

عاملها چه هستند؟ هاگینگ فیس به طور خلاصه بیان میکند – "عاملهای هوش مصنوعی برنامههایی هستند که در آنها خروجیهای LLM جریان کار را کنترل میکنند." با این حال، اصطلاح مبهم در اینجا LLM است. امروزه LLMها جریان کار را کنترل میکنند، و ما این "برنامهها" را عامل مینامیم، اما این احتمالاً تغییر خواهد کرد. شاید حتی تا سال 2025 هم پاسخ روشنی وجود نداشته باشد. ما هم قرار نیست در این مقاله به این سوال پاسخ دهیم. این مقاله یک هدف ساده دارد. آشنا کردن خوانندگان با کتابخانه smolagents هاگینگ فیس. و در طول مسیر، توضیح دهیم که چه اتفاقی در پشت صحنه میافتد که منجر به استفاده از اصطلاح عاملها میشود.
اصطلاح عاملهای LLM حدود 2 سال است که مطرح شده است. ما با فراخوانی تابع شروع کردیم، به استفاده از ابزار (روش پیچیدهتری برای فراخوانی تابع) رسیدیم و اکنون در عاملها هستیم. عاملهای LLM، به بیان ساده، از ترکیبی از فراخوانی تابع و استفاده از ابزار به صورت چند مرحلهای برای دستیابی به آنچه کاربر میخواهد استفاده میکنند.
در این مقاله از طریق smolagents چه چیزی را پوشش خواهیم داد؟
- smolagents هاگینگ فیس چیست؟
- چرا به smolagents نیاز داریم؟
- smolagents چه کاری میتواند انجام دهد؟
- وقتی از یک عامل میخواهیم:
- یک تصویر تولید کند.
- در اینترنت جستجو کند.
- اطلاعاتی را در یک صفحه وب پیدا کند و به یک سوال خاص پاسخ دهد.
توجه: ما نه به کد منبع نگاه خواهیم کرد و نه خودمان کد پیچیدهای خواهیم نوشت. این اولین مقاله، مراحلی را که یک LLM برای دستیابی به آنچه یک عامل باید از طریق کتابخانه smolagents انجام دهد، آشکار میکند.
smolagents هاگینگ فیس چیست؟
به بیان ساده، smolagents کتابخانهای از هاگینگ فیس برای ساخت عاملهای LLM و جریانهای کاری عاملی است.
چرا به smolagents نیاز داریم؟
این کتابخانه به ما امکان میدهد فراخوانی تابع، استفاده از ابزار و LLMها را به روشی ساده برای یک جریان کاری یکپارچه متصل کنیم. ما میتوانیم از هر LLM از هاگینگ فیس برای ساخت عاملهای خود استفاده کنیم. علاوه بر این، از HfAPI پشتیبانی میکند که با استفاده از آن هر کاربر هاگینگ فیس میتواند تا 1000 تماس در روز به صورت رایگان دسترسی داشته باشد.
Smolagents چه کاری میتواند انجام دهد و چگونه کار میکند؟
به طور پیشفرض، smolagents بر روی عاملهای کد کار میکند. این بدان معناست که به جای استفاده از JSON برای فراخوانی تابع، LLMها کد خود را برای اجرای جریان کاری عاملی مینویسند.
این روش در بسیاری از موارد بهتر عمل کرده است زیرا LLMها در حال حاضر در کدنویسی بسیار خوب هستند. بنابراین، با توجه به تعریف تابع یک ابزار (مثلاً در پایتون)، LLMها کد را برای فراخوانی آن با آرگومانهای صحیح برای انجام پرس و جوی کاربر مینویسند.
این موضوع زمانی که نمونههای مختلف را در ادامه مقاله بررسی کنیم، منطقیتر خواهد بود.
ساختار دایرکتوری پروژه
بیایید نگاهی به ساختار دایرکتوری پروژه بیندازیم.
+-- calculator.ipynb +-- combine_tool.ipynb +-- image_generation.ipynb +-- llama_3_2_test.ipynb +-- requirements.txt +-- web_search.ipynb
- ما 5 نوتبوک مختلف داریم. چهار تای آنها نوتبوکهای جریان کاری smolagents هستند که در بخشهای مربوطه به آنها خواهیم پرداخت.
