بهبود تواناییهای استدلالی مدلهای زبانی بزرگ (LLM) به یکی از داغترین موضوعات در سال 2025 تبدیل شده است و دلیل خوبی هم دارد. مهارتهای استدلالی قویتر به LLMها اجازه میدهد تا با مسائل پیچیدهتری مقابله کنند و آنها را در طیف وسیعی از وظایفی که کاربران به آنها اهمیت میدهند، توانمندتر میسازد.
در چند هفته گذشته، محققان تعداد زیادی استراتژی جدید برای بهبود استدلال به اشتراک گذاشتهاند، از جمله مقیاسبندی محاسبات زمان استنتاج، یادگیری تقویتی، تنظیم دقیق نظارتشده و تقطیر. و بسیاری از رویکردها این تکنیکها را برای تأثیر بیشتر ترکیب میکنند.
این مقاله به بررسی پیشرفتهای اخیر تحقیقاتی در مدلهای LLM بهینهسازیشده برای استدلال میپردازد، با تمرکز ویژه بر مقیاسبندی محاسبات زمان استنتاج که از زمان انتشار DeepSeek R1 پدیدار شدهاند.
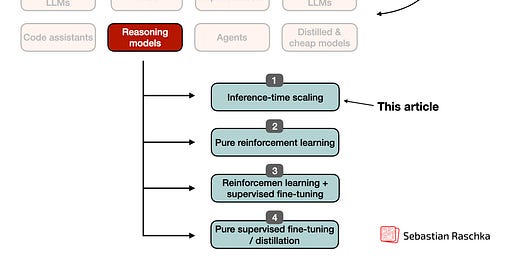
پیادهسازی و بهبود استدلال در LLMها: چهار دسته اصلی
از آنجایی که اکثر خوانندگان احتمالاً قبلاً با مدلهای استدلالی LLM آشنا هستند، تعریف را کوتاه نگه میدارم: یک مدل استدلالی مبتنی بر LLM یک LLM است که برای حل مسائل چند مرحلهای با تولید مراحل میانی یا فرآیندهای فکری ساختاریافته طراحی شده است. برخلاف LLMهای ساده پاسخدهی به سؤال که فقط پاسخ نهایی را به اشتراک میگذارند، مدلهای استدلالی یا به طور صریح فرآیند فکری خود را نشان میدهند یا آن را به صورت داخلی مدیریت میکنند، که به آنها کمک میکند تا در وظایف پیچیده مانند پازلها، چالشهای کدنویسی و مسائل ریاضی عملکرد بهتری داشته باشند.

به طور کلی، دو استراتژی اصلی برای بهبود استدلال وجود دارد: (۱) افزایش محاسبات آموزش یا (۲) افزایش محاسبات استنتاج، که به عنوان مقیاسبندی زمان استنتاج یا مقیاسبندی زمان آزمایش نیز شناخته میشود. (محاسبات استنتاج به قدرت پردازش مورد نیاز برای تولید خروجیهای مدل در پاسخ به یک پرسوجوی کاربر پس از آموزش اشاره دارد.)
