
اینترنت اقیانوسی وسیع از دانش بشری است، اما بی نهایت نیست. و محققان هوش مصنوعی (AI) تقریباً آن را خشک کرده اند.
دهه گذشته بهبود انفجاری در هوش مصنوعی تا حد زیادی ناشی از بزرگتر کردن شبکه های عصبی و آموزش آنها بر روی داده های بیشتر بوده است. این مقیاس بندی به طرز شگفت انگیزی در ساخت مدلهای زبان بزرگ (LLM) - مانند مدلهایی که چتبات ChatGPT را تقویت میکنند - هم در تکرار زبان محاوره ای و هم در توسعه ویژگیهای نوظهوری مانند استدلال، مؤثر بوده است. اما برخی از متخصصان می گویند که ما اکنون به محدودیت های مقیاس بندی نزدیک می شویم. این تا حدی به دلیل نیازهای انرژی فزاینده برای محاسبات است. اما همچنین به این دلیل است که توسعه دهندگان LLM در حال تمام شدن مجموعه داده های مرسوم مورد استفاده برای آموزش مدل های خود هستند.
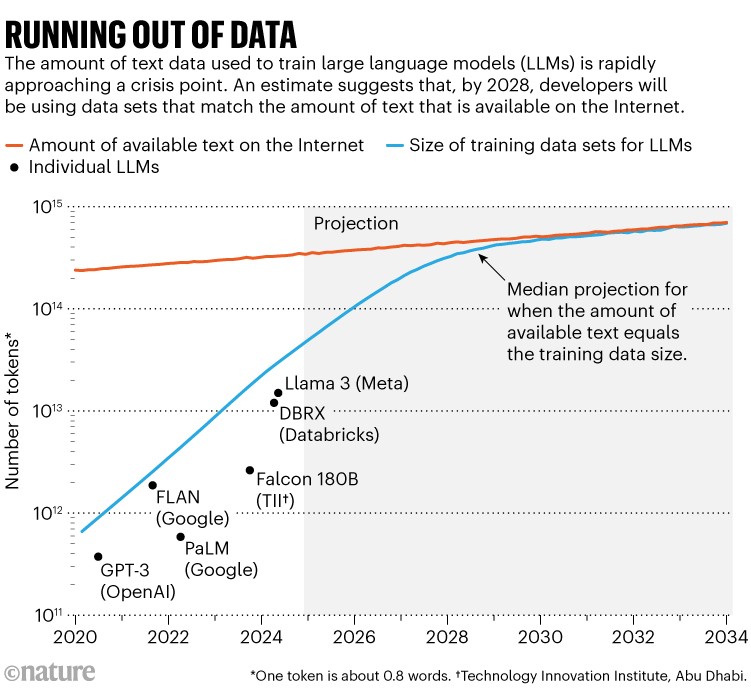
مطالعه برجسته ای1 با مطرح کردن عددی در این مشکل، تیتر خبرها را به خود اختصاص داد: محققان در Epoch AI، یک موسسه تحقیقاتی مجازی، پیشبینی کردند که تا حدود سال 2028، اندازه معمولی مجموعه داده مورد استفاده برای آموزش یک مدل هوش مصنوعی به همان اندازه کل سهام تخمینی متن آنلاین عمومی خواهد رسید. به عبارت دیگر، احتمالاً هوش مصنوعی در حدود چهار سال دیگر از داده های آموزشی خارج می شود (به "تمام شدن داده ها" مراجعه کنید). در همان زمان، صاحبان داده ها - مانند ناشران روزنامه ها - شروع به سرکوب نحوه استفاده از محتوای خود کرده اند و دسترسی را حتی بیشتر محدود می کنند. شین لانگپر، محقق هوش مصنوعی در موسسه فناوری ماساچوست در کمبریج که رهبری ابتکار منشأ داده، یک سازمان مردمی که ممیزی مجموعه داده های هوش مصنوعی را انجام می دهد، می گوید که این امر باعث ایجاد بحران در اندازه «مشترکات داده» می شود.
ممکن است تنگنای قریب الوقوع در داده های آموزشی شروع به فشار کند. لانگپر می گوید: "من قویاً مشکوک هستم که این اتفاق در حال حاضر در حال رخ دادن است."
