
مدلهای زبانی بزرگ (LLM) از منابع محاسباتی گستردهای برای پردازش و تولید متن شبیه انسان استفاده میکنند. یکی از تکنیکهای نوظهور برای افزایش قابلیتهای استدلال در LLMها، مقیاسبندی زمان آزمایش است که به صورت پویا منابع محاسباتی را در طول استنتاج تخصیص میدهد. هدف این رویکرد بهبود دقت پاسخها با پالایش فرآیند استدلال مدل است. با معرفی مقیاسبندی زمان آزمایش توسط مدلهایی مانند سری o1 OpenAI، محققان به دنبال درک این موضوع بودند که آیا زنجیرههای استدلال طولانیتر منجر به بهبود عملکرد میشوند یا استراتژیهای جایگزین میتوانند نتایج بهتری به دست آورند.
مقیاسبندی استدلال در مدلهای هوش مصنوعی چالش قابل توجهی است، به ویژه در مواردی که زنجیرههای فکری طولانیتر لزوماً به نتایج بهتری منجر نمیشوند. این فرضیه که افزایش طول پاسخها دقت را افزایش میدهد، توسط محققانی مورد سوال قرار گرفته است که دریافتهاند توضیحات طولانیتر میتوانند تناقضاتی را ایجاد کنند. خطاها در طول زنجیرههای استدلال طولانی انباشته میشوند و مدلها اغلب بازبینیهای غیرضروری انجام میدهند که منجر به کاهش عملکرد به جای بهبود آن میشود. اگر مقیاسبندی زمان آزمایش یک راه حل مؤثر باشد، باید عمق استدلال را با دقت متعادل کند و اطمینان حاصل کند که منابع محاسباتی به طور کارآمد و بدون کاهش اثربخشی مدل استفاده میشوند.
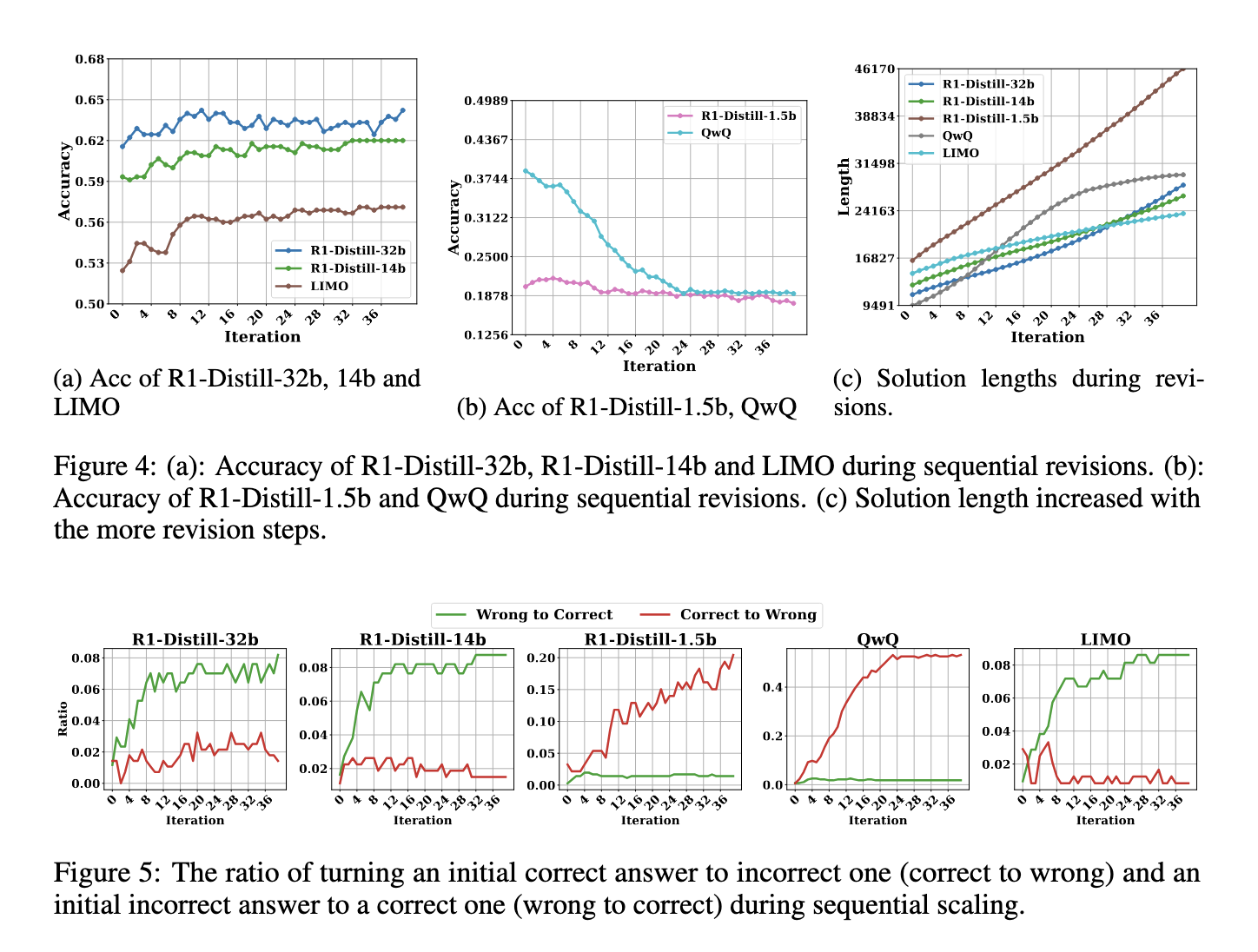
