مدلهای زبان بزرگ (LLM) به دلیل محدودیتهای حفظ دانش پارامتری، در یادگیری مداوم با چالشهایی مواجه هستند که منجر به پذیرش گسترده RAG به عنوان یک راه حل شده است. RAG مدلها را قادر میسازد تا بدون تغییر پارامترهای داخلی خود به اطلاعات جدید دسترسی پیدا کنند، که آن را به یک رویکرد عملی برای انطباق در زمان واقعی تبدیل میکند. با این حال، چارچوبهای RAG سنتی به شدت به بازیابی برداری متکی هستند، که توانایی آنها را در گرفتن روابط و تداعیهای پیچیده در دانش محدود میکند. پیشرفتهای اخیر دادههای ساختاریافته، مانند نمودارهای دانش، را برای افزایش قابلیتهای استدلال ادغام کردهاند، که باعث بهبود درک معنا و ارتباطات چند مرحلهای میشود. در حالی که این روشها بهبودهایی در درک متنی ارائه میدهند، اغلب عملکرد را در وظایف سادهتر یادآوری واقعی به خطر میاندازند، که نیاز به رویکردهای دقیقتری را برجسته میکند.
استراتژیهای یادگیری مداوم برای LLMها معمولاً به سه دسته تقسیم میشوند: تنظیم دقیق مداوم، ویرایش مدل و بازیابی غیرپارامتری. تنظیم دقیق به طور دورهای پارامترهای مدل را با دادههای جدید بهروز میکند، اما از نظر محاسباتی پرهزینه است و مستعد فراموشی فاجعهبار است. ویرایش مدل پارامترهای خاصی را برای بهروزرسانیهای دانش هدفمند تغییر میدهد، اما اثرات آن موضعی باقی میماند. در مقابل، RAG به طور پویا اطلاعات خارجی مرتبط را در زمان استنتاج بازیابی میکند و امکان بهروزرسانیهای کارآمد دانش را بدون تغییر پارامترهای مدل فراهم میکند. چارچوبهای پیشرفته RAG، مانند GraphRAG و LightRAG، با ساختاربندی دانش در نمودارها، بازیابی را افزایش میدهند و توانایی مدل را در ترکیب اطلاعات پیچیده بهبود میبخشند. HippoRAG 2 این رویکرد را با استفاده از بازیابی ساختاریافته و در عین حال به حداقل رساندن خطاها از نویز تولید شده توسط LLM، اصلاح میکند و بین درک معنا و دقت واقعی تعادل برقرار میکند.
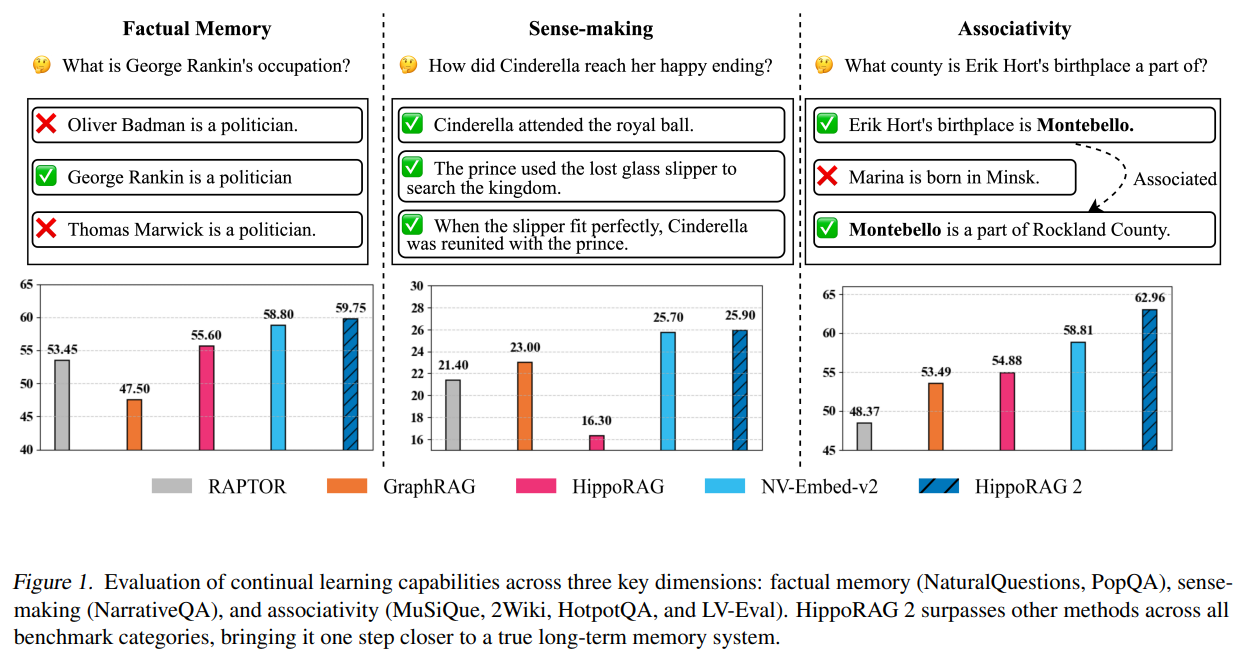
HippoRAG 2، که توسط محققان دانشگاه ایالتی اوهایو و دانشگاه ایلینوی در Urbana-Champaign توسعه یافته است، با بهبود یادآوری واقعی، درک معنا و حافظه تداعیگر، RAG را افزایش میدهد. با تکیه بر الگوریتم Personalized PageRank HippoRAG، گذرگاهها را به طور موثرتری ادغام میکند و استفاده آنلاین از LLM را اصلاح میکند. این رویکرد به بهبود 7 درصدی در وظایف حافظه تداعیگر نسبت به مدلهای جاسازی پیشرو دست مییابد و در عین حال درک واقعی و متنی قوی را حفظ میکند. ارزیابیهای گسترده نشان میدهد که این روش در سراسر معیارهای مختلف قوی است و از روشهای RAG تقویتشده با ساختار موجود بهتر عمل میکند. HippoRAG 2 به طور قابل توجهی یادگیری مداوم غیرپارامتری را پیشرفت میدهد و سیستمهای هوش مصنوعی را به قابلیتهای حافظه بلندمدت شبیه به انسان نزدیکتر میکند.