اگرچه متخصصان می گویند این احتمال وجود دارد که این محدودیت ها ممکن است سرعت بهبود سریع در سیستم های هوش مصنوعی را کاهش دهد، اما توسعه دهندگان در حال یافتن راه حل هایی هستند. پابلو ویلالوبوس، محقق مستقر در مادرید در Epoch AI و نویسنده اصلی مطالعه پیش بینی سقوط داده ها در سال 2028، می گوید: "من فکر نمی کنم کسی در شرکت های بزرگ هوش مصنوعی وحشت زده باشد." "یا حداقل اگر هستند به من ایمیل نمی دهند."
به عنوان مثال، شرکت های برجسته هوش مصنوعی مانند OpenAI و Anthropic، هر دو در سانفرانسیسکو، کالیفرنیا، ضمن اشاره به اینکه برنامه هایی برای حل این مشکل دارند، از جمله تولید داده های جدید و یافتن منابع داده غیرمتعارف، به طور علنی این موضوع را پذیرفته اند. سخنگوی OpenAI به Nature گفت: «ما از منابع متعددی استفاده می کنیم، از جمله داده های عمومی در دسترس و مشارکت برای داده های غیرعمومی، تولید داده های مصنوعی و داده ها از مربیان هوش مصنوعی.»
با این وجود، بحران داده ممکن است باعث تحول در انواع مدل های هوش مصنوعی مولد شود که مردم می سازند و احتمالاً چشم انداز را از LLM های بزرگ و همه منظوره به مدل های کوچکتر و تخصصی تر تغییر دهد.
تریلیون ها کلمه
توسعه LLM در دهه گذشته اشتهای سیری ناپذیر خود را برای داده ها نشان داده است. اگرچه برخی از توسعه دهندگان مشخصات آخرین مدل های خود را منتشر نمی کنند، ویلالوبوس تخمین می زند که تعداد "توکن ها" یا بخش هایی از کلمات مورد استفاده برای آموزش LLM ها از سال 2020، از صدها میلیارد به ده ها تریلیون، 100 برابر افزایش یافته است.
این می تواند بخش خوبی از آنچه در اینترنت وجود دارد باشد، اگرچه کل آنقدر وسیع است که تعیین دقیق آن دشوار است - ویلالوبوس کل سهام اینترنتی داده های متنی را امروز 3100 تریلیون توکن تخمین می زند. سرویس های مختلف از خزنده های وب برای خراش دادن این محتوا استفاده می کنند، سپس موارد تکراری را حذف می کنند و محتوای نامطلوب (مانند هرزه نگاری) را فیلتر می کنند تا مجموعه داده های تمیزتری تولید کنند: یک مورد رایج به نام RedPajama حاوی ده ها تریلیون کلمه است. برخی از شرکت ها یا دانشگاهیان خود خزیدن و تمیز کردن را انجام می دهند تا مجموعه داده های سفارشی برای آموزش LLM ها ایجاد کنند. بخش کوچکی از اینترنت با کیفیت بالا در نظر گرفته می شود، مانند متن ویرایش شده توسط انسان و از نظر اجتماعی قابل قبول که ممکن است در کتاب ها یا روزنامه نگاری یافت شود.
نرخ افزایش محتوای اینترنتی قابل استفاده به طرز شگفت انگیزی کند است: مقاله ویلالوبوس تخمین می زند که کمتر از 10٪ در سال رشد می کند، در حالی که اندازه مجموعه داده های آموزشی هوش مصنوعی سالانه بیش از دو برابر می شود. پیش بینی این روندها نشان می دهد که خطوط در حدود سال 2028 به هم نزدیک می شوند.
در همان زمان، ارائه دهندگان محتوا به طور فزاینده ای کد نرم افزاری را شامل می شوند یا شرایط استفاده خود را برای جلوگیری از دسترسی خزنده های وب یا شرکت های هوش مصنوعی به داده های آنها برای آموزش اصلاح می کنند. لانگپر و همکارانش پیشنویسی را در ماه ژوئیه منتشر کردند که نشاندهنده افزایش شدید در تعداد ارائهدهندگان داده است که خزنده های خاصی را از دسترسی به وبسایتهای خود مسدود میکنند2. در باکیفیت ترین و پرکاربردترین محتوای وب در سه مجموعه داده اصلی پاکسازی شده، تعداد نشانه های محدود شده از خزنده ها از کمتر از 3 درصد در سال 2023 به 20 تا 33 درصد در سال 2024 افزایش یافته است.
