
مدلهای زبانی بزرگ (LLM) مانند GPT-4 در واقع چیزی «نمیدانند»، آنها کلمات را بر اساس دادههای آموزشی قدیمی پیشبینی میکنند. تولید افزوده شده با بازیابی (RAG) این وضعیت را تغییر میدهد و به هوش مصنوعی اجازه میدهد قبل از پاسخ دادن، دانش تازه و دنیای واقعی را وارد کند.
RAG مدلهای زبانی بزرگ را با فعال کردن آنها برای بازیابی اطلاعات مرتبط از منابع خارجی قبل از تولید پاسخ، بهبود میبخشد. از آنجا که LLMها به دادههای آموزشی ایستا متکی هستند و به طور خودکار به روز نمیشوند، RAG به آنها امکان دسترسی به دانش تازه، خاص دامنه یا خصوصی را میدهد، بدون نیاز به آموزش مجدد پرهزینه.
بیایید بررسی کنیم که RAG چگونه کار میکند، چرا مفید است و چگونه با درخواستهای سنتی LLM متفاوت است.
تولید افزوده شده با بازیابی (RAG) در هوش مصنوعی چیست؟
تولید افزوده شده با بازیابی (RAG) به مدلهای هوش مصنوعی کمک میکند قبل از تولید پاسخ، اطلاعات خارجی را بازیابی کنند. اما دقیقاً این فرآیند چگونه کار میکند و چرا مهم است؟
مدلهای زبانی بزرگ در بسیاری از وظایف عالی هستند. آنها میتوانند کدنویسی کنند، ایمیل پیشنویس کنند، مواد لازم برای ساندویچ عالی را توهم کنند و حتی مقاله بنویسند، اگرچه من هنوز ترجیح میدهم خودم این کار را انجام دهم. با این حال، آنها یک محدودیت عمده دارند. آنها فاقد دانش زمان واقعی هستند. از آنجا که آموزش LLMها یک فرایند زمانبر است، آنها در مورد رویدادهای اخیر "نمیدانند". اگر از آنها در مورد هفته گذشته سوال کنید، یا سلب مسئولیت نشان میدهند، یا پاسخ قدیمی ارائه میدهند، یا چیزی کاملاً نادرست تولید میکنند.
"برخی از LLMها با بازیابی اطلاعات به روز قبل از پاسخ دادن، بر بزرگترین محدودیت خود یعنی دادههای آموزشی منسوخ غلبه میکنند."
RAG قبل از تولید پاسخ، اطلاعات مرتبط را دریافت میکند و پاسخهای هوش مصنوعی را دقیقتر میکند و توهمات را کاهش میدهد.
RAG به زبان ساده توضیح داده شد
اما RAG واقعاً چگونه کار میکند؟ به جای اینکه خودمان آن را جستجو کنیم، بیایید از LLM مورد علاقه خود بپرسیم:

این دقیقاً چیزی نبود که ما انتظار داشتیم. مشکلی نیست، میتوانیم به جای آن از باب بپرسیم.

تعجب آور است که باب هم جواب را نمیدانست، اما توانست آن را بازیابی کند. در اینجا اتفاقی که افتاد آمده است:
- ما در مورد RAG از باب پرسیدیم.
- باب به کتابخانه رفت و از کتابدار اطلاعات خواست.
- کتابدار او را به راهروی مناسب راهنمایی کرد.
- باب اطلاعات را بازیابی کرد.
- باب درک خود را با مصرف اطلاعات قبل از تولید پاسخ افزایش داد.
- حالا باب مانند یک متخصص به نظر میرسد. ممنون، باب.
این تجزیه و تحلیل نشان میدهد که باب به طور موثر به عنوان یک عامل RAG عمل میکند.
با این بینش، بیایید دقیقاً بررسی کنیم که یک عامل RAG چگونه عمل میکند.
RAG - ساده شده
بیایید تعامل خود با باب را به یک سیستم RAG واقعی تبدیل کنیم:
- باب نشان دهنده سیستم RAG است.
- کتابدار به عنوان یک تعبیهگر عمل میکند.
- کتابخانه به عنوان یک پایگاه داده برداری عمل میکند.

