
BIG-Bench که در سال 2021 به عنوان یک بنچمارک جهانی برای آزمایش مدلهای زبانی بزرگ توسعه یافت، با دستیابی مدلهای فعلی به دقت بیش از 90 درصد، به محدودیتهای خود رسیده است. در پاسخ، Google DeepMind، BIG-Bench Extra Hard (BBEH) را معرفی کرده است که ضعفهای اساسی را حتی در پیشرفتهترین مدلهای هوش مصنوعی نشان میدهد.
BBEH بر اساس نسخه قبلی خود، BIG-Bench Hard (BBH)، با جایگزینی هر یک از 23 وظیفه اصلی با نسخههای بسیار چالشبرانگیزتر ساخته شده است. این وظایف جدید به طیف گستردهتری از تواناییهای استدلال نیاز دارند و به طور متوسط شش برابر طولانیتر از وظایف BBH هستند. این افزایش پیچیدگی در پاسخهای مدلهای هوش مصنوعی منعکس میشود، که معمولاً هفت برابر طولانیتر از پاسخهای BBH هستند.
بنچمارک جدید، قابلیتهای استدلال اضافی را آزمایش میکند، از جمله مدیریت و استدلال در وابستگیهای متنی بسیار طولانی، یادگیری مفاهیم جدید، تمایز بین اطلاعات مرتبط و نامربوط و یافتن خطاها در زنجیرههای استدلال از پیش تعریف شده.
دو مثال، پیچیدگی بنچمارک را برجسته میکنند. در وظیفه "استدلال فضایی"، یک عامل در یک ساختار هندسی حرکت میکند و اشیاء را در موقعیتهای مختلف مشاهده میکند. مدلها باید مکان اشیاء را ردیابی کرده و در مورد روابط آنها نتیجهگیری کنند.
آزمایش "ویژگیهای شیء" مجموعهای از اشیاء با ویژگیهای مختلف (رنگ، اندازه، منشاء، بو و جنس) را ارائه میدهد که دچار تغییراتی میشوند. مدلها باید تمام ویژگیهای شیء را در هر بهروزرسانی ردیابی کنند، از جمله سناریوهای دشواری مانند گم شدن یک شیء نامشخص با ویژگیهای خاص.
o3 mini با اختلاف غیرمنتظرهای R1 را شکست داد
Google DeepMind هم مدلهای هدف کلی مانند Gemini 2.0 Flash و GPT-4o و هم مدلهای استدلال تخصصی مانند o3-mini (high) و DeepSeek R1 را آزمایش کرد. نتایج، محدودیتهای قابل توجهی را آشکار کرد: بهترین مدل هدف کلی (Gemini 2.0 Flash) تنها به دقت متوسط 9.8 درصد دست یافت، در حالی که بهترین مدل استدلال (o3-mini high) تنها به دقت متوسط 44.8 درصد رسید. GPT-4.5 هنوز آزمایش نشده است.
این تحلیل، تفاوتهای مورد انتظار بین مدلهای استدلال عمومی و تخصصی را نشان داد. مدلهای تخصصی به ویژه در مسائل رسمی شامل شمارش، برنامهریزی، محاسبات و ساختارهای داده عملکرد خوبی داشتند. با این حال، برتری آنها در وظایفی که نیاز به عقل سلیم، شوخطبعی، کنایه و درک علّی داشتند، کاهش یافت یا ناپدید شد.
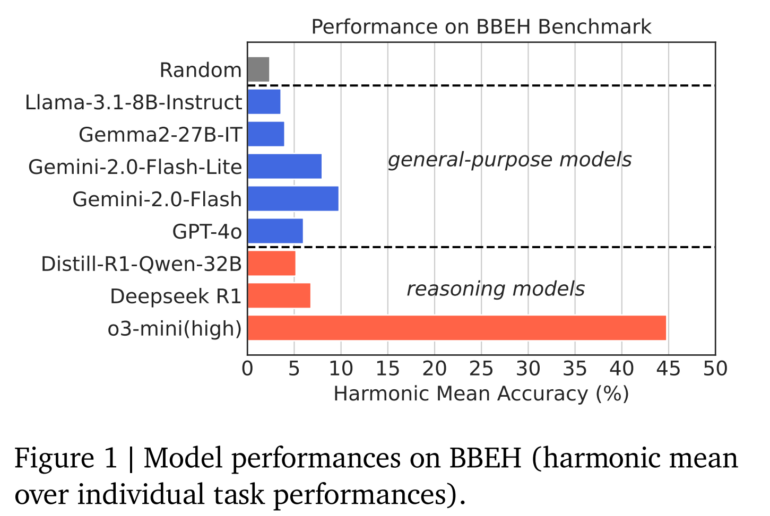
به طور خاص، o3-mini (high) شرکت OpenAI به طور قابل توجهی از DeepSeek R1 که بسیار مورد بحث قرار گرفته بود، بهتر عمل کرد. مدل چینی با چندین بنچمارک مشکل داشت، از جمله شکست کامل در آزمایش "ویژگیهای شیء". محققان این موضوع را عمدتاً به از دست دادن ردیابی مدل در هنگام عدم توانایی در حل مسئله در طول خروجی مؤثر آن نسبت میدهند. R1 تنها به دقت متوسط 6.8 درصد دست یافت و سه درصد از Gemini 2.0 Flash عقبتر بود.
بینشهای عملکرد و پیامدهای آینده
این تحقیق نشان داد که مدلهای استدلال تخصصی با افزایش طول متن و پیچیدگی تفکر، مزایای بیشتری نسبت به مدلهای عمومی کسب میکنند. به طور مشابه، مدلهای عمومی بزرگتر مانند Gemini 2.0 Flash هنگام برخورد با متون طولانیتر، مزایایی نسبت به مدلهای کوچکتر مانند Flash-Lite نشان میدهند.
در حالی که LLMهای مدرن پیشرفتهای چشمگیری داشتهاند، BBEH نشان میدهد که آنها هنوز از دستیابی به توانایی استدلال عمومی فاصله زیادی دارند. محققان تأکید میکنند که هنوز کارهای اساسی برای پر کردن این شکافها و توسعه سیستمهای هوش مصنوعی تطبیقپذیرتر مورد نیاز است.
این بنچمارک به صورت عمومی در آدرس زیر در دسترس است: https://github.com/google-deepmind/bbeh
خلاصه
- Google DeepMind، BIG-Bench Extra Hard (BBEH) را معرفی میکند، یک بنچمارک جدید و به طور قابل توجهی چالشبرانگیزتر برای مدلهای زبانی بزرگ، زیرا مدلهای برتر فعلی در حال حاضر به دقت بیش از 90 درصد با BIG-Bench و BIG-Bench Hard دست مییابند.
- آزمایشها با مدلهای مختلف، ضعفهای آشکاری را نشان میدهد: بهترین مدل هدف کلی، Gemini 2.0 Flash، تنها به دقت 9.8 درصد دست مییابد، در حالی که بهترین مدل استدلال، o3-mini (high)، به 44.8 درصد میرسد. مدل چینی DeepSeek R1 با 6.8 درصد دقت به طور شگفتانگیزی از Gemini 2.0 Flash عقبتر است و اصلاً نمیتواند برخی از وظایف را حل کند.
- مدلهای استدلال تخصصی مانند o3-mini به ویژه در مسائل رسمی از مدلهای عمومی بهتر عمل میکنند. برای وظایفی که نیاز به عقل سلیم، شوخطبعی و درک علّی دارند، برتری آنها کمتر است.
منبع: Arxiv