در حال حاضر چندین دادخواست برای دریافت غرامت برای ارائه دهندگان داده هایی که در آموزش هوش مصنوعی استفاده می شوند، در جریان است. در دسامبر 2023، نیویورک تایمز از OpenAI و شریک آن مایکروسافت به دلیل نقض حق چاپ شکایت کرد. در آوریل سال جاری، هشت روزنامه متعلق به Alden Global Capital در شهر نیویورک به طور مشترک دادخواست مشابهی را ثبت کردند. استدلال متقابل این است که یک هوش مصنوعی باید اجازه داشته باشد از محتوای آنلاین به همان شیوه ای که یک فرد می خواند و یاد می گیرد، بخواند و بیاموزد و این استفاده منصفانه از این مطالب است. OpenAI به طور عمومی گفته است که فکر می کند دادخواست نیویورک تایمز "بی اساس" است.
اگر دادگاهها این ایده را تأیید کنند که ارائهدهندگان محتوا مستحق دریافت غرامت مالی هستند، دسترسی به آنچه که نیاز دارند، برای توسعهدهندگان و محققان هوش مصنوعی، از جمله دانشگاهیانی که جیبهای عمیقی ندارند، سختتر میشود. لانگپر می گوید: "دانشگاهیان بیشترین آسیب را از این معاملات خواهند دید." وی می افزاید: "بسیاری از مزایای بسیار اجتماعی و دموکراتیک داشتن یک وب باز وجود دارد."
یافتن داده ها
بحران داده یک مشکل بالقوه بزرگ برای استراتژی مرسوم مقیاس بندی هوش مصنوعی ایجاد می کند. اگرچه امکان افزایش قدرت محاسباتی یا تعداد پارامترهای یک مدل بدون افزایش داده های آموزشی وجود دارد، اما لانگپر می گوید که این امر باعث می شود هوش مصنوعی کند و گران شود - چیزی که معمولاً ترجیح داده نمی شود.
اگر هدف یافتن داده های بیشتر باشد، یک گزینه می تواند برداشت داده های غیرعمومی مانند پیام های واتس اپ یا رونوشت ویدیوهای یوتیوب باشد. اگرچه قانونی بودن خراش دادن محتوای شخص ثالث به این روش آزمایش نشده است، شرکت ها به داده های خود دسترسی دارند و چندین شرکت رسانه های اجتماعی می گویند که از مواد خود برای آموزش مدل های هوش مصنوعی خود استفاده می کنند. به عنوان مثال، متا در منلو پارک، کالیفرنیا می گوید که صدا و تصاویری که توسط هدست واقعیت مجازی متا کوئست جمع آوری شده است برای آموزش هوش مصنوعی آن استفاده می شود. با این حال، سیاست ها متفاوت است. شرایط خدمات پلتفرم کنفرانس ویدیویی زوم می گوید که این شرکت از محتوای مشتری برای آموزش سیستم های هوش مصنوعی استفاده نمی کند، در حالی که OtterAI، یک سرویس رونویسی، می گوید که از صداها و رونوشت های رمزگذاری شده و غیرمشخص برای آموزش استفاده می کند.
با این حال، در حال حاضر، چنین محتوای اختصاصی احتمالاً در مجموع فقط یک کوادریلیون نشانه متنی دارد، ویلالوبوس تخمین می زند. با توجه به اینکه بسیاری از این محتوا کم کیفیت یا تکراری است، او می گوید که این به اندازه کافی است که تنگنای داده ها را به مدت یک سال و نیم به تعویق بیندازد، حتی با فرض اینکه یک هوش مصنوعی بدون ایجاد نقض حق چاپ یا نگرانی های مربوط به حفظ حریم خصوصی به همه آن دسترسی پیدا کند. او میگوید: «حتی افزایش دهبرابری سهام دادهها تنها حدود سه سال مقیاسبندی را برای شما به ارمغان میآورد.»
گزینه دیگر ممکن است تمرکز بر مجموعه داده های تخصصی مانند داده های نجومی یا ژنومی باشد که به سرعت در حال رشد هستند. فی-فی لی، محقق برجسته هوش مصنوعی در دانشگاه استنفورد در کالیفرنیا، به طور علنی از این استراتژی حمایت کرده است. او در اجلاس فناوری بلومبرگ در ماه مه گفت که نگرانی ها در مورد تمام شدن داده ها دیدگاه بسیار محدودی از آنچه داده را تشکیل می دهد، با توجه به اطلاعات بکر موجود در زمینه هایی مانند مراقبت های بهداشتی، محیط زیست و آموزش، ارائه می دهد.