رویکردهای فعلی به مقیاسبندی زمان آزمایش عمدتاً به دو دسته ترتیبی و موازی تقسیم میشوند. مقیاسبندی ترتیبی زنجیره فکر (CoT) را در طول استنتاج گسترش میدهد، با این انتظار که استدلال طولانیتر منجر به بهبود دقت شود. با این حال، مطالعات بر روی مدلهایی مانند QwQ، Deepseek-R1 (R1) و LIMO نشان میدهد که گسترش CoTها به طور مداوم نتایج بهتری به دست نمیدهد. این مدلها اغلب از خودبازبینی استفاده میکنند و محاسبات اضافی را معرفی میکنند که عملکرد را کاهش میدهد. در مقابل، مقیاسبندی موازی چندین راه حل را به طور همزمان تولید میکند و بهترین راه حل را بر اساس یک معیار از پیش تعیین شده انتخاب میکند. تجزیه و تحلیلهای تطبیقی نشان میدهد که مقیاسبندی موازی در حفظ دقت و کارایی مؤثرتر است.
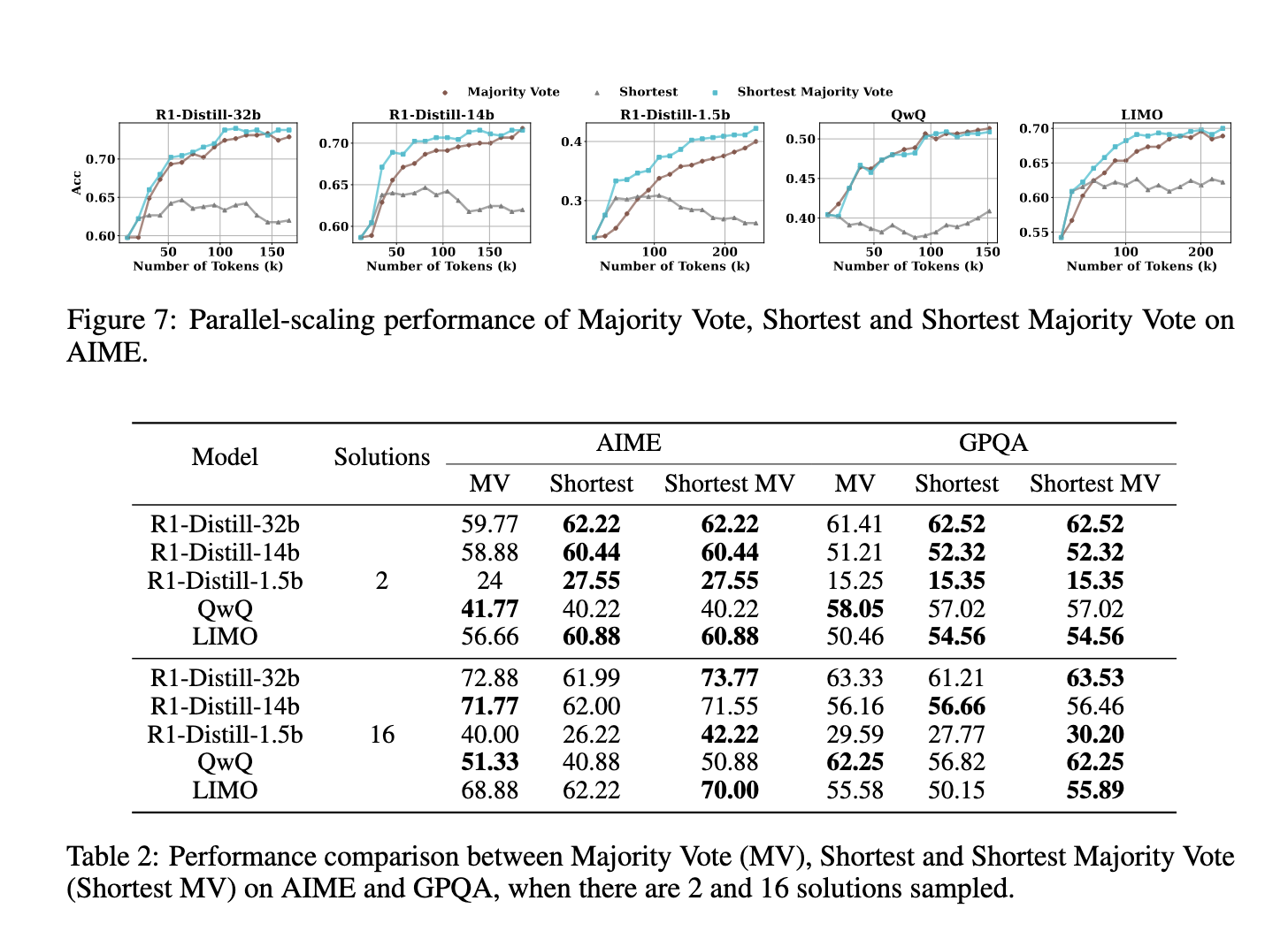
محققان دانشگاه فودان و آزمایشگاه هوش مصنوعی شانگهای یک روش نوآورانه به نام "رای اکثریت کوتاهترین" را برای رفع محدودیتهای مقیاسبندی ترتیبی معرفی کردند. این روش مقیاسبندی زمان آزمایش را با استفاده از محاسبات موازی و در نظر گرفتن طول راه حل بهینه میکند. بینش اصلی پشت این رویکرد این است که راه حلهای کوتاهتر نسبت به راه حلهای طولانیتر دقیقتر هستند، زیرا حاوی بازبینیهای غیرضروری کمتری هستند. این روش با گنجاندن طول راه حل در فرآیند رای اکثریت، عملکرد مدلها را با اولویتبندی پاسخهای مکرر و مختصر افزایش میدهد.
