
جستجو اولین جایزه بزرگ اینترنت بود که در حال حاضر سالانه حدود 300 میلیارد دلار درآمد دارد. سالها، شرکتهای بزرگ از طریق مقیاس بر آن تسلط داشتند: دادههای بیشتر کیفیت جستجو را بهبود میبخشد و کاربران بیشتر اهرم تبلیغاتی ایجاد میکنند. رقبای مصرفکننده مانند Neeva تلاش کردند تا پذیرش کافی کاربر را ایجاد کنند و جستجوی سازمانی به طور کلی به طور کامل شکست خورد.
اما مدلهای زبانی بزرگ و نوآوریها در استدلال عاملی - مانند DeepSeek-R1 و حالت تحقیقات عمیق اخیراً راهاندازی شده در Gemini و ChatGPT - آنچه را که در جستجو ممکن است تغییر میدهد. این پیشرفتها به شرکتها اجازه میدهند تا محصولات بسیار قدرتمندتری را با دادههای بسیار کمتری بسازند.
در حالی که Google ناپدید نمیشود، بازار جستجو در شرف تغییر بسیار زیادی است - با فرصتهای جدید هیجانانگیز در تبلیغات مصرفکننده، جستجوی خاص دامنه و زیرساخت.
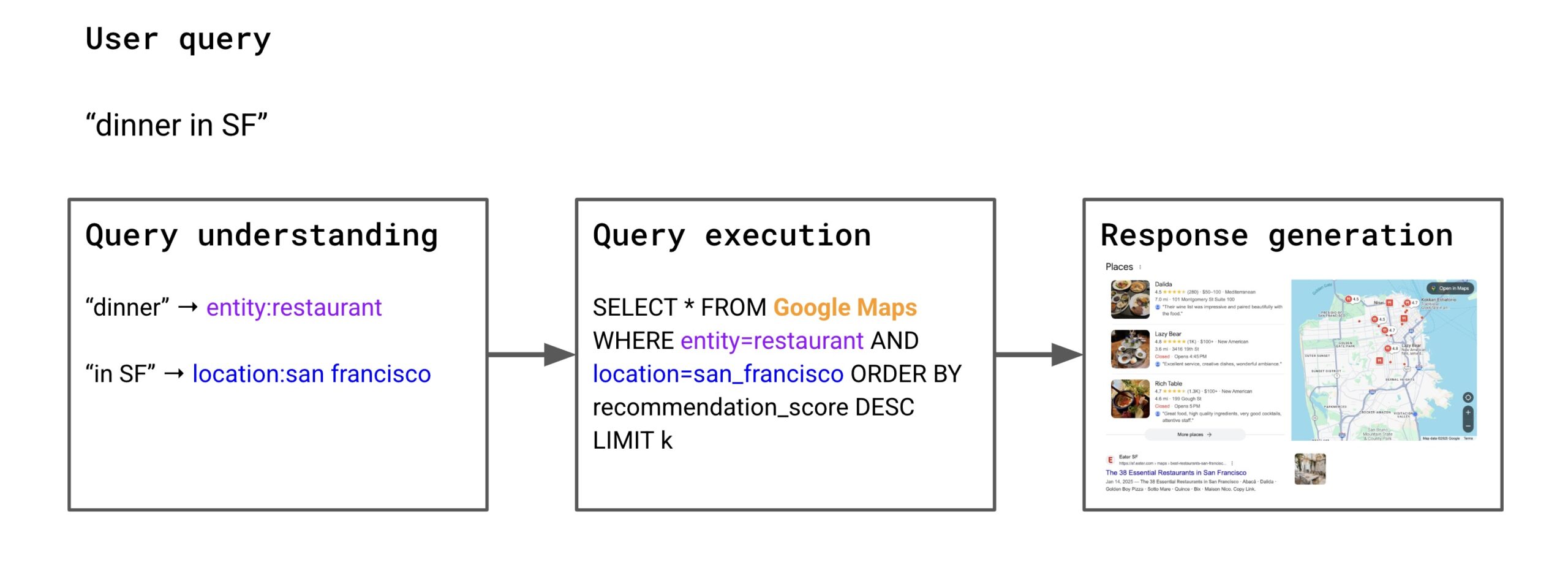
چگونه LLMها آنچه را که در جستجو ممکن است تغییر میدهند
موتورهای جستجوی سنتی به یک فرآیند چند مرحلهای از درک پرس و جو، اجرای پرس و جو و تولید پاسخ متکی هستند.

گوگل سالهاست که از مدلسازی زبان - بهویژه، تعبیههای برداری معنایی و ترانسفورماتورها - در جستجو استفاده میکند. اما LLMهای مدرن که از قبل بر روی کل اینترنت آموزش داده شدهاند، قابلیتهای جدیدی در زمینه درک زبان، بازیابی اطلاعات و استدلال اساسی دارند.
آنها به موتورهای جستجو اجازه میدهند تا:
- پرس و جوهای پیچیده فراتر از کلمات کلیدی کوتاه را درک کنند.