"به جای درخواست مستقیم از یک LLM، یک سیستم RAG به عنوان یک پل دانش عمل میکند: بازیابی، افزایش و سپس تولید پاسخ."
برداری کردن ورودی
سیستم RAG سپس درخواست را به تعبیهگر ارسال میکند، که آن را به یک بردار تبدیل میکند. این بردار یک نمایش عددی از درخواست است. ایده این است که اطلاعات با معنای مشابه دارای نمایشهای برداری مشابه خواهند بود.
"بردارها قفل ارتباط را باز میکنند. این بردار به سیستم اجازه میدهد تا معنادارترین اطلاعات را از پایگاه داده برداری بازیابی کند."
وقتی نمایش برداری درخواست کاربر به پایگاه داده ارسال میشود، مرتبطترین مطابقتها را بازیابی میکند.
سیستم RAG سپس درخواست کاربر را با گنجاندن اطلاعات بازیابی شده افزایش میدهد:
<context>
اطلاعات برگشت داده شده از پایگاه داده
</context>
<user-prompt>
درخواست اصلی کاربر
</user-prompt>
این تمام فرایند است. بازیابی، افزایش و تولید. RAG.
اضافه کردن به پایگاه دانش
با این حال، سیستم نمیتواند اطلاعاتی را که به پایگاه داده اضافه نشده است بازیابی کند. چگونه دادههای جدید را ذخیره کنیم؟ این فرآیند ساده است. به جای استفاده از بردار برای یافتن اطلاعات مرتبط، سیستم دادهها را به همراه نمایش برداری آن ذخیره میکند.

اگر فقط به تصویر بزرگ علاقهمند بودید، تبریک میگویم. اکنون مفهوم اصلی را درک میکنید. با این حال، اگر شما هم یک گردنریش هستید، بیایید کمی بیشتر در مورد بردارها و تعبیهگرها صحبت کنیم.
بردار چیست؟
به زبان ساده، یک بردار مجموعهای از مختصات است که نحوه حرکت از A به B را توصیف میکند. به این نمودار نگاه کنید:

این نمودار دو بعد دارد. هر نقطه، A، B، C و D را میتوان با استفاده از یک سیستم مختصات دو عددی توصیف کرد. عدد اول به ما میگوید که چقدر باید به سمت راست از مبدأ (0) حرکت کنیم، در حالی که عدد دوم به ما میگوید که چقدر باید به سمت بالا حرکت کنیم. برای رسیدن به A، بردار [3, 7] است. برای رسیدن به D، بردار [3, 0] است.
ابعاد بردارها
همین اصل در سه بعد نیز صدق میکند. برای حرکت از میز خود به دستگاه قهوه، باید فاصله معینی را در امتداد محورهای x، y و z طی کنید و یک سیستم مختصات سه رقمی را تشکیل دهید.

"انسانها برای تجسم فراتر از سه بعد تلاش میکنند. کامپیوترها در فضاهای چند بعدی پیشرفت میکنند."
ریاضیات یکسان باقی میماند. چهار بعد؟ این به یک سیستم مختصات چهار رقمی نیاز دارد. صد بعد؟ این به یک سیستم مختصات 100 رقمی نیاز دارد.

"تعبیهگری که من استفاده میکنم در یک سیستم مختصات خمکننده ذهن و 768 بعدی کار میکند، بسیار فراتر از درک انسان."
وقتی تجسم آن را تمام کردید، میتوانیم به نمودارهای سادهتر و آسانتر دو بعدی بازگردیم.
چگونه تعبیههای برداری به LLMها در بازیابی دادهها کمک میکنند
بردارها به خودی خود صرفاً مختصات n بعدی هستند که نقاط را در فضای n بعدی نشان میدهند.
"بردارها فقط اعداد نیستند، آنها معنی را رمزگذاری میکنند. قدرت واقعی آنها در اطلاعاتی است که نشان میدهند."
به همین ترتیب، بردارها مختصات مکانها نیستند، بلکه مختصات اطلاعات هستند. یک LLM تخصصی، یک تعبیهگر، بر روی مجموعه بزرگی از متن آموزش داده شده است تا شباهتها را تشخیص دهد و این قطعات اطلاعات را در جایی در فضای n بعدی قرار دهد، به طوری که موضوعات مشابه تمایل دارند با هم گروهبندی شوند.
مثلاً وقتی به یک رویداد اجتماعی میروید، احتمالاً با دوستان، همکاران یا حداقل گروهی از افراد همفکر خود میمانید.
گروهبندی مفاهیم مشابه با هم