اما ویلالوبوس می گوید که مشخص نیست که چنین مجموعه داده هایی چقدر در دسترس یا مفید برای آموزش LLM ها خواهد بود. ویلالوبوس می گوید: "به نظر می رسد درجه ای از یادگیری انتقال بین انواع مختلف داده ها وجود دارد." "با این حال، من در مورد آن رویکرد بسیار امیدوار نیستم."
اگر هوش مصنوعی مولد نه فقط روی متن، بلکه روی انواع دیگر دادهها آموزش داده شود، احتمالات گستردهتر است. برخی از مدل ها در حال حاضر تا حدودی قادر به آموزش روی ویدیوها یا تصاویر بدون برچسب هستند. گسترش و بهبود چنین توانایی هایی می تواند دروازه ای به سوی داده های غنی تر باز کند.
یان لکون، دانشمند ارشد هوش مصنوعی در متا و دانشمند کامپیوتر در دانشگاه نیویورک که یکی از بنیانگذاران هوش مصنوعی مدرن محسوب می شود، در یک سخنرانی در فوریه امسال در یک نشست هوش مصنوعی در ونکوور کانادا، این احتمالات را برجسته کرد. 1013 نشانه مورد استفاده برای آموزش یک LLM مدرن زیاد به نظر می رسد: لکون محاسبه می کند که 170000 سال طول می کشد تا یک فرد این مقدار را بخواند. اما، به گفته او، یک کودک 4 ساله فقط با نگاه کردن به اشیاء در ساعات بیداری خود، حجمی از داده ها را 50 برابر بیشتر از این جذب کرده است. لکون این داده ها را در نشست سالانه انجمن پیشرفت هوش مصنوعی ارائه کرد.
مشابه این غنای داده ممکن است در نهایت با داشتن سیستم های هوش مصنوعی در فرم رباتیک که از تجربیات حسی خود یاد می گیرند مهار شود. لکون گفت: "ما هرگز با آموزش فقط روی زبان به هوش مصنوعی در سطح انسانی نخواهیم رسید، این اتفاق نمی افتد."
اگر داده ای یافت نشود، می توان بیشتر ساخت. برخی از شرکت های هوش مصنوعی به مردم برای تولید محتوا برای آموزش هوش مصنوعی پول می دهند. برخی دیگر از داده های مصنوعی تولید شده توسط هوش مصنوعی برای هوش مصنوعی استفاده می کنند. این یک منبع بالقوه عظیم است: در اوایل سال جاری، OpenAI گفت که روزانه 100 میلیارد کلمه تولید می کند - یعنی بیش از 36 تریلیون کلمه در سال، که تقریباً به اندازه مجموعه داده های آموزشی فعلی هوش مصنوعی است. و این خروجی به سرعت در حال رشد است.
به طور کلی، متخصصان موافق هستند که داده های مصنوعی برای رژیم هایی که در آن قوانین محکم و قابل شناسایی وجود دارد، مانند شطرنج، ریاضیات یا کدنویسی کامپیوتر، به خوبی کار می کنند. یک ابزار هوش مصنوعی، AlphaGeometry، با موفقیت برای حل مسائل هندسه با استفاده از 100 میلیون مثال مصنوعی و بدون نمایش انسانی آموزش داده شد3. داده های مصنوعی در حال حاضر در زمینه هایی استفاده می شود که داده های واقعی برای آنها محدود یا مشکل ساز است. این شامل دادههای پزشکی است، زیرا دادههای مصنوعی از نگرانیهای مربوط به حفظ حریم خصوصی عاری هستند، و زمینهای آموزشی برای خودروهای خودران، زیرا تصادفات مصنوعی خودرو به کسی آسیب نمیرساند.
مشکل داده های مصنوعی این است که حلقه های بازگشتی ممکن است دروغ ها را تثبیت کنند، تصورات غلط را بزرگ کنند و به طور کلی کیفیت یادگیری را کاهش دهند. یک مطالعه در سال 2023، عبارت اختلال خودخواری مدل را برای توصیف چگونگی «دیوانه شدن» یک مدل هوش مصنوعی به این روش ابداع کرد4. به عنوان مثال، یک مدل هوش مصنوعی تولید کننده چهره که تا حدی بر اساس داده های مصنوعی آموزش دیده است، شروع به ترسیم چهره هایی با علامت های هش عجیب و غریب کرد.