HippoRAG 2 یک چارچوب حافظه بلندمدت الهام گرفته از زیستشناسی عصبی برای LLMها است که با بهبود یکپارچهسازی و بازیابی متن، HippoRAG اصلی را تقویت میکند. این چارچوب شامل یک نئوکورتکس مصنوعی (LLM)، یک رمزگذار ناحیه پاراهیپوکامپال و یک نمودار دانش باز (KG) است. به صورت آفلاین، یک LLM سهگانهها را از گذرگاهها استخراج میکند، مترادفها را پیوند میدهد و اطلاعات مفهومی و متنی را ادغام میکند. به صورت آنلاین، پرس و جوها با استفاده از بازیابی مبتنی بر جاسازی به سهگانههای مرتبط نگاشت میشوند و به دنبال آن Personalized PageRank (PPR) برای انتخاب آگاهانه از متن استفاده میشود. HippoRAG 2 حافظه تشخیص را برای فیلتر کردن سهگانهها و زمینهسازی عمیقتر با پیوند دادن پرس و جوها به سهگانهها معرفی میکند، که استدلال چند مرحلهای را افزایش میدهد و دقت بازیابی را برای وظایف QA بهبود میبخشد.
آرایش تجربی شامل سه دسته پایه است: (1) بازیابهای کلاسیک مانند BM25، Contriever و GTR، (2) مدلهای جاسازی بزرگ مانند GTE-Qwen2-7B-Instruct، GritLM-7B و NV-Embed-v2، و (3) مدلهای RAG تقویتشده با ساختار، از جمله RAPTOR، GraphRAG، LightRAG و HippoRAG. ارزیابی شامل سه حوزه چالش کلیدی است: QA ساده (یادآوری واقعی)، QA چند مرحلهای (استدلال تداعیگر) و درک گفتمان (درک معنا). معیارها شامل passage recall@5 برای بازیابی و امتیازات F1 برای QA است. HippoRAG 2، با بهرهگیری از Llama-3.3-70B-Instruct و NV-Embed-v2، از مدلهای قبلی بهتر عمل میکند، به ویژه در وظایف چند مرحلهای، که بازیابی و دقت پاسخ بهبود یافته را با رویکرد الهام گرفته از روانشناسی عصبی نشان میدهد.
در خاتمه، مطالعه حذف، تأثیر پیوند، ساخت نمودار و روشهای فیلتر کردن سهگانه را ارزیابی میکند و نشان میدهد که زمینهسازی عمیقتر به طور قابل توجهی عملکرد HippoRAG 2 را بهبود میبخشد. رویکرد پرس و جو به سهگانه از سایر رویکردها بهتر عمل میکند و Recall@5 را 12.5٪ نسبت به NER-to-node افزایش میدهد. تنظیم احتمالات بازنشانی در PPR گرههای عبارت و گذرگاه را متعادل میکند و بازیابی را بهینه میکند. HippoRAG 2 به طور یکپارچه با بازیابهای متراکم ادغام میشود و به طور مداوم از آنها بهتر عمل میکند. تجزیه و تحلیل کیفی استدلال چند مرحلهای برتر را برجسته میکند. به طور کلی، HippoRAG 2 با استفاده از Personalized PageRank، یکپارچهسازی عمیقتر گذرگاه و LLMها، بازیابی و استدلال را افزایش میدهد و پیشرفتهایی را در مدلسازی حافظه بلندمدت ارائه میدهد. کار آینده ممکن است بازیابی مبتنی بر نمودار را برای بهبود حافظه رویدادی در مکالمات بررسی کند.