این نمودار نشان میدهد که چگونه کلماتی که از نظر معنی مشابه هستند، تمایل دارند در این فضای n بعدی با هم گروهبندی شوند. تعبیهگرهای مدرن (مانند BERT) دیگر از تعبیههای تک کلمهای استفاده نمیکنند، بلکه تعبیههای متنی ایجاد میکنند.
توانایی گروهبندی مفاهیم مشابه در فضای برداری، تعبیهها را قدرتمند میکند. با این حال، مدلهای تعبیهسازی اولیه مانند Word2Vec دارای محدودیت قابل توجهی بودند که مدلهای مدرن به آن پرداختهاند.
مماس فنی سریع
اگر به اندازه من روی سیستمهای هوش مصنوعی کار کردهاید، ممکن است با Word2Vec آشنا باشید. در حالی که هنگام عرضه در سال 2013 پیشگامانه بود، یک نقص عمده دارد: این نرم افزار یک بردار واحد به هر کلمه، بدون توجه به زمینه اختصاص میدهد.
کلمه "bat" را در نظر بگیرید.
- آیا در مورد پستاندار پرنده صحبت میکنیم؟ سپس باید نزدیک "پستاندار"، "غار" و "شب زی" باشد.
- یا منظور ما چوب بیس بال است؟ سپس باید نزدیک "توپ"، "زمین" و "پایه" باشد (اما کدام پایه؟ نظامی؟)
- و اگر در دنیای تخیلی باشیم چه؟ سپس "bat" مربوط به "خون آشام" و "تغییر شکل" است.
Word2Vec نمیتواند تفاوت را تشخیص دهد. یکی را انتخاب میکند و به آن میچسبد.
یکی از چیزهایی که من به طور خاص با Word2Vec جذاب میدانم این است که، از آنجایی که کلمات اکنون با اعداد نشان داده میشوند، میتوانید در واقع روی آنها محاسبات انجام دهید.
شما میتوانید معادلات زیر را بسازید
"king - man + woman = queen- یک مثال افسانهای از نحوه نقشهبرداری مدلهای هوش مصنوعی از روابط در فضای برداری."
این وحشیانه است، اما کار میکند (بیشتر اوقات).
مماس تمام شد.
چگونه از بردارها استفاده میشود؟
اکنون که بردارها را درک میکنیم، مرحله بعدی ساده است. ما اطلاعاتی را که میخواهیم LLM به آن دسترسی داشته باشد، تعبیه میکنیم و وقتی در مورد آن اطلاعات سوال میپرسیم، خود سوال باید به محتوای مربوطه در فضای برداری نزدیک باشد. پایگاه داده برداری n مرتبطترین قطعه محتوا را بازیابی میکند، جایی که n یک عدد قابل تنظیم است.
همچنین امتیاز شباهت کسینوسی را برای هر نتیجه برمیگرداند، که نشان میدهد محتوای بازیابی شده چقدر با پرس و جو مطابقت دارد.
شباهت کسینوسی
"شباهت کسینوسی فقط اعداد را مقایسه نمیکند، بلکه با محاسبه زاویه بین دو بردار، معنی را اندازهگیری میکند."
زاویه کوچکتر نشان دهنده شباهت بیشتر است، به این معنی که دادههای بازیابی شده بیشتر به درخواست مربوط هستند.
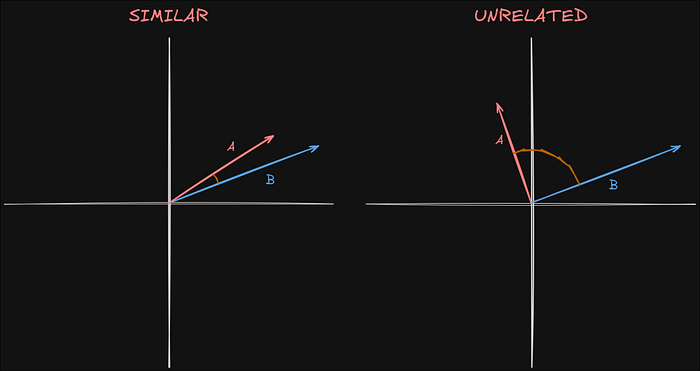
در مثال ما، A و B عبارات "RAG مخفف تولید افزوده شده با بازیابی است" و "هی LLM، در مورد RAG به من بگو" را نشان میدهند. از آنجایی که آنها ارتباط نزدیکی دارند، بردارهای آنها مشابه هستند. اگر به جای آن بپرسیم "یک خورشید گرفتگی را توصیف کن"، بردار آن از بقیه دور خواهد بود و آن را نامربوط میکند. با این حال، اگر "RAG مخفف تولید افزوده شده با بازیابی است" تنها ورودی در پایگاه داده باشد، باز هم بازیابی خواهد شد، حتی اگر به درخواست مربوط نباشد.
محدودیتهای RAG
به طور معمول، ما کل اسناد را در پایگاه داده برداری ذخیره و بازیابی نمیکنیم. اگر این کار را انجام دهیم، یک سند بزرگ به راحتی میتواند از پنجره زمینه LLM فراتر رود. اگر سیستم برای بازگرداندن ده قطعه اطلاعات مربوطه پیکربندی شده باشد، و هر یک از آنها به اندازه یک مقاله کامل باشد، رایانه شما به سرعت به یک بخاری فضایی تبدیل میشود. برای جلوگیری از این امر، اطلاعات را به قطعاتی با اندازه از پیش تعریف شده، مانند 1000 کاراکتر تقسیم میکنیم و سعی میکنیم جملات و پاراگرافها را دست نخورده نگه داریم.
با این حال، تقسیم اطلاعات به قطعات یک مشکل جدید را معرفی میکند. همانطور که Word2Vec برای تعیین معنی از یک کلمه واحد تلاش میکند، RAG اغلب در درک زمینه کامل یک قطعه واحد، به ویژه هنگامی که آن قطعه از وسط یک سند استخراج شده باشد، با شکست مواجه میشود.

