای کافی جفتشده با متن به دلیل ساختارهای پیچیده داده، بسیار پرهزینه یا دشوار میشود. حوزههای حیاتی مانند دادههای مولکولی، کپچر حرکت و سریهای زمانی اغلب فاقد برچسبهای متنی کافی هستند که قابلیتهای یادگیری نظارتشده را محدود میکند و مانع استقرار مدلهای مولد پیشرفته میشود. این محدودیتها بهطور قابلپیشبینی منجر به کیفیت تولید پایین، بیشبرازش مدل، سوگیری و تنوع خروجی محدود میشوند - که شکاف قابلتوجهی را در بهینهسازی بازنماییهای متنی برای همترازی بهتر در زمینههای محدود به داده نشان میدهد.
سناریوی کممنابع، چندین رویکرد کاهشی را برانگیخته است که هر کدام محدودیتهای ذاتی خود را دارند. تکنیکهای تقویت داده اغلب در همترازی دقیق دادههای مصنوعی با توضیحات متنی اصلی شکست میخورند و خطر بیشبرازش را افزایش میدهند و در عین حال نیازهای محاسباتی را در مدلهای انتشار افزایش میدهند. یادگیری نیمهنظارتی با ابهامات ذاتی در دادههای متنی دست و پنجه نرم میکند و تفسیر صحیح را هنگام پردازش نمونههای بدون برچسب چالشبرانگیز میکند. یادگیری انتقالی، در حالی که برای مجموعه دادههای محدود امیدوارکننده است، اغلب از فراموشی فاجعهبار رنج میبرد، جایی که مدل دانش قبلی خود را در حین تطبیق با توضیحات متنی جدید از دست میدهد. این کاستیهای روششناختی، نیاز به رویکردهای قویتر را که بهطور خاص برای تولید متن به داده در محیطهای کممنابع طراحی شدهاند، برجسته میکند.
در این مقاله، محققان Salesforce AI Research، Text2Data را ارائه میدهند که چارچوبی مبتنی بر انتشار را معرفی میکند که کنترلپذیری متن به داده را در سناریوهای کممنابع از طریق یک رویکرد دو مرحلهای افزایش میدهد. ابتدا، با استفاده از دادههای بدون برچسب از طریق یک مدل انتشار بدون نظارت، بر توزیع دادهها تسلط مییابد و از ابهام معنایی رایج در روشهای نیمهنظارتی جلوگیری میکند. دوم، تنظیم دقیق کنترلپذیر را روی دادههای دارای برچسب متنی بدون گسترش مجموعه داده آموزشی پیادهسازی میکند. در عوض، Text2Data از یک هدف یادگیری مبتنی بر بهینهسازی محدودیت استفاده میکند که با نزدیک نگه داشتن پارامترهای مدل به حالت قبل از تنظیم دقیق، از فراموشی فاجعهبار جلوگیری میکند. این چارچوب منحصربهفرد بهطور موثر از دادههای دارای برچسب و بدون برچسب برای حفظ توزیع دقیق دادهها و در عین حال دستیابی به کنترلپذیری برتر استفاده میکند. اعتبارسنجی نظری از انتخاب محدودیت بهینهسازی و حدود تعمیم پشتیبانی میکند، با آزمایشهای جامع در سه حالت که کیفیت تولید برتر و کنترلپذیری Text2Data را در مقایسه با روشهای پایه نشان میدهد.
