امروزه موتورهای جستجو و سیستمهای پیشنهاد در پلتفرمهای محتوای آنلاین ضروری هستند. روشهای سنتی جستجو بر محتوای متنی تمرکز دارند و شکافی حیاتی در پردازش متون مصور و ویدیوها ایجاد میکنند که به اجزای حیاتی جوامع محتوای تولید شده توسط کاربر (UGC) تبدیل شدهاند. مجموعه دادههای کنونی برای وظایف جستجو و پیشنهاد، حاوی اطلاعات متنی یا ویژگیهای متراکم آماری هستند که توسعه خدمات جستجو و پیشنهاد چندوجهی (S&R) موثر را به شدت محدود میکند. علاوه بر این، سیگنال سطح جلسه حاوی اطلاعات زمینهای ارزشمندی در مورد رفتار بازفرمولبندی، اقدامات بازبینی، منابع هدف جستجو و الگوهای انتقال بین عملکردهای جستجو و پیشنهاد است که مستقیماً بر رضایت و حفظ کاربر تأثیر میگذارد.
رویکردهای موجود سعی در رفع چالشهای بازیابی چندوجهی داشتند. رویکردهای مبتنی بر یادگیری بازنمایی، تصاویر را با استفاده از توابع هش به فضای همینگ دودویی نگاشت میکنند یا آنها را با شبکههای عصبی عمیق در فضاهای معنایی پنهان کدگذاری میکنند. روشهای آگاه از هش، عملکرد کارآمد در زمان واقعی را با هزینههای ذخیرهسازی کم ارائه میدهند، در حالی که رویکردهای مبتنی بر معناشناسی بر درک وجه و تطبیق بین وجهی تمرکز دارند. علاوه بر این، مجموعه دادهها برای وظایف جستجو، پیشنهاد و S&R فقط شامل محتویات متنی یا ویژگیهای مبتنی بر ارزش هستند. در حالی که برخی از مجموعه دادههای تجارت الکترونیک شامل عناوین و تصاویر محصول هستند و مجموعه دادههای تخصصی مانند UniIR و Flickr30K برای بازیابی چندوجهی وجود دارند، این مجموعه داده ها به پرسوجوهای واقعی با نیت روشن میپردازند تا نیازهای پیچیده اطلاعات کاربر.
پژوهشگران Xiaohongshu Inc. و دانشگاه چینهوا، Qilin را پیشنهاد کردهاند، یک مجموعه داده بازیابی اطلاعات چندوجهی که برای رفع نیاز روزافزون به توسعه خدمات بهتر S&R طراحی شده است. این مجموعه داده که از Xiaohongshu، یک پلتفرم اجتماعی محبوب با بیش از 300 میلیون کاربر فعال ماهانه و میانگین نرخ نفوذ جستجوی بیش از 70٪ جمعآوری شده است، مجموعهای از جلسات کاربر را با نتایج ناهمگن، از جمله یادداشتهای تصویر-متن، یادداشتهای ویدیویی، یادداشتهای تجاری و پاسخهای مستقیم ارائه میدهد. علاوه بر این، Qilin شامل سیگنالهای متنی گسترده در سطح برنامه و بازخورد واقعی کاربر برای مدلسازی بهتر رضایت کاربر و پشتیبانی از تجزیه و تحلیل رفتارهای ناهمگن کاربر است. این مجموعه داده بهطور منحصربهفردی شامل پاسخهای مورد علاقه کاربر و نتایج ارجاعشده آنها برای درخواستهای جستجویی است که ماژول پاسخگویی عمیق پرسوجو (DQA) را فعال میکنند.