- نوتبوک Jupyter
llama_3_2_test.ipynbبرای آزمایش مدل Llama 3.2 3B به صورت محلی بدون هیچ جریان کاری عاملی استفاده میشود. این میتواند هنگام تلاش برای مقایسه نتایج با و بدون جریان کاری عاملی مفید باشد. - فایل
requirements.txtشامل کتابخانههایی است که برای اجرای کد در این مقاله نیاز داریم.
.
نصب وابستگیها
ما میتوانیم تمام کتابخانهها را از طریق فایل الزامات که شامل smolagents، transformers و Hugging Face Hub است نصب کنیم.
pip install -r requirements.txt
همین. بیایید بدون هیچ تأخیری وارد بخش کدنویسی شویم.
استفاده از smolagents برای جریانهای کاری عاملی
ما در اینجا 4 مورد استفاده مختلف را پوشش خواهیم داد، از یک مثال ساده تولید تصویر تا ترکیب ابزارها.
تولید تصویر با استفاده از smolagents
اولین مورد استفاده ساده است: ما یک تصویر تولید خواهیم کرد یا از یک LLM میخواهیم که یک تصویر تولید کند.
کد این قسمت در نوتبوک Jupyter image_generation.ipynb موجود است.
ابتدا، دستورات import.
from smolagents import load_tool, CodeAgent, HfApiModel
ما در اینجا یک تابع و دو کلاس را import میکنیم:
load_tool: ما میتوانیم از این تابع برای بارگیری هر ابزار سفارشی یا میزبانی شده در هاگینگ فیس استفاده کنیم. کد بعداً این موضوع را روشن میکند.CodeAgent: این کلاس یک نمونه عامل کد را مقداردهی اولیه میکند. یک عامل کد، کد پایتون را برای استفاده از ابزاری که از طریقload_toolبارگیری میکنیم، مینویسد.HfApiModel: این شاید بهترین قسمت باشد. ما میتوانیم هر LLM را از هاگینگ فیس با استفاده از کلاس بدون سرورHfApiModelبارگیری کنیم. این بدان معناست که مدل به جای محلی، روی سختافزار میزبانی شده هاگینگ فیس اجرا میشود. چه یک مدل Llama 3B باشد چه یک مدل Qwen 72B. در زمان نوشتن این مقاله، هر کاربر 1000 تماس API در روز دریافت میکند که برای انجام آزمایشهای در مقیاس کوچک کافی است. میتوانید تماسهای باقیمانده خود را برای روز با کلیک کردن روی نماد کاربری خود در هاگینگ فیس و رفتن به Inference API بررسی کنید.
بارگیری ابزار تولید تصویر
از آنجایی که ما قصد داریم یک تصویر تولید کنیم، گام بعدی بارگیری یک ابزار تولید تصویر است. ما از ابزاری که قبلاً در فضاهای هاگینگ فیس میزبانی شده است استفاده خواهیم کرد.
# Image generation tool.
image_gen_tool = load_tool('m-ric/text-to-image', trust_remote_code=True)
اجرای سلول بالا خروجی زیر را میدهد:
TOOL CODE:
from smolagents import Tool
from huggingface_hub import InferenceClient
class TextToImageTool(Tool):
description = "This tool creates an image according to a prompt, which is a text description."
name = "image_generator"
inputs = {"prompt": {"type": "string", "description": "The image generator prompt. Don't hesitate to add details in the prompt to make the image look better, like 'high-res, photorealistic', etc."}}
output_type = "image"
model_sdxl = "black-forest-labs/FLUX.1-schnell"
client = InferenceClient(model_sdxl)
def forward(self, prompt):
return self.client.text_to_image(prompt)
بنابراین، موارد بالا چگونه کار میکند؟ موارد بالا یک فضای هاگینگ فیس توسط m-ric است. اگر از فضای ابزار بالا بازدید کنید، میتوانید مستقیماً از طریق رابط Gradio تصاویری تولید کنید. با این حال، جادوی واقعی در فایلهای کد است.
ما سه فایل پایتون داریم: app.py، tool.py، tool_config.py.
کد اصلی در فایل tool.py قرار دارد. این شامل یک کلاس برای تولید تصویر است و زیرکلاس کلاس Tool است.