روش پیشنهادی رای اکثریت سنتی را با در نظر گرفتن تعداد و طول راه حلها تغییر میدهد. رای اکثریت مرسوم، پاسخی را انتخاب میکند که بیشترین تکرار را در بین راه حلهای تولید شده داشته باشد، در حالی که رای اکثریت کوتاهترین، اولویت بیشتری را به پاسخهایی میدهد که اغلب ظاهر میشوند اما کوتاهتر نیز هستند. استدلال پشت این رویکرد این است که راه حلهای طولانیتر به دلیل خودبازبینیهای بیش از حد، خطاهای بیشتری را معرفی میکنند. محققان دریافتند که QwQ، R1 و LIMO هنگام درخواست برای پالایش راه حلهای خود، پاسخهای طولانیتری تولید میکنند که اغلب منجر به کاهش دقت میشود. روش پیشنهادی با ادغام طول به عنوان یک معیار، هدفش فیلتر کردن افزونههای غیرضروری و اولویتبندی پاسخهای دقیقتر است.
ارزیابیهای تجربی نشان داد که روش رای اکثریت کوتاهترین به طور قابل توجهی عملکرد بهتری نسبت به رای اکثریت سنتی در چندین معیار داشته است. در مجموعه داده AIME، مدلهای دارای این تکنیک در مقایسه با رویکردهای مقیاسبندی زمان آزمایش موجود، افزایش دقت را نشان دادند. به عنوان مثال، در R1-Distill-32b، بهبود دقت مشاهده شد که به 72.88٪ در مقایسه با روشهای مرسوم رسید. به طور مشابه، QwQ و LIMO نیز عملکرد بهتری را نشان دادند، به ویژه در مواردی که زنجیرههای استدلال طولانی قبلاً منجر به ناسازگاری شده بودند. این یافتهها نشان میدهد که این فرضیه که راه حلهای طولانیتر همیشه نتایج بهتری به دست میدهند، ناقص است. در عوض، یک رویکرد ساختاریافته و کارآمد که مختصر بودن را اولویتبندی میکند، میتواند منجر به عملکرد برتر شود.
نتایج همچنین نشان داد که مقیاسبندی ترتیبی از بازده کاهشی رنج میبرد. در حالی که بازبینیهای اولیه ممکن است به پاسخهای بهبود یافته کمک کنند، بازبینیهای بیش از حد اغلب به جای اصلاح آنها، خطاها را وارد میکنند. به طور خاص، مدلهایی مانند QwQ و R1-Distill-1.5b تمایل داشتند پاسخهای صحیح را به پاسخهای نادرست تبدیل کنند تا اینکه دقت را بهبود بخشند. این پدیده بیشتر محدودیتهای مقیاسبندی ترتیبی را برجسته میکند و این استدلال را تقویت میکند که یک رویکرد ساختاریافتهتر، مانند رای اکثریت کوتاهترین، برای بهینهسازی مقیاسبندی زمان آزمایش ضروری است.
این تحقیق بر نیاز به بازنگری در نحوه استفاده از مقیاسبندی زمان آزمایش در مدلهای زبانی بزرگ تأکید میکند. یافتهها نشان میدهد که به جای فرض اینکه گسترش زنجیرههای استدلال منجر به دقت بهتر میشود، اولویتبندی راه حلهای مختصر و با کیفیت بالا از طریق مقیاسبندی موازی یک استراتژی مؤثرتر است. معرفی رای اکثریت کوتاهترین، یک بهبود عملی و معتبر تجربی را نسبت به روشهای موجود ارائه میدهد و یک رویکرد پالایش شده برای بهینهسازی کارایی محاسباتی در LLMها ارائه میدهد.
مقاله را بررسی کنید: Paper. تمام اعتبار این تحقیق به محققان این پروژه میرسد. همچنین، ما را در توییتر دنبال کنید و فراموش نکنید که به 75k+ ML SubReddit ما بپیوندید.