در اینجا مشکلی وجود دارد که اخیراً با آن مواجه شدم. من یک دفتر خاطرات کار دقیق دارم که در آن تمام دستاوردهای حرفهای خود را ثبت میکنم. در بررسی عملکرد بسیار مفید است. با این حال، وقتی از سیستم RAG خود میپرسم که در شرکت فعلیام به چه دستاوردهایی رسیدهام، با اطمینان دستاوردهای مشاغل قبلیام را نیز شامل میشود. از آنجا که من این دفتر خاطرات را به صورت اول شخص مینویسم و همچنین اطلاعاتی را از منابع دیگر که به صورت اول شخص نوشته شدهاند، در بر میگیرم، سیستم نمیتواند بین آنها تمایز قائل شود. در نتیجه، شروع به نسبت دادن دستاوردهایی به من میکند که هیچ ربطی به آنها نداشتهام. اینگونه بود که فهمیدم مشکلی وجود دارد. سیستم من ناگهان به من میگفت که تمام کارهای جالبی که ظاهراً دور از رایانه انجام دادهام، که غیرممکن است زیرا من هرگز میز خود را ترک نمیکنم.
نتیجهگیری
RAG با اجازه دادن به LLMها برای بازیابی اطلاعاتی که در غیر این صورت به آنها دسترسی نداشتند، آنها را مفیدتر میکند. اما این جادو نیست. چالشهای خاص خود را دارد، از رسیدگی صحیح به زمینه گرفته تا اجتناب از نتایج نامربوط.
اما همانطور که من شخصاً آموختم، دریافت اطلاعات به معنای درک آن نیست. به همین دلیل است که آگاه کردن سیستمهای RAG از زمینه چالش بزرگ بعدی است، چالشی که در مقاله بعدی خود به آن خواهم پرداخت.