
پژوهشگران دانشگاه ایالتی اوهایو، Finer-CAM را معرفی کردهاند، روشی نوآورانه که به طور قابل توجهی دقت و قابلیت تفسیر توضیحات تصویر را در وظایف طبقهبندی ریزدانه بهبود میبخشد. این تکنیک پیشرفته، محدودیتهای کلیدی روشهای موجود نقشه فعالسازی کلاس (CAM) را با برجستهسازی صریح تفاوتهای ظریف اما حیاتی بین دستههای بصری مشابه، برطرف میکند.
چالش فعلی با CAM سنتی
روشهای CAM معمولی معمولاً مناطقی کلی را که بر پیشبینیهای یک شبکه عصبی تأثیر میگذارند، نشان میدهند، اما اغلب در تشخیص جزئیات دقیقی که برای متمایز کردن کلاسهای نزدیک به هم ضروری هستند، ناکام میمانند. این محدودیت چالشهای مهمی را در زمینههایی که نیاز به تمایز دقیق دارند، مانند شناسایی گونههای جانوری، تشخیص مدل خودرو، و تمایز نوع هواپیما ایجاد میکند.
Finer-CAM: پیشرفت روششناختی
نوآوری اصلی Finer-CAM در استراتژی توضیح مقایسهای آن نهفته است. برخلاف روشهای سنتی CAM که صرفاً بر ویژگیهای پیشبینیکننده یک کلاس واحد تمرکز میکنند، Finer-CAM به صراحت کلاس هدف را با کلاسهای بصری مشابه مقایسه میکند. با محاسبه گرادیانها بر اساس تفاوت در لگاریتمهای پیشبینی بین کلاس هدف و همتایان مشابه آن، ویژگیهای منحصر به فرد تصویر را آشکار میکند و وضوح و دقت توضیحات بصری را افزایش میدهد.
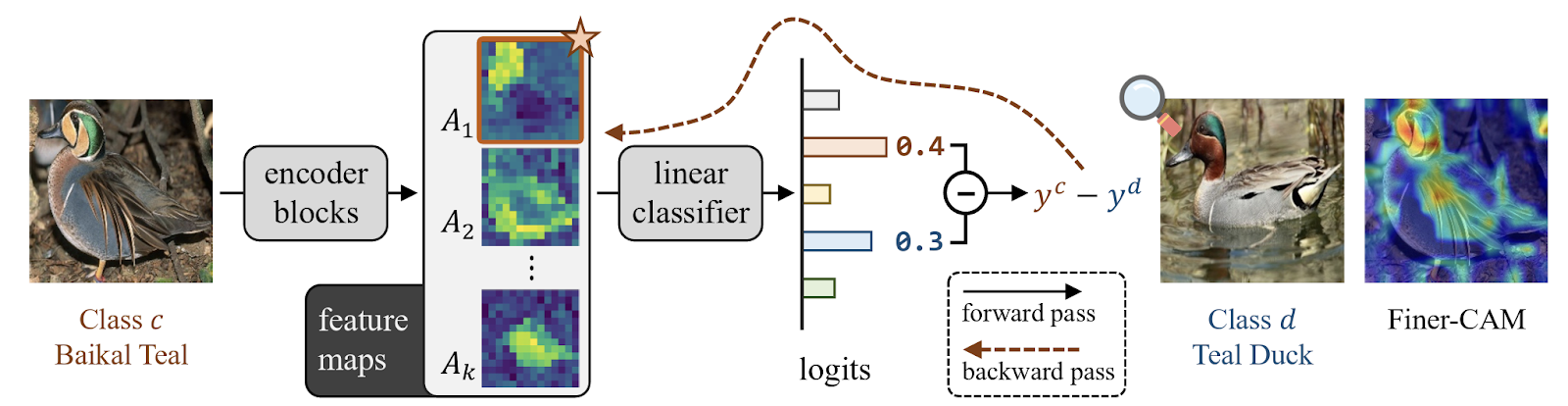
خط لوله Finer-CAM
خط لوله روششناختی Finer-CAM شامل سه مرحله اصلی است:
-
استخراج ویژگی:
- یک تصویر ورودی ابتدا از بلوکهای رمزگذار شبکه عصبی عبور میکند و نقشههای ویژگی میانی را تولید میکند.
- یک طبقهبندیکننده خطی بعدی از این نقشههای ویژگی برای تولید لگاریتمهای پیشبینی استفاده میکند که اطمینان پیشبینیها را برای کلاسهای مختلف کمیسازی میکند.
-
محاسبه گرادیان (تفاوت لگاریتم):
- روشهای استاندارد CAM گرادیانها را برای یک کلاس واحد محاسبه میکنند.
- Finer-CAM گرادیانها را بر اساس تفاوت بین لگاریتمهای پیشبینی کلاس هدف و یک کلاس بصری مشابه محاسبه میکند.
- این مقایسه، ویژگیهای بصری ظریفی را که به طور خاص برای کلاس هدف متمایز کننده هستند، با سرکوب ویژگیهای مشترک، شناسایی میکند.
-
برجستهسازی فعالسازی:
- گرادیانهای محاسبهشده از تفاوت لگاریتم برای تولید نقشههای فعالسازی کلاس بهبودیافته استفاده میشوند که بر جزئیات بصری متمایزکننده و حیاتی برای تشخیص بین دستههای مشابه تأکید میکنند.
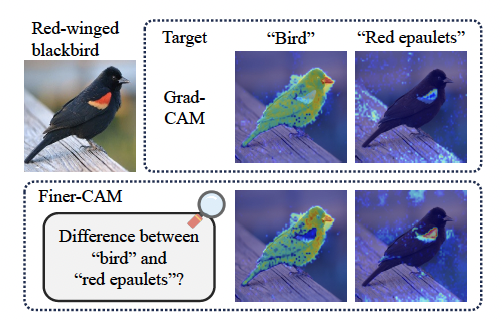
اعتبارسنجی تجربی
B.1. دقت مدل
محققان Finer-CAM را در دو شبکه عصبی محبوب، CLIP و DINOv2، ارزیابی کردند. آزمایشها نشان داد که DINOv2 به طور کلی تعبیههای بصری با کیفیت بالاتری تولید میکند و در مقایسه با CLIP در تمام مجموعه دادههای آزمایششده، به دقت طبقهبندی بالاتری دست مییابد.