فایل app.py فقط کلاس را import میکند و دموی Gradio را راهاندازی میکند.
و در نهایت، فایل tool_config.py چیزی است که به تابع load_tool میگوید که این یک ابزار است و چگونه از آن استفاده کند. برای روشن شدن، موارد زیر محتوای فایل پیکربندی است.
{
"description": "This is a tool that creates an image according to a prompt, which is a text description.",
"inputs": "{'prompt': {'type': 'string', 'description': \"The image generator prompt. Don't hesitate to add details in the prompt to make the image look better, like 'high-res, photorealistic', etc.\"}}",
"name": "image_generator",
"output_type": "image",
"tool_class": "tool.TextToImageTool"
}
به طور خلاصه، خروجی بارگیری ابزار و ترکیب فایلهای پیکربندی به LLM میگوید که چگونه ابزار را مقداردهی اولیه و استفاده کند.
من به شدت توصیه میکنم فایلهای کد را در فضا بررسی کنید و کمی بیشتر آن را درک کنید.
اجرای عاملی با استفاده از Qwen 2.5 72B
اکنون، بیایید یک LLM بارگیری کنیم و یک تصویر تولید کنیم.
# Initialize language model.
model = HfApiModel('Qwen/Qwen2.5-72B-Instruct')
ما مدل Qwen را با استفاده از HfApiModel بارگیری میکنیم. دانلود نخواهد شد و از هیچ منبع محلی استفاده نخواهد کرد.
سپس، عامل کد را مقداردهی اولیه میکنیم.
agent = CodeAgent(tools=[image_gen_tool], model=model)
دو آرگومان میپذیرد، یک لیست tools شامل ابزارهای مقداردهی اولیه شدهای که میخواهیم استفاده کنیم و LLM.
در نهایت، ما از متد run برای شروع جریان کاری عاملی استفاده میکنیم.
# Run the tool.
results = agent.run('Generate a photo of a white mountain with orange sunset.')
ما یک پرامپت متنی برای تولید تصویر ارائه میدهیم.
خروجی جریان کاری عاملی
شکل زیر نشان میدهد که جریان کاری در طول اجرا چه کاری انجام میدهد.
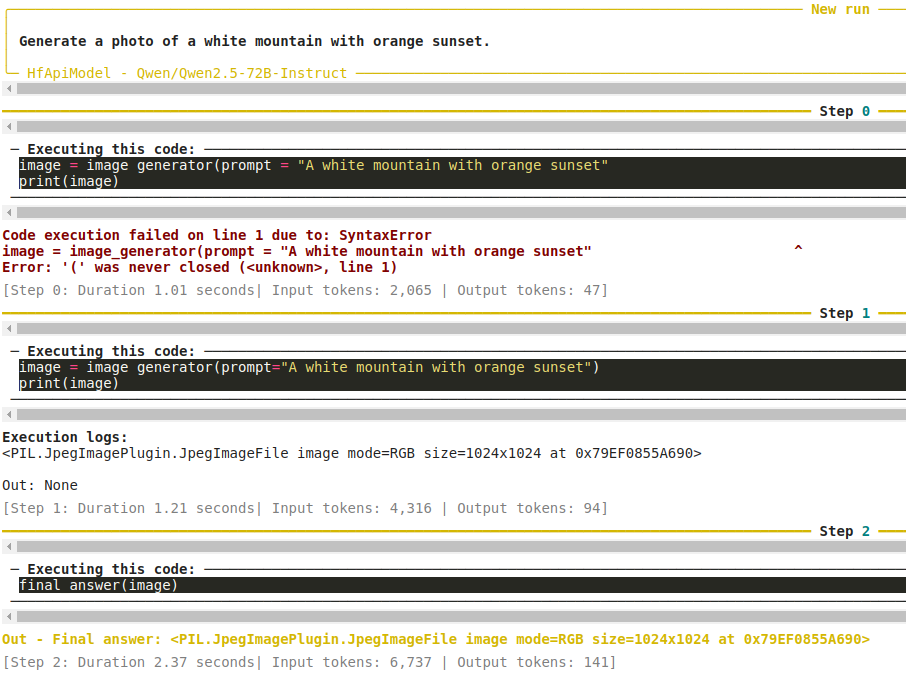
مدل با مقداردهی اولیه کلاس به عنوان image_generator و ارسال پرامپت شروع میکند. با این حال، در اولین تلاش، خطایی وجود داشت زیرا پرانتز بسته نشده بود که منجر به مرحله دوم شد. این بار، کد نوشته شده توسط LLM صحیح بود و یک تصویر PIL برگردانده شد.