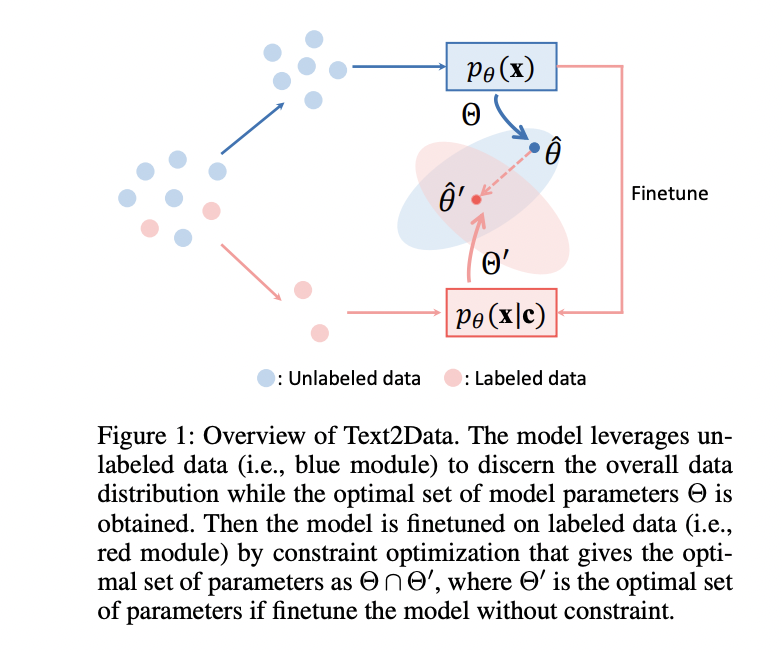
Text2Data با یادگیری توزیع شرطی p?(x|c) که در آن دادههای جفتشده محدود، چالشهای بهینهسازی ایجاد میکنند، به تولید دادههای کنترلپذیر میپردازد. این چارچوب در دو فاز مجزا عمل میکند که در شکل زیر نشان داده شده است. در ابتدا، از دادههای بدون برچسب فراوانتر برای یادگیری توزیع حاشیهای p?(x) استفاده میکند و پارامترهای بهینه ?^ را در مجموعه T به دست میآورد. این رویکرد از رابطه ریاضی بین توزیعهای حاشیهای و شرطی بهره میبرد، جایی که p?(x) مقدار പ്രതീക്ഷشده p?(x|c) را روی توزیع متن تقریب میزند. متعاقباً، Text2Data این پارامترها را با استفاده از جفتهای داده-متن دارای برچسب موجود تنظیم دقیق میکند و در عین حال بهینهسازی محدودیت را برای نگه داشتن پارامترهای بهروزشده ?^’ در تقاطع T و T’ پیادهسازی میکند. این محدودیت تضمین میکند که مدل دانش توزیع کلی دادهها را حفظ میکند و در عین حال کنترلپذیری متن را به دست میآورد و بهطور موثر از فراموشی فاجعهباری که معمولاً در طول فرآیندهای تنظیم دقیق رخ میدهد، جلوگیری میکند.
Text2Data رویکرد دو فازی خود را ابتدا با استفاده از تمام دادههای موجود با توکنهای NULL به عنوان شرط برای یادگیری توزیع کلی دادهها پیادهسازی میکند. این به مدل اجازه میدهد تا p?(x|Ø) را بهینه کند، که بهطور موثر برابر با p?(x) است زیرا توکن NULL مستقل از x است. فاز دوم یک چارچوب بهینهسازی محدودیت را معرفی میکند که مدل را روی دادههای دارای برچسب متنی تنظیم دقیق میکند و در عین حال از انحراف پارامتر از توزیع آموختهشده قبلی جلوگیری میکند. از نظر ریاضی، این به عنوان به حداقل رساندن لگاریتم درستنمایی منفی احتمال شرطی p?(x|c) با این شرط که عملکرد توزیع حاشیهای نزدیک به مقدار بهینه ? تعیینشده در طول فاز اول باقی بماند، بیان میشود. این رویکرد مبتنی بر محدودیت مستقیماً به فراموشی فاجعهبار میپردازد و تضمین میکند که پارامترهای مدل در یک مجموعه بهینه باقی میمانند که در آن هم بازنمایی کلی دادهها و هم کنترلپذیری خاص متن میتوانند همزیستی داشته باشند - اساساً یک مسئله بهینهسازی واژگانی را حل میکند که این اهداف رقابتی را متعادل میکند.