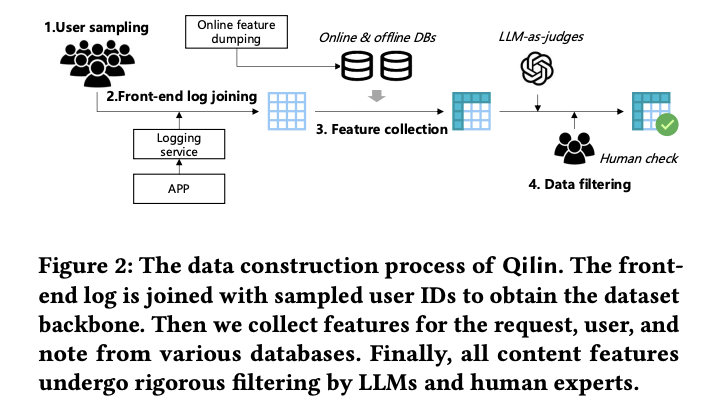
ساخت مجموعه داده Qilin از خط لولهای پیروی میکند که شامل نمونهبرداری کاربر، پیوستن لاگ فرانتاند، جمعآوری ویژگی و فیلتر کردن دادهها میشود. این مجموعه داده شامل جلسات در سطح برنامه از 15482 کاربر است که به طور قابل توجهی بزرگتر و متنوعتر از مجموعه دادههای جستجو و پیشنهاد موجود مانند آمازون، JD Search و KuaiSAR است. در حالی که آمازون را میتوان به طور حاشیهای برای مطالعه سیستمهای S&R چندوجهی پذیرفت، اما فقط پرسوجوهای کاذبی را ارائه میدهد که از فراداده محصول مشتق شدهاند و فاقد رفتارهای جستجوی واقعی کاربر هستند. JD Search و KuaiSAR فقط محتویات آیتم ناشناس را ارائه میدهند که تفسیر اثربخشی مدل را دشوار میکند. Qilin این محدودیتها را با استفاده از پلتفرم جامعه باز Xiaohongshu با UGC فراوان برطرف میکند. پس از فیلتر کردن کامل، مجموعه داده شامل محتوای یادداشت اصلی (عنوان + بدنه اصلی + تصاویر) میشود که کامل بودن و اصالت را تضمین میکند.
نتایج برای وظایف جستجو و پیشنهاد نشان میدهد که رمزگذار متقابل BERT از رمزگذار دوگانه بهتر عمل میکند، که تأیید میکند تعامل صریح پرسوجو و سند، تطابق ارتباط را افزایش میدهد. مدلهای زبان-بینایی (VLM) با ترکیب اطلاعات بصری به عملکرد بهتری دست مییابند. DCN-V2، که تاریخچه کاربر، ویژگیهای پراکنده مبتنی بر شناسه، ویژگیهای متراکم و تعبیههای معنایی از پیش آموزشدیده را ترکیب میکند، در رتبهبندی جستجو بهترین عملکرد را دارد. با این حال، مزیت آن در وظایف پیشنهادی به دو دلیل کمتر است: پرسوجوهای کاذب مورد استفاده در پیشنهاد، ترجیحات کاربر را خلاصه میکنند و پیشنهاد به استحکام مدل بیشتری برای رسیدگی به مشکلات خارج از توزیع نیاز دارد. وابستگی DCN-V2 به ویژگیهای پراکنده و مدلسازی محدود تطبیق سیگنال معنایی ممکن است در این شکاف عملکرد نقش داشته باشد.
در نتیجه، محققان Qilin را معرفی کردند، یک مجموعه داده بازیابی اطلاعات چندوجهی برای تحقیقات جستجو و پیشنهاد. این مجموعه داده که شامل جلسات در سطح برنامه از 15482 کاربر است، محتوای متنی و تصویری را برای نتایج ناهمگن فراهم میکند و شکافهای حیاتی در مجموعه دادههای موجود را برطرف میکند. محققان سیگنالهای متنی فراوانی از جمله منابع پرسوجو، انواع بازخورد کاربر متعدد و جزئیات پاسخگویی عمیق پرسوجو (DQA) را جمعآوری کردهاند و چارچوبی جامع برای بررسی وظایف مختلف بازیابی اطلاعات ایجاد کردهاند. آزمایشهای اولیه در جستجو، پیشنهاد و پاسخگویی عمیق پرسوجو در Qilin، تطبیقپذیری و کاربردهای بالقوه آن را نشان میدهد. این یافتهها و بینشها، جهتگیری ارزشمندی را برای توسعه سیستمهای بازیابی چندوجهی پیشرفتهتر ارائه میدهند.