ما خروجی زیر را دریافت میکنیم.

این یک جنبه مهم از جریان کاری عاملی را نشان میدهد. حتی اگر خطایی در یکی از مراحل میانی وجود داشته باشد، LLM آن را کاهش میدهد. زیرا خطا بخشی از اجرای کد نوشته شده توسط LLM بود. حتی اگر چندین خطا وجود داشته باشد، کاربر نهایی همیشه یک خروجی زبان طبیعی از LLM دریافت میکند. پیامدهای این، چه خوب و چه بد، بیشتر مورد بحث است. و احتمالاً این در آینده تغییر خواهد کرد.
با این حال، موارد بالا به ما درک خوبی از شکل ظاهری یک جریان کاری عاملی ساده داد.
استفاده از مفسر پایتون با عاملها
یکی از معایب مدلهای زبان کوچک، عدم مهارتهای محاسباتی آنها است. اگرچه LLMها در مقایسه بهتر هستند، یک ابزار شبیه ماشین حساب افزودنی خوبی برای جریان کاری عاملی است.
برای مثال بعدی، ما قصد داریم مدل Llama 3.2 3B Instruct را به ابزار مفسر پایتون مجهز کنیم تا بتواند عملیات ریاضی را انجام دهد.
کد این قسمت در نوتبوک Jupyter calculator.ipynb موجود است.
بلوک کد زیر شامل دستور import، مقداردهی اولیه PythonInterpreterTool و بارگیری مدل است.
from smolagents import CodeAgent, HfApiModel, PythonInterpreterTool
calc_tool = PythonInterpreterTool()
# Initialize language model.
model = HfApiModel('meta-llama/Llama-3.2-3B-Instruct')
ابزار مفسر پایتون به مدل زبان اجازه میدهد تا هر نوع عملیات پایتونی را در خط فرمان (ترمینال) اجرا کند.
سپس، عامل را مقداردهی اولیه میکنیم و آن را اجرا میکنیم.
agent = CodeAgent(tools=[calc_tool], model=model)
# Run the tool.
results = agent.run('What is (99*99)+9999*(9999)+(89×5199)?')
ما به مدل یک عملیات محاسباتی پیچیده میدهیم تا محاسبه کند. نیازی به گفتن نیست که مدل Llama 3.2 3B به تنهایی قادر به ارائه پاسخ صحیح نیست. با این حال، هنگامی که به ابزار مفسر پایتون مجهز میشود، خروجی زیر را میدهد.
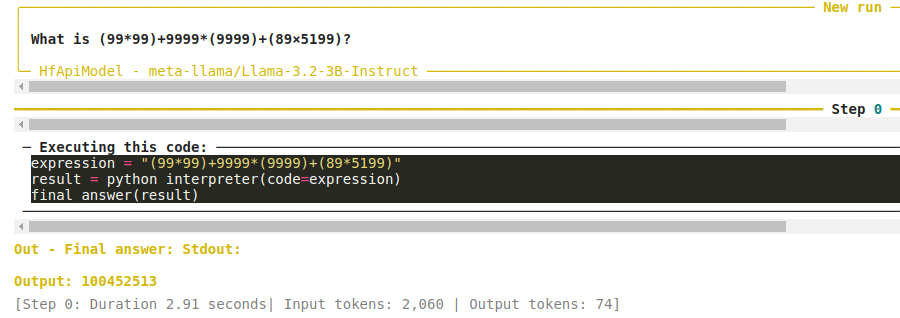
مدل ابزار را فراخوانی میکند و عبارت ریاضی را برای محاسبه ارسال میکند. در اولین مرحله میتواند پاسخ صحیح را ارائه دهد.
این نشاندهنده قدرت مجهز کردن مدلهای زبان به ابزارهای صحیح است.