این چارچوب با تبدیل هدف نظری به توابع زیان عملی، راهنمایی انتشار بدون طبقهبندی را پیادهسازی میکند. این چارچوب سه مولفه کلیدی را بهینه میکند: L1(?) برای یادگیری توزیع کلی دادهها، L’1(?) برای حفظ توزیع روی دادههای دارای برچسب، و L2(?) برای تولید مشروط به متن. اینها بهطور تجربی با استفاده از نمونههای داده موجود تخمین زده میشوند. فرآیند بهینهسازی واژگانی، که در الگوریتم 1 بهتفصیل شرح داده شده است، این اهداف را با تنظیم دینامیکی بهروزرسانیهای گرادیان با پارامتر ? متعادل میکند که محدودیتها را اعمال میکند و در عین حال امکان یادگیری موثر را فراهم میکند. این رویکرد از یک قاعده بهروزرسانی پیچیده استفاده میکند که در آن ? بر اساس ترکیبی وزنی از گرادیانهای هر دو هدف اصلاح میشود. این محدودیت میتواند در طول آموزش کاهش یابد تا همگرایی بهبود یابد، با این تشخیص که پارامترها نیازی به زیرمجموعه دقیقی از فضای پارامتر اصلی ندارند، اما باید نزدیک باقی بمانند تا دانش توزیع را حفظ کنند و در عین حال کنترلپذیری را به دست آورند.

Text2Data مبانی نظری رویکرد بهینهسازی محدودیت خود را از طریق حدود تعمیم ارائه میدهد که انتخاب پارامتر را تایید میکند. این چارچوب ثابت میکند که متغیرهای تصادفی مشتقشده از فرآیند انتشار، زیرگاوسی هستند و امکان فرمولبندی حدود اطمینان دقیق را فراهم میکنند. قضیه 0.2 سه تضمین حیاتی ارائه میدهد: اول، مجموعه پارامتر تجربی در محدوده اطمینان، مجموعه بهینه واقعی را بهطور کامل در بر میگیرد. دوم، راهحل تجربی بهطور موثر با بهینه نظری در هدف اولیه رقابت میکند. و سوم، راهحل تجربی پایبندی معقولی به محدودیت نظری حفظ میکند. پیادهسازی عملی یک پارامتر کاهش ? را معرفی میکند که سختی محدودیت را تنظیم میکند و در عین حال آن را در بازه اطمینان توجیهشده ریاضی نگه میدارد. این کاهش، شرایط دنیای واقعی را تایید میکند که در آن به دست آوردن نمونههای بدون برچسب متعدد امکانپذیر است و باعث میشود که محدوده اطمینان بهطور منطقی محکم باشد، حتی هنگام کار با مدلهایی با میلیونها پارامتر. آزمایشها با تولید حرکت شامل 45000 نمونه و 14 میلیون پارامتر، دوام عملی این چارچوب را تایید میکنند.