B.2. نتایج در FishVista و Aircraft
ارزیابیهای کمی در مجموعه دادههای FishVista و Aircraft کارایی Finer-CAM را بیشتر نشان میدهد. در مقایسه با روشهای پایه CAM (Grad-CAM، Layer-CAM، Score-CAM)، Finer-CAM به طور مداوم معیارهای عملکرد بهبودیافتهای را ارائه میدهد، به ویژه در افت اطمینان نسبی و دقت محلیسازی، که بر توانایی آن در برجسته کردن جزئیات متمایزکننده حیاتی برای طبقهبندی ریزدانه تأکید میکند.
B.3. نتایج در DINOv2
ارزیابیهای بیشتر با استفاده از DINOv2 به عنوان شبکه اصلی نشان داد که Finer-CAM به طور مداوم از روشهای پایه بهتر عمل میکند. این نتایج نشان میدهد که روش مقایسهای Finer-CAM به طور موثر عملکرد محلیسازی و قابلیت تفسیر را افزایش میدهد. با توجه به دقت بالای DINOv2، پیکسلهای بیشتری باید پوشانده شوند تا به طور قابل توجهی بر پیشبینیها تأثیر بگذارند، که منجر به مقادیر AUC حذف بزرگتر و گاهی اوقات افت اطمینان نسبی کوچکتر در مقایسه با CLIP میشود.
مزایای بصری و کمی
- محلیسازی بسیار دقیق: به طور واضح ویژگیهای بصری متمایزکننده را مشخص میکند، مانند الگوهای رنگآمیزی خاص در پرندگان، عناصر ساختاری دقیق در خودروها، و تغییرات ظریف طراحی در هواپیما.
- کاهش نویز پسزمینه: به طور قابل توجهی فعالسازیهای پسزمینه نامربوط را کاهش میدهد و ارتباط توضیحات را افزایش میدهد.
- برتری کمی: از رویکردهای سنتی CAM (Grad-CAM, Layer-CAM, Score-CAM) در معیارهایی از جمله افت اطمینان نسبی و دقت محلیسازی پیشی میگیرد.

قابل توسعه به سناریوهای یادگیری چندوجهی بدون نمونه (Zero-Shot)
Finer-CAM قابل توسعه به سناریوهای یادگیری چندوجهی بدون نمونه است. با مقایسه هوشمندانه ویژگیهای متنی و بصری، به طور دقیق مفاهیم بصری را در تصاویر محلیسازی میکند، که به طور قابل توجهی قابلیت کاربرد و تفسیرپذیری آن را گسترش میدهد.

محققان کد منبع و نسخه نمایشی Colab Finer-CAM را در دسترس قرار دادهاند.
برای اطلاعات بیشتر میتوانید به مقاله، گیتهاب و نسخه نمایشی Colab مراجعه کنید. تمام اعتبار این تحقیق متعلق به محققان این پروژه است. همچنین، میتوانید ما را در توییتر دنبال کنید و فراموش نکنید که به سابردیت 80 هزار نفری ML ما بپیوندید.