- نتایج را بدون نمودارهای دانش پیچیده که به میلیاردها کاربر متکی هستند، ارزیابی و رتبهبندی کنند، در عوض از مدل جهانی LLM برای تعیین اینکه کدام داده بهترین است، استفاده کنند.
- پاسخها را به منظور پاسخ مستقیم به سؤال کاربر به جای ارائه منابع متعدد، ترکیب کنند. و
- جستجوی عاملی ایجاد کنید، که یک سؤال کاربر را به چندین پرس و جو تجزیه میکند، به طور مکرر هر نتیجه را تجزیه و تحلیل میکند و یک پاسخ اصلاح شده ارائه میدهد. این رویکرد میتواند کل جریانهای کاری تحقیقاتی را که قبلاً به جستجوهای جداگانه زیادی نیاز داشت، جایگزین کند.
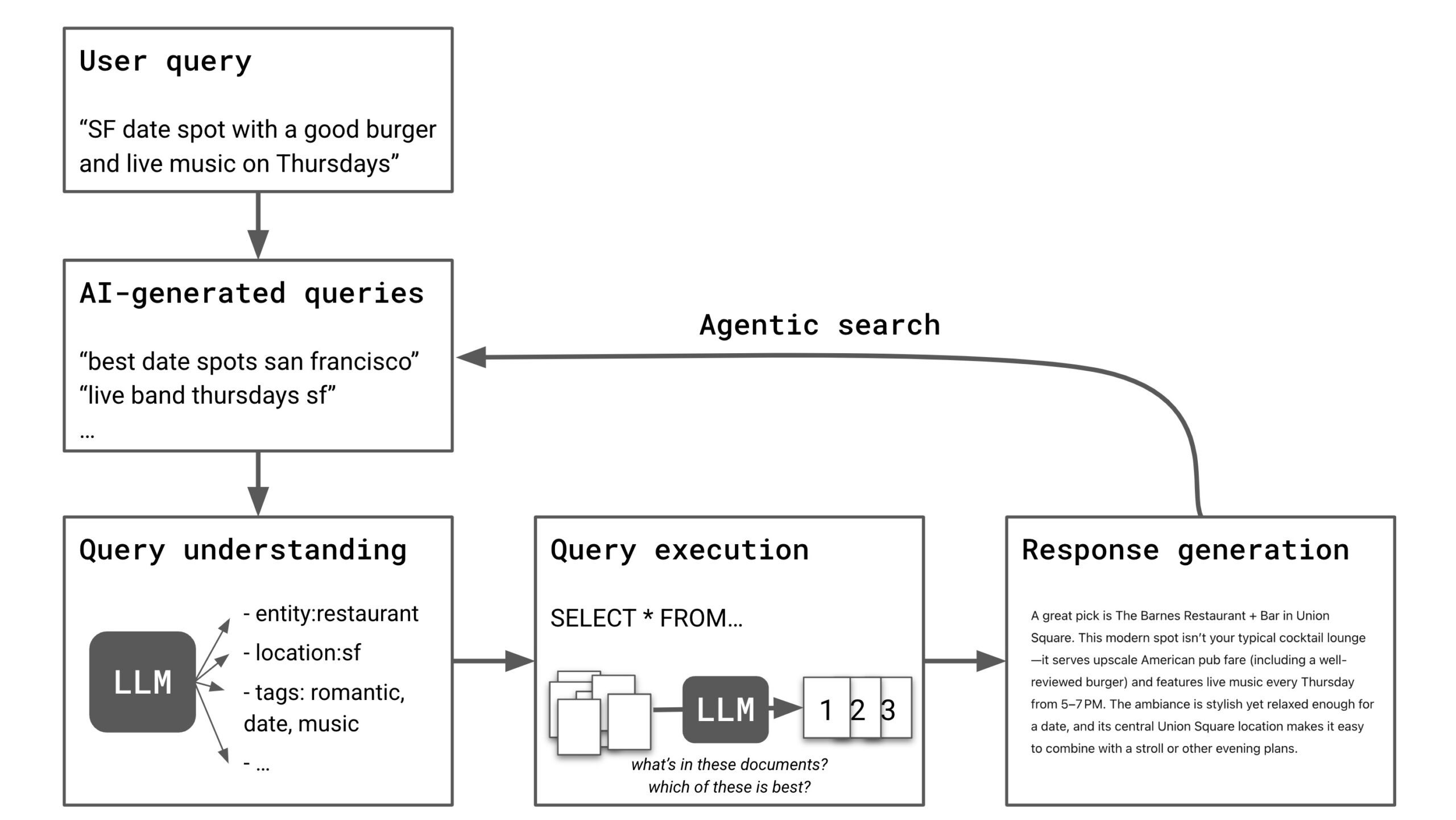
فرصتهای جدید بازار در جستجوی مبتنی بر LLM
جستجوی مبتنی بر LLM فرصتهای جدید بازار را در سه حوزه کلیدی ایجاد خواهد کرد.