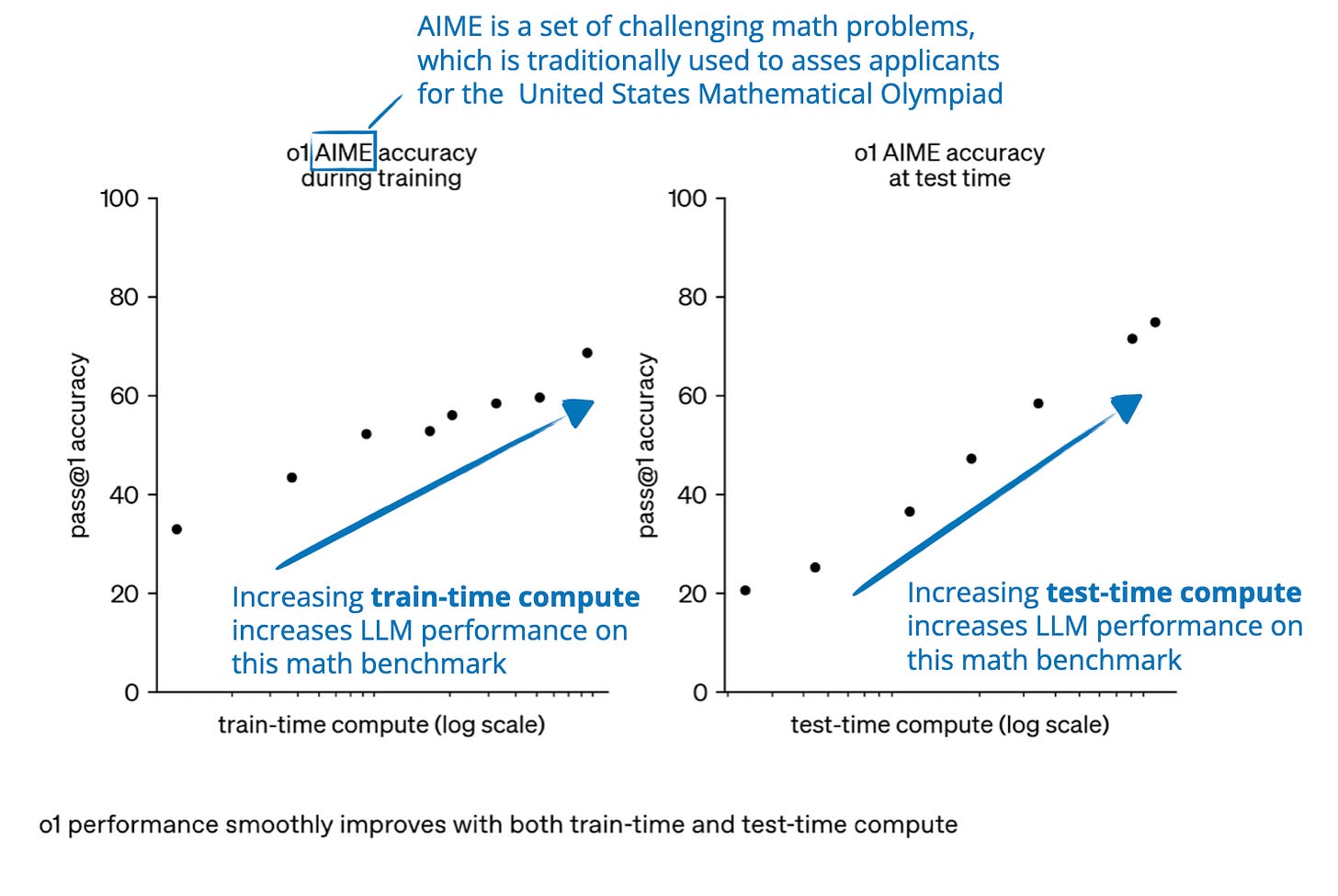
توجه داشته باشید که نمودارهای نشان داده شده در بالا اینطور به نظر میرسند که ما استدلال را یا از طریق محاسبات زمان آموزش یا محاسبات زمان آزمایش بهبود میبخشیم. با این حال، LLMها معمولاً برای بهبود استدلال با ترکیب محاسبات سنگین زمان آموزش (آموزش گسترده یا تنظیم دقیق، اغلب با یادگیری تقویتی یا دادههای تخصصی) و افزایش محاسبات زمان آزمایش (اجازه دادن به مدل برای "فکر کردن طولانیتر" یا انجام محاسبات اضافی در طول استنتاج) طراحی میشوند.
با توجه به این موضوع، دسته اصلی سوم از رویکردهای مقیاسبندی استنتاج، که محاسبات استنتاج را افزایش میدهد، روشهای تکراری هستند. در این سناریو، خروجی مدل به عنوان ورودی به همان مدل برای بهبود پیشبینی استفاده میشود. یک روش تکراری مرتبط، که اغلب با رویکردهای تکراری اشتباه گرفته میشود، استفاده از معماریهای خاص با حلقههای بازخورد است که پیشبینی را پالایش میکنند. در اینجا، یک یا چند بلوک از مدل اصلی به خروجی خود بازخورد میکنند. سرانجام، یک دسته چهارم وجود دارد، رویکردهای گروهی، که چندین مدل را برای دستیابی به اجماع ترکیب میکند.