بیشتر با کمتر
استراتژی جایگزین، رها کردن مفهوم "بزرگتر بهتر است" است. اگرچه توسعه دهندگان به ساخت مدل های بزرگتر و تکیه بر مقیاس بندی برای بهبود LLM های خود ادامه می دهند، بسیاری از آنها به دنبال مدل های کارآمدتر و کوچکتر هستند که بر روی وظایف فردی تمرکز دارند. اینها به داده های تخصصی تصفیه شده و تکنیک های آموزشی بهتری نیاز دارند.
به طور کلی، تلاش های هوش مصنوعی در حال حاضر با کمتر کار بیشتری انجام می دهند. یک مطالعه در سال 2024 نتیجه گرفت که به دلیل پیشرفت در الگوریتم ها، قدرت محاسباتی مورد نیاز برای رسیدن یک LLM به همان عملکرد، هر هشت ماه یا بیشتر نصف شده است5.
این، همراه با تراشه های کامپیوتری تخصصی برای هوش مصنوعی و سایر پیشرفت های سخت افزاری، در را برای استفاده متفاوت از منابع محاسباتی باز می کند: یک استراتژی این است که یک مدل هوش مصنوعی چندین بار مجموعه داده های آموزشی خود را دوباره بخواند. اگرچه بسیاری از مردم فرض می کنند که یک کامپیوتر حافظه کاملی دارد و فقط باید یک بار مطالب را "بخواند"، سیستم های هوش مصنوعی به شیوه ای آماری کار می کنند که به این معنی است که خواندن مجدد عملکرد را افزایش می دهد، نیکلاس موینینگوف، دانشجوی دکترا در دانشگاه استنفورد و عضوی از ابتکار منشا داده ها می گوید. در مقاله ای که در سال 2023 در حالی که در شرکت هوش مصنوعی HuggingFace در شهر نیویورک بود منتشر شد، او و همکارانش نشان دادند که یک مدل به همان اندازه از خواندن مجدد یک مجموعه داده معین چهار بار یاد گرفته است که از خواندن همان مقدار داده منحصر به فرد - اگرچه فواید خواندن مجدد پس از آن به سرعت کاهش یافت6.
اگرچه OpenAI اطلاعاتی در مورد اندازه مدل یا مجموعه داده های آموزشی خود برای آخرین LLM خود، o1، فاش نکرده است، اما این شرکت تأکید کرده است که این مدل به یک رویکرد جدید تکیه می کند: صرف زمان بیشتر برای یادگیری تقویتی (فرآیندی که مدل در آن بازخورد دریافت می کند. در مورد بهترین پاسخ های خود) و زمان بیشتری را صرف فکر کردن در مورد هر پاسخ. ناظران می گویند این مدل تأکید را از پیش آموزش با مجموعه داده های عظیم دور می کند و بیشتر به آموزش و استنتاج متکی است. لانگپر می گوید که این امر بعد جدیدی به رویکردهای مقیاس بندی اضافه می کند، اگرچه این یک استراتژی پرهزینه محاسباتی است.
این احتمال وجود دارد که LLM ها پس از خواندن بیشتر اینترنت، دیگر برای باهوش تر شدن به داده های بیشتری نیاز نداشته باشند. اندی زو، دانشجوی فارغ التحصیل در دانشگاه کارنگی ملون در پیتسبورگ، پنسیلوانیا، که در زمینه امنیت هوش مصنوعی مطالعه می کند، می گوید که پیشرفت ها ممکن است به زودی از طریق خوداندیشی توسط یک هوش مصنوعی حاصل شود. زو میگوید: «اکنون یک پایگاه دانش بنیادی دارد که احتمالاً بیشتر از هر فردی است». "من فکر می کنم ما احتمالاً خیلی به آن نقطه نزدیک هستیم."
ویلالوبوس فکر می کند که همه این عوامل - از داده های مصنوعی گرفته تا مجموعه داده های تخصصی، خواندن مجدد و خوداندیشی - کمک خواهد کرد. "ترکیبی از مدل هایی که می توانند خودشان فکر کنند و بتوانند به روش های مختلف با دنیای واقعی تعامل داشته باشند - احتمالاً مرز را پیش می برد."