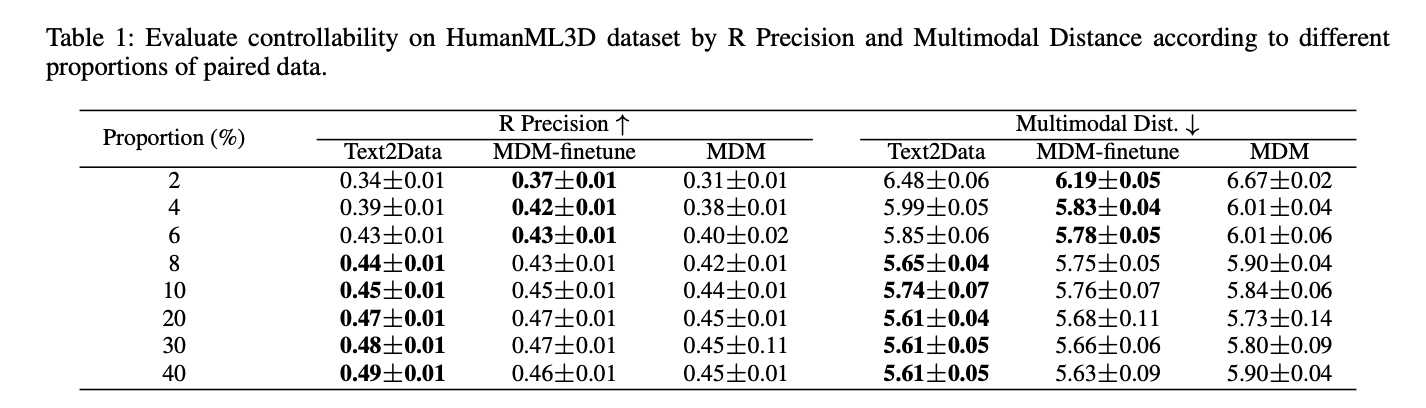
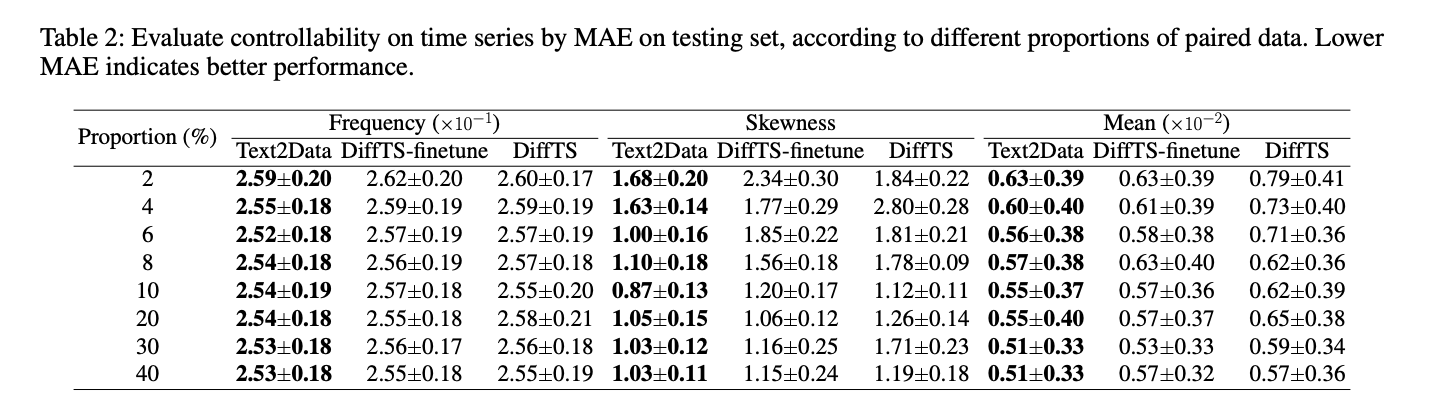
Text2Data در مقایسه با روشهای پایه، کنترلپذیری برتری را در چندین دامنه نشان میدهد. در تولید مولکولی، به خطای مطلق میانگین (MAE) کمتری برای تمام ویژگیها در مقایسه با EDM-finetune و EDM دست مییابد، بهویژه با ویژگیهایی مانند ?LUMO و Cv. برای تولید حرکت، Text2Data از MDM-finetune و MDM در معیارهای R Precision و Multimodal Distance پیشی میگیرد. در تولید سریهای زمانی، بهطور مداوم از DiffTS-finetune و DiffTS در تمام ویژگیهای ارزیابیشده بهتر عمل میکند. فراتر از کنترلپذیری، Text2Data کیفیت تولید استثنایی را حفظ میکند و بهبودهایی را در اعتبار مولکولی، پایداری، تنوع تولید حرکت و همترازی توزیع در سریهای زمانی نشان میدهد. این نتایج، اثربخشی Text2Data را در کاهش فراموشی فاجعهبار و در عین حال حفظ کیفیت تولید تایید میکنند.

Text2Data بهطور موثر به چالشهای تولید متن به داده در سناریوهای کممنابع در چندین حالت میپردازد. با استفاده اولیه از دادههای بدون برچسب برای درک توزیع کلی دادهها و سپس پیادهسازی بهینهسازی محدودیت در طول تنظیم دقیق روی دادههای دارای برچسب، این چارچوب با موفقیت کنترلپذیری را با حفظ توزیع متعادل میکند. این رویکرد از فراموشی فاجعهبار جلوگیری میکند و در عین حال کیفیت تولید را حفظ میکند. نتایج تجربی بهطور مداوم برتری Text2Data را نسبت به روشهای پایه هم در کنترلپذیری و هم در کیفیت تولید نشان میدهد. اگرچه Text2Data با مدلهای انتشار پیادهسازی شده است، اما اصول آن بهراحتی میتواند با سایر معماریهای مولد سازگار شود.