تبدیل جستجو و تبلیغات مصرفکننده: انتظارات مصرفکننده به سرعت تغییر میکند. پس از پرسیدن یک درخواست باز از یک دستیار هوش مصنوعی یا دریافت پاسخ ساده بله/خیر، بازگشت به جستجوی مبتنی بر کلمه کلیدی و پیمایش صفحه پر از لینکها دردناک است. جستجوی مصرفکننده به زودی به طور کامل باز و چندوجهی در ورودیها و خروجیها خواهد بود.
شرکتهای بزرگ از طریق وسعت و مقیاس جستجوی عمومی، دادههای شخص اول (به عنوان مثال، Google Maps) و توزیع گسترده، برتری خود را حفظ خواهند کرد. اما اکوسیستم تبلیغات و سئو در اطراف آنها تغییر خواهد کرد.
وقتی نتیجه برای "بهترین کفشها کدامند؟" از یک سری پیوند به یک توصیه تولید شده تغییر میکند، شرکتهای کفشسازی به راههای جدیدی برای انجام سئو نیاز خواهند داشت. وقتی از یک دستیار میخواهید «برای آخر هفته برای من یک هتل رزرو کند»، برندهای هتل به رابطها/اپلتهایی نیاز خواهند داشت تا عامل در دسترس بودن را پرس و جو کند و کاربر به عکسهای گزینههای خود نگاه کند.
تکثیر جستجوی خاص دامنه و سازمانی: از آنجایی که ساخت جستجوی سنتی گرسنه داده، گران و پیچیده است، بیشتر ابزارهای جستجوی خاص دامنه و سازمانی عملکرد ضعیفی داشتهاند. در سراسر صنایع، استارتآپهای مبتنی بر LLM میتوانند سیستمهای قدیمی مانند LexisNexis، FactSet و PubMed را با خودکارسازی گردشهای کاری تحقیقاتی پیچیده مختل کنند. به عنوان مثال، در پزشکی، آنها میتوانند دهها آزمایش بالینی مرتبط را پیدا کنند، آنها را بر اساس معیارهای مطالعه فیلتر کنند و سپس یافتهها را ترکیب کنند.
LLMها همچنین باعث میشوند که جستجوی سازمانی در نهایت کار کند. Glean یک رهبر اولیه در جستجوی داخلی عمومی است، اما فرصتهای متعددی برای ساخت راهحلهای خاص گردش کار در اطراف سیستمهای اصلی سوابق (ERP، CRM، SIEM)، توابع (امنیت، عملیات، مالی) یا برنامههای کاربردی مشتری (جستجوی محصول) وجود دارد.
زیرساخت جدید برای خدمت به بازار جستجوی در حال انفجار: با ساخت جستجوی مبتنی بر LLM توسط شرکتهای بیشتر، تقاضای زیرساخت افزایش مییابد، از جمله در سیستمهای بازیابی برای سایر محصولات هوش مصنوعی (نگاه کنید به: بازیابی فقط جستجوست). زمینههای فرصت عبارتند از:
- پایگاههای داده و موتورهای پرس و جو - بهینهسازی شده برای جستجوی ترکیبی و چندوجهی، با توان عملیاتی بالا و بازیابی با تأخیر کم در مقیاس؛
- بازیابی اطلاعات عصبی - ابزار و مدلهایی برای پشتیبانی از تعبیه، فهرستبندی و بازیابی برای موارد استفاده مختلف (به عنوان مثال، شرکت پرتفوی Theory Ventures Superlinked). و
- هماهنگسازی جستجو - برنامهریزی و تجزیه پرس و جو، هماهنگسازی بازیابی چند مرحلهای، رتبهبندی/رتبهبندی مجدد، تأیید صحت و غیره.
تکامل جستجو در حال حاضر در جریان است، و اکنون بهترین لحظه برای استارتآپها برای ایجاد راهحلهایی است که نحوه دسترسی و استفاده از اطلاعات را در عصر مبتنی بر LLM بازتعریف میکنند.
اندی تریدمن شریک Theory Ventures است، جایی که او در شرکتهای هوش مصنوعی، داده و ML در مراحل اولیه سرمایهگذاری میکند. پیشینه او هم به عنوان اپراتور و هم سرمایهگذار است: او اولین مدیر محصول در Replica بود - یک استارتآپ تحت حمایت Founders Fund که محصولات داده مصنوعی را برای بخش دولتی ایجاد میکرد - و یک سرمایهگذار یادگیری ماشین در Innovation Endeavors. تریدمن کار خود را در Bain & Co. آغاز کرد و علوم اعصاب محاسباتی را در دانشگاه براون مطالعه کرد، جایی که رابطهای مغز و کامپیوتر را ساخت و الگوریتمهای یادگیری ماشین را روی دادههای عصبی آموزش داد.
تصویرسازی: Li-Anne Dias