استفاده از جستجوی وب با عاملها
یکی از بزرگترین معایب مدلهای زبان، تاریخ قطع دانش آنها است. این تاریخی است که مجموعه داده شامل اطلاعاتی است که مدل بر اساس آن آموزش دیده است. در زمان نوشتن این مقاله، تقریباً همه مدلها بر روی دادههایی تا دسامبر 2023 آموزش دیدهاند. بنابراین، مدلها نمیتوانند به هیچ سوال واقعی که به اطلاعات پس از این تاریخ نیاز دارد، به درستی پاسخ دهند.
در چنین مواردی، میتوان از جستجوی وب استفاده کرد. در مثال بعدی، ما مدل Llama 3.2 3B را به DuckDuckGoSearchTool مجهز میکنیم و یک سوال جدیدتر میپرسیم.
کد این قسمت در نوتبوک Jupyter web_search.ipynb موجود است.
بیایید با importها، مقداردهی اولیه ابزار، بارگیری مدل و مقداردهی اولیه عامل شروع کنیم.
from smolagents import CodeAgent, HfApiModel, DuckDuckGoSearchTool
search_tool =
DuckDuckGoSearchTool()
# Initialize language model.
model = HfApiModel('meta-llama/Llama-3.2-3B-Instruct')
agent = CodeAgent(tools=[search_tool], model=model)
ما همان LLM قبلی را با این تفاوت که از ابزار جستجوی DuckDuckGo به جای مفسر پایتون استفاده میکنیم، مقداردهی اولیه میکنیم.
سپس، عامل را با ارسال یک سوال اجرا میکنیم.
# Run the tool.
results = agent.run('What is the capital of India?')
خروجی زیر را دریافت میکنیم.
The capital of India is New Delhi.
متوجه خواهید شد که مدل این بار ابزار را بارگذاری کرده است. همچنین مهم است که توجه داشته باشید که DuckDuckGo به تنهایی نمیتواند پاسخ را برگرداند زیرا فقط یک موتور جستجو است. بنابراین، مدل باید کدی بنویسد تا جستجوی وب را انجام دهد و نتایج را برای یافتن پاسخ صحیح بخار کند.
این امر اهمیت استفاده از ابزارهای صحیح را با LLMها نشان میدهد.
ترکیب ابزارهای متعدد با عاملها
میتوانیم ابزارهای متعددی را با عاملها ترکیب کنیم تا الگوها را به طور واقعیتر منعکس کنیم. در این مثال، از یک مدل میخواهیم عملیات حسابی را انجام دهد و سپس بر اساس نتیجه جستجوی وب انجام دهد.
کد این قسمت در نوتبوک Jupyter combine_tool.ipynb موجود است.
بیایید از ابتدای فرآیند عبور کنیم: واردات، مقداردهی اولیه ابزار و بارگیری مدل.
from smolagents import CodeAgent, HfApiModel, DuckDuckGoSearchTool, PythonInterpreterTool
search_tool = DuckDuckGoSearchTool()
calc_tool = PythonInterpreterTool()
# Initialize language model.
model = HfApiModel('meta-llama/Llama-3.2-3B-Instruct')
مشاهده میکنید که هم از DuckDuckGoSearchTool و هم از PythonInterpreterTool استفاده میکنیم.
بعد، بیایید عامل را مقداردهی اولیه کنیم و آن را اجرا کنیم.
agent = CodeAgent(tools=[search_tool, calc_tool], model=model)
# Run the tool.
results = agent.run('Calculate 8900 * 0.02 and then search for it on the internet.')
خروجی این بار به این صورت است.
8900 * 0.02 is 178.0
ما به مدل دادهایم که عملیات حسابی را انجام دهد و از نتیجه برای جستجو در اینترنت استفاده کند و با موفقیت انجام شد. به یاد داشته باشید که یک کاربر میتواند هر مجموعهای از ابزار را به هر ترتیبی که برای یک هدف نیاز است ترکیب کند.
افکار پایانی
این به پایانی برای این مقاله در مورد استفاده از کتابخانه smolagents هاگینگ فیس میرسد. پوشش به این معنی است که خوانندگان نباید با مفاهیم عاملهای LLM ناآشنا باشند و این کتابخانه یک راه ساده برای